
- Aula 01 - Introdução
- Aula 02 - SOAR: Tutorial 1
- Aula 03 - SOAR: Tutorial 2
- Aula 04 - SOAR: Tutorial 3
- Aula 05 - SOAR: Tutoriais 4 e 5
- Aula 06 - SOAR: Tutoriais 7,8 e 9
- Aula 07 - SOAR: Controlando o WorldServer3D
- Aula 08 e Aula 09 - Clarion 1,2
- Aula 10 e Aula 11 - Clarion: Controlando o WorldServer3D
- Aula 12 - LIDA 1: Entendendo a Arquitetura
- Aula 13 - LIDA 2: Exemplos de Implementação Prática
- Aula 14 e Aula 15 - Projeto
You are here
Atividade 2
Memória Semântica
A memória semântica do SOAR (SMem) é um mecanismo que permite a um agente, deliberadamente, armazenar e recuperar objetos que serão persistidos. Esse tipo de informação semântica irá complementar as informações contidas na memória de curta duração e em outras memórias de longa duração, tais como as regras da memória procedural.
Armazenamento Semântico
Pode-se armazenar um conhecimento (semântico), manualmente, na memória do SOAR. Basta executar o comando smem --add { (<knowledge 'A'>) (<knowledge 'B'>) ... }, onde <knowledge> representa a informação que será armazenada na memória semântica do SOAR. Também é possível visualizar o conhecimento armazenado por meio do seguinte comando: smem --print. A figura abaixo exibe a tela do SOAR Debugger, após serem executados os comandos descritos anteriormente:

As variáveis adicionadas (<a>, <b>, <c>) foram instanciadas como identificadores específicos (@A1, @B1, @C3). Esses identificadores, precedidos pelo símbolo "@", são persistidos na memória semântica do SOAR; sendo chamados de LTI's (long-term identifiers), identificadores de longa duração, em contraste aos outros identificadores de curta duração. Os números, entre colchetes ("[]"), que seguem cada identificador, são valores relacionados a recuperação desses objetos (tópico que será discutido posteriormente). Diferentemente da memória de trabalho, e das regras, o conhecimento semântico não precisa ser conectado (direta ou indiretamente) ao estado inicial.
Para imprimir, graficamente, o conteúdo da memória semântica do SOAR, pode-se usar o comando: command-to-file smem.gv smem --viz. O resultado será a criação de um arquivo (smem.gv) que contém a estrutura formada pelos elementos da memória semântica. O comando print --depth 100 <s> exibe o conteúdo das memórias de trabalho e procedural. Comparando-se os resultados obtidos pelos comandos anteriores, pode-se constatar que o conhecimento semântico não está presente em nenhuma das outras memórias do agente. A figura abaixo exibe os resultados da execução desses comandos:
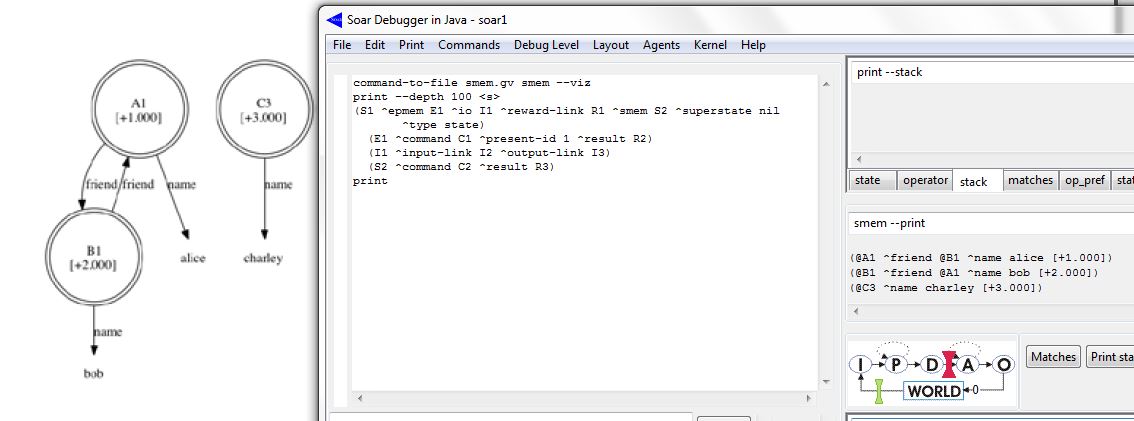
Conforme a figura acima, o conhecimento semântico (gráfico) é independente e não aparece nas outras memórias do SOAR (conforme a tela do SOAR Debugger acima). Assim, o agente pode acessar e modificar o conteúdo semântico a qualquer momento que precisar fazê-lo, independente das informações persistidas (ou não) nas outras memórias do agente. O comando smem --init limpa o conteúdo da memória semântica, apagando todas as informações armazenadas nela.
Interação entre Agente e Memória Semântica
O agente interage com a memória semântica por meio de uma estrutura especial (smem link) criada na memória de trabalho do SOAR. Essa estrutura, smem, é criada no estado inicial e possui sub-estruturas especializadas para se comunicar com o agente. O atributo ^command é usado para enviar comandos, do agente, para serem executados na memória semântica. O atributo ^result recupera as informações da memória semântica do agente. O comando print --depth 100 <s> exibe a estrutura do estado (<s>), onde pode-se visualizar a existência da estrutura (^smem) relacionada à memória semântica:
(S1 ^epmem E1 ^io I1 ^reward-link R1 ^smem S2 ^superstate nil ^type state)
(E1 ^command C1 ^present-id 1 ^result R2)
(I1 ^input-link I2 ^output-link I3)
(S2 ^command C2 ^result R3)
Imprimindo-se a estrutura ^smem (print s2) pode-se visualizar seus atributos: S2 ^command C2 ^result R3. O agente irá, por meio de regras, preencher e manter o link command, e a arquitetura preencherá e limpará o link result. Para que o agente possa interagir com a memória semântica, o mecanismo associado ao aprendizado semântico deve ser habilitado. Basta usar o seguinte comando para habilitar o uso da memória semântica: smem --set learning on.
Armazenamento e Modificação pelo Agente
O agente armazena um objeto, na memória semântica, enviando um comando do tipo store, no link command do estado inicial. Esse comando deve ser seguido pelos objetos (identificadores) que se deseja armazenar na memória semântica. Um agente pode enviar múltiplos comandos store simultâneamente. Após receber todos os comandos enviados, a arquitetura gera uma resposta de "sucesso" na forma de um WME (^success) criado no link result do estado inicial. Essa resposta será seguida por um valor associado ao comando que foi enviado.
O comando store armazena os identificadores e qualquer argumento associado a esses identificadores. Caso esses identificadores não sejam elementos de longa duração, o SOAR converte-os em identificadores de longa duração. O programa smem-tutorial.soar exemplifica o uso da memória semântica do SOAR. A figura abaixo exibe as regras que armazenam informações na memória semântica e, em seguida, modificam as informações armazenadas:

As regras da figura acima propõem e aplicam dois operadores: init e mod. O operador init armazena três objetos (<a>, <b>, <c>) na memória semântica do SOAR, por meio do comando store (<cmd> ^store <a> <b> <c>). Esses identificadores possuem argumentos associados a eles (<a> ^name alice ^friend <b>) que também serão armazenados. O operador mod irá modificar os objetos que foram armazenados na memória semântica. Esse operador remove alguns comandos (store) enviados para a memória semântica (<cmd> ^store <b> -) e altera as informações gravadas (<a> ^name alice -) de outro objeto armazenado (<a> ^name anna ^friend <c>). Rodando-se esse programa no SOAR Debugger, após o operador init ter sido proposto e selecionado, obteve-se o seguinte resultado exibido na figura abaixo:
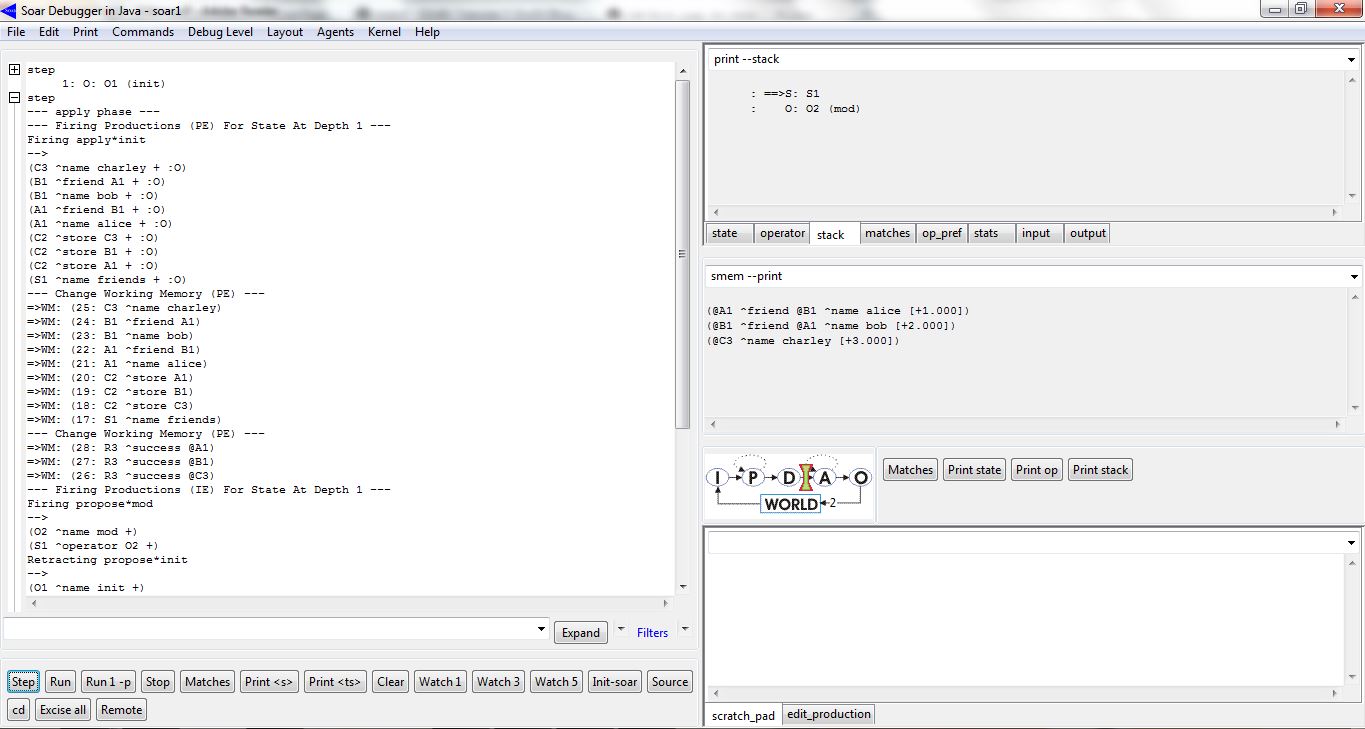
Pode-se visualizar a criação de três identificadores (A1, B1, C3), e seus argumentos, na memória de trabalho do SOAR. Esses identificadores são, inicialmente, elementos de curta duração. No final da fase de elaboração, a memória semântica processa os comandos enviados (store), convertendo os elementos criados na memória de trabalho em identificadores de longa duração (@A1, @B1, @C3) e devolvendo uma resposta de sucesso (success). Pode-se visualizar o conteúdo da memória semântica, na parte direita da figura acima, exibido pelo comando smem --print. A figura abaixo exibe o resultado da aplicação do operador mod:

O operador mod modifica o conteúdo da memória semântica, sobrescrevendo o conteúdo do identificador de longa duração (@A1) existente na memória semântica. Os comandos store para @B1 e @C3 foram removidos (<=WM: (26: R3 ^success @C3)) pela aplicação da regra. Os argumentos de @A1 foram removidos e adicionados. Pode-se visualizar o conteúdo da memória semântica (smem --print), após as alterações realizadas, na parte direita da figura acima. Nota-se que o conteúdo de @A1 foi realmente alterado, e os conteúdos de @B1 e @C3 permanecem inalterados.
Non-Cue-Based (NCB) Retrieval
A primeira forma que um agente pode usar para recuperar o conhecimento armazenado na memória semântica é chamada de non-cue-based retrieval. O agente recupera, da memória semântica, todos os argumentos associados a um identificador de longa duração conhecido. O comando retrieve, do link command, recupera as informações de um identificador (que segue o comando). A figura abaixo exibe as regras responsáveis por essa operação:
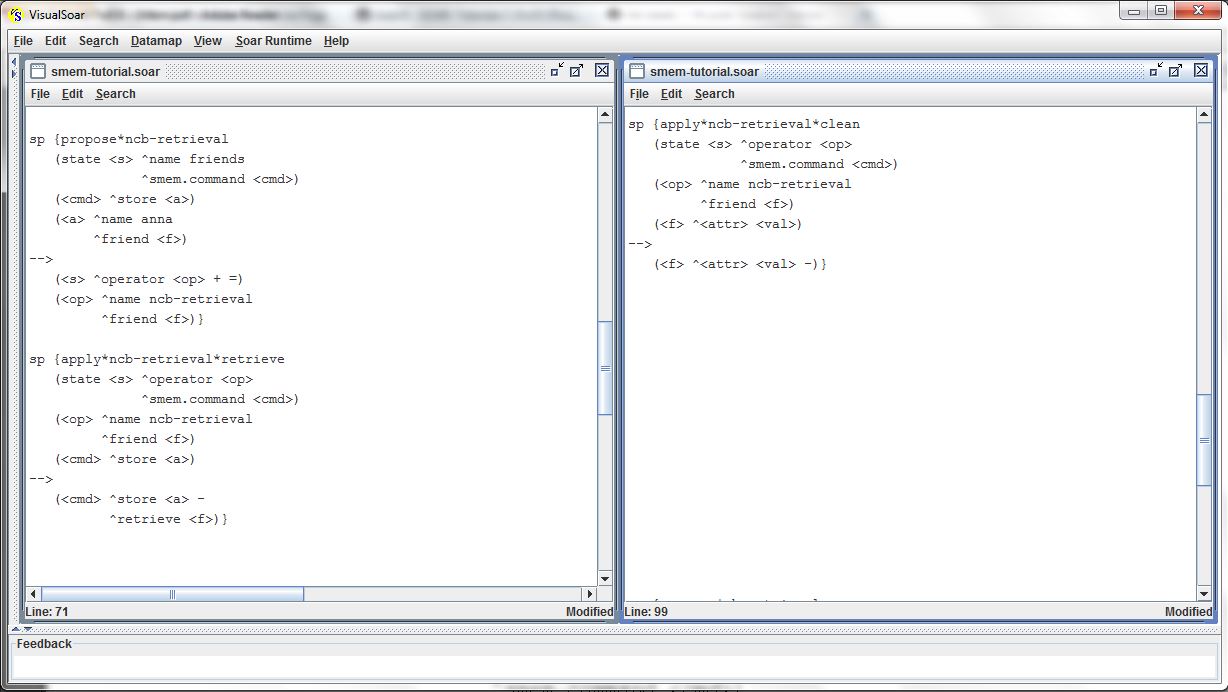
As regras recuperam as informações sobre os amigos de @A1 (<a> ^name anna ^friend <f>), mas, selecionam apenas um desses amigos (<op> ^name ncb-retrieval ^friend <f>) que será escolhido aleatóriamente. Em seguida, remove os argumentos referentes ao identificador (^friend <f>) recuperado, da memória de trabalho (apply*ncb-retrieval*clean). Diferente dos comandos store, os comandos ^retrieve são processados na fase de saída e apenas um comando pode ser executado a cada decisão. A figura abaixo exibe o resultado da aplicação das regras da figura acima:

Apenas um dos dois operadores ncb-retrieval propostos foi selecionado (O4 ^friend @B1 +). Após aplicar este operador, os argumentos referentes ao identificador selecionado foram removidos (<=WM: (37: O4 ^friend @B1)) da memória de trabalho. O comando print --depth 100 s2 imprime o conteúdo do link smem. Pode-se visualizar essas informações na parte inferior direita da tela da figura acima. O comando retrieve retornou o conteúdo do identificador @B1 (@B1 ^friend @A1 ^name bob), adicionando-o na memória de trabalho (=>WM: (47: R3 ^retrieved @B1)). Também foi retornada uma mensagem de sucesso (R3 ^retrieved @B1 ^success @B1).
Cue-Based (CB) Retrieval
A outra forma pela qual um agente pode recuperar o conteúdo armazenado na memória semântica é chamada de cue-based retrieval. O agente recupera, da memória semântica, todos os argumentos de um identificador de longa duração desconhecido, que é descrito por um sub-conjunto de seus argumentos. O comando query, do link command, recupera as informações de um identificador cujos argumentos (cue) desejados referem-se a esse identificador. A figura abaixo exibe as regras responsáveis por essa operação:
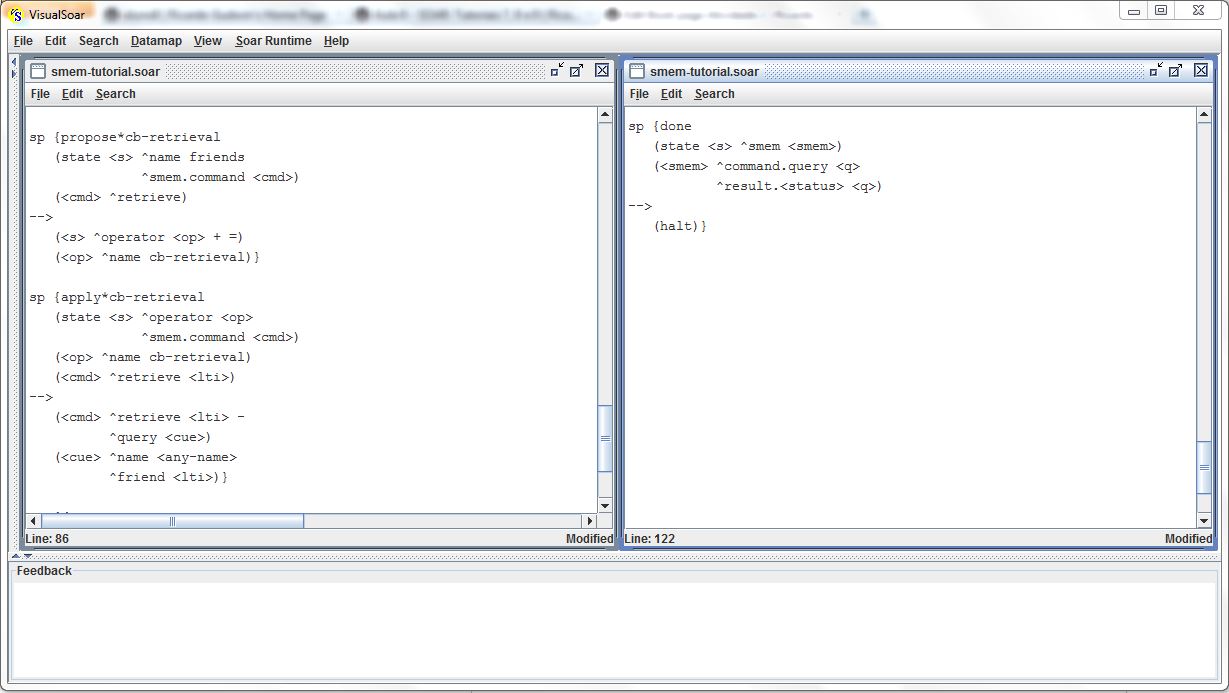
As regras da figura acima recuperam um identificador que satisfaça duas condições: possuir um atributo ^name e também um atributo ^friend. Conforme observado anteriormente, os comandos ^retrieve são processados apenas na fase de saída do agente, e apenas um comando será executado por decisão. A figura abaixo exibe o resultado da aplicação das regras da figura acima:

Foi retornado o identificador @A1 que possui argumentos ^friend e ^name. Se não houvesse nenhum identificador que atendesse às condições requisitadas, seria retornada uma resposta de falha. Caso haja mais de um identificador que satisfaça as condições desejadas, aquele identificador de maior valor (@A1 ^friend @B1 @C3 ^name anna [+6.000]) associado será retornado. Esse valor é um número inteiro ([+6.000]) associado ao identificador.
Theme by Danetsoft and Danang Probo Sayekti inspired by Maksimer