
- Aula 01 - Introdução
- Aula 02 - SOAR: Tutorial 1
- Aula 03 - SOAR: Tutorial 2
- Aula 04 - SOAR: Tutorial 3
- Aula 05 - SOAR: Tutoriais 4 e 5
- Aula 06 - SOAR: Tutoriais 7,8 e 9
- Aula 07 - SOAR: Controlando o WorldServer3D
- Aula 08 e Aula 09 - Clarion 1,2
- Aula 10 e Aula 11 - Clarion: Controlando o WorldServer3D
- Aula 12 - LIDA 1: Entendendo a Arquitetura
- Aula 13 - LIDA 2: Exemplos de Implementação Prática
- Aula 14 e Aula 15 - Projeto
You are here
Atividade 1
Reinforcement Learning
O Reinforcement Learning do SOAR permite aos agentes alterar seu comportamento, ao longo do tempo, por meio da alteração das preferências indiferentes numéricas, na memória procedural, em resposta a um sinal de recompensa. As preferências indiferentes (=) à seleção dos operadores determinam que a escolha de um operador será aleatória. Alterando-se alguns parâmetros, numericamente, das preferências indiferentes, pode-se alterar a preferência pela escolha de um operador em particular. Isso será realizado em tempo de execução do programa SOAR. Este procedimento difere do mecanismo de chunking estudado anteriormente. O chunking é um tipo de aprendizado que aumenta a performance de um agente, resumindo (em novas regras) os resultados das metas alcançadas nos sub-estados do problema. O Reinforcement Learning é uma forma incremental de aprendizado que altera probabilisticamente o comportamento do agente.
Agente Left-Right
O agente left-right é um agente simples que apenas escolhe entre se mover para direita (right) ou para a esquerda (left). Uma direção será preferida em detrimento da outra. Depois de decidir seu destino, o agente receberá uma recompensa ou alguma informação a respeito de quão boa foi aquela decisão tomada. Neste caso, a recompensa será um valor -1 para left e um valor +1 para right. Usando o Reinforcement Learning (RL) o agente aprenderá rapidamente que a melhor escolha será right.
O agente left-right possui um operador move que escolhe entre mover para esquerda ou direita. Visto que o agente não possui um conhecimento a priori sobre para qual direção se mover, essa decisão será aleatória, implementada por uma preferência indiferente pelas duas direções. As próximas figuras exibem os operadores initialize-left-right e move:
Operador initialize-left-right:

Operador move:
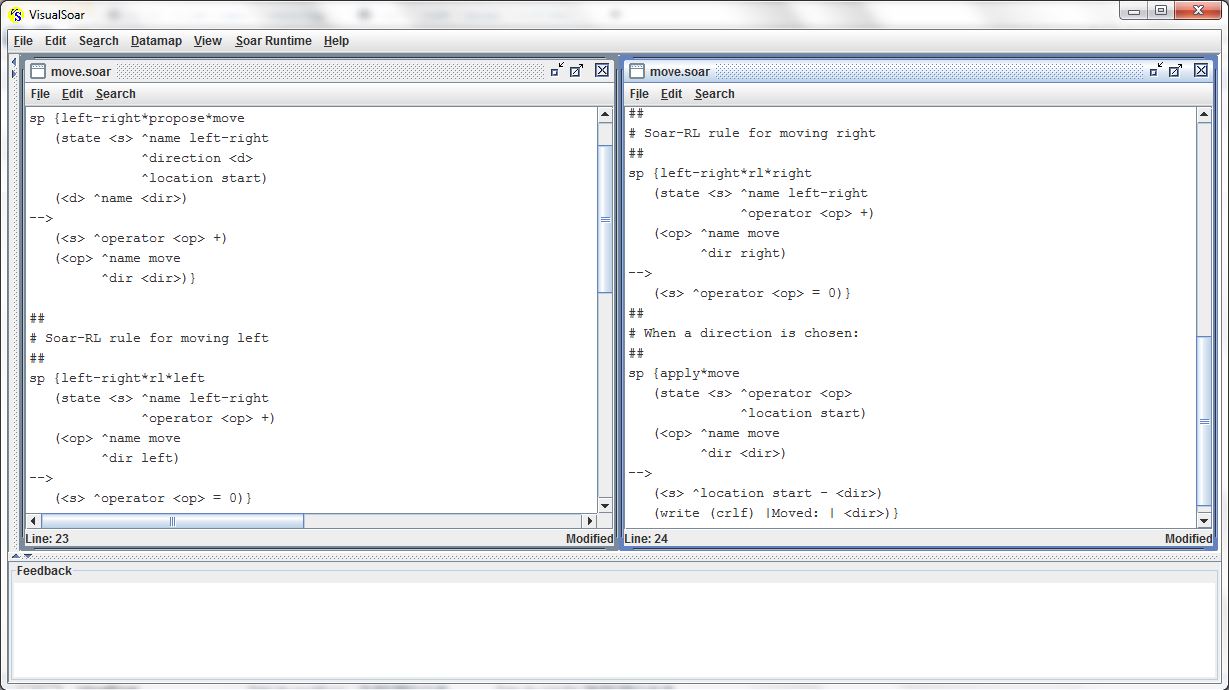
A regra apply*initialize-left-right cria as duas direções no estado inicial (^direction <d1> <d2>) e associa uma recompensa a cada uma das direções (<d1> ^name left ^reward -1, <d2> ^name right ^reward 1). A regra left-right*propose*move propõe o operador move em ambas direções (<d> ^name <dir>) criadas no estado inicial. A regra apply*move armazena a direção escolhida no estado inicial (<s> ^location start - <dir>). A figura abaixo exibe a regra que elabora uma recompensa para o movimento efetuado pelo agente, e a regra que suspendem (halt) o agente após este efetuar um movimento:
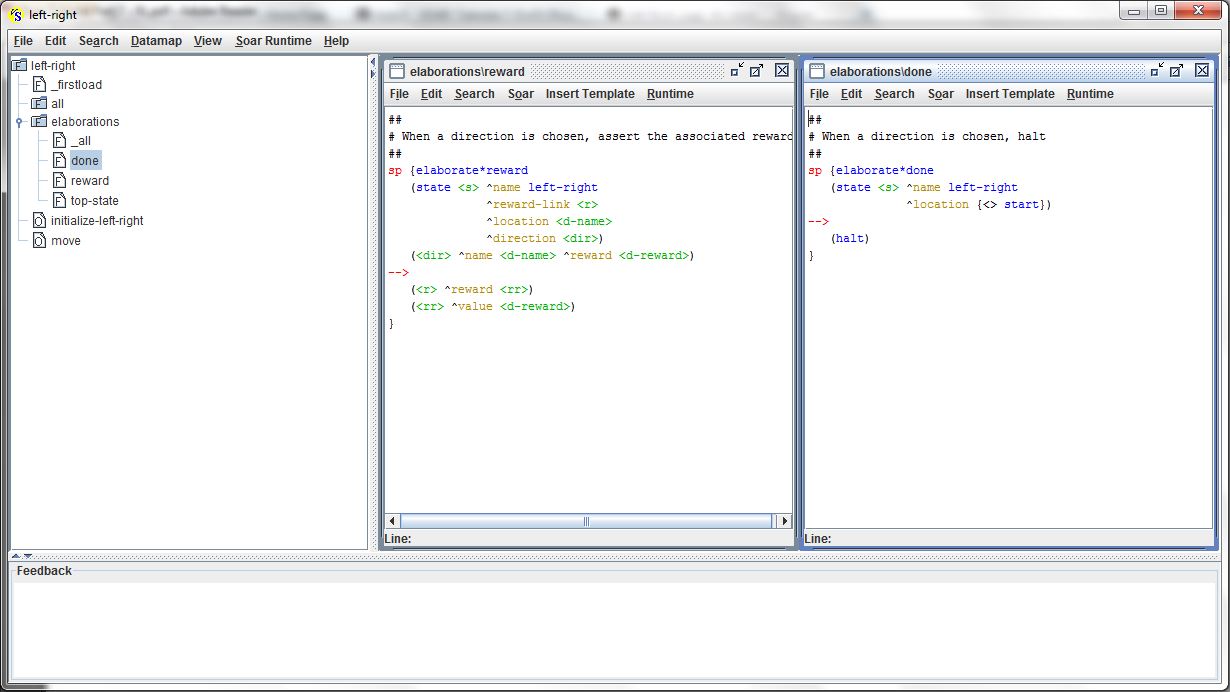
Quando o agente escolhe uma direção, ele recebe uma recompensa (<dir> ^name <d-name> ^reward <d-reward>). Algumas regras (RL rules), para o operador move, participam do mecanismo de aprendizado do agente (essas regras serão detalhadas adiante). As próximas figuras exibem os resultados, telas do SOAR Debugger, da execução deste agente:
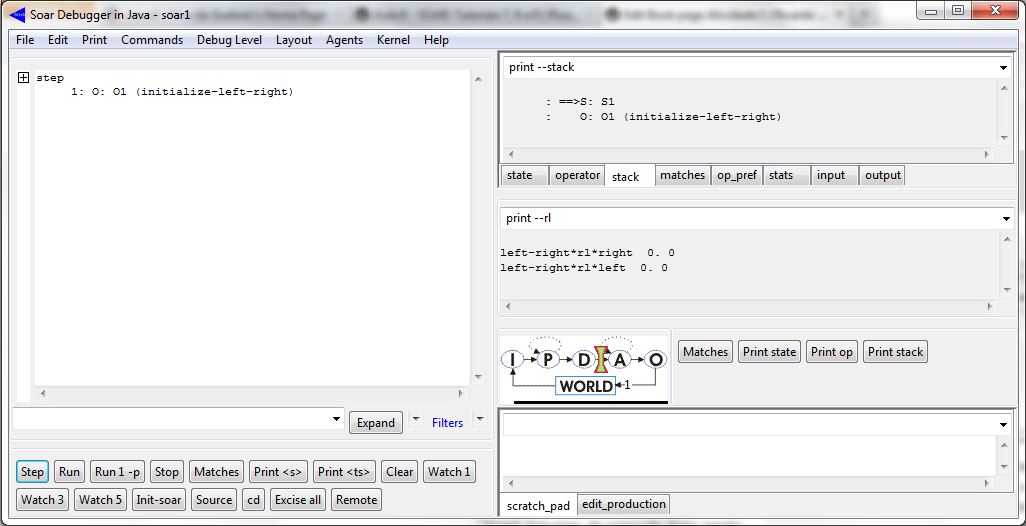
Agente inicializado:
Operador move aplicado:
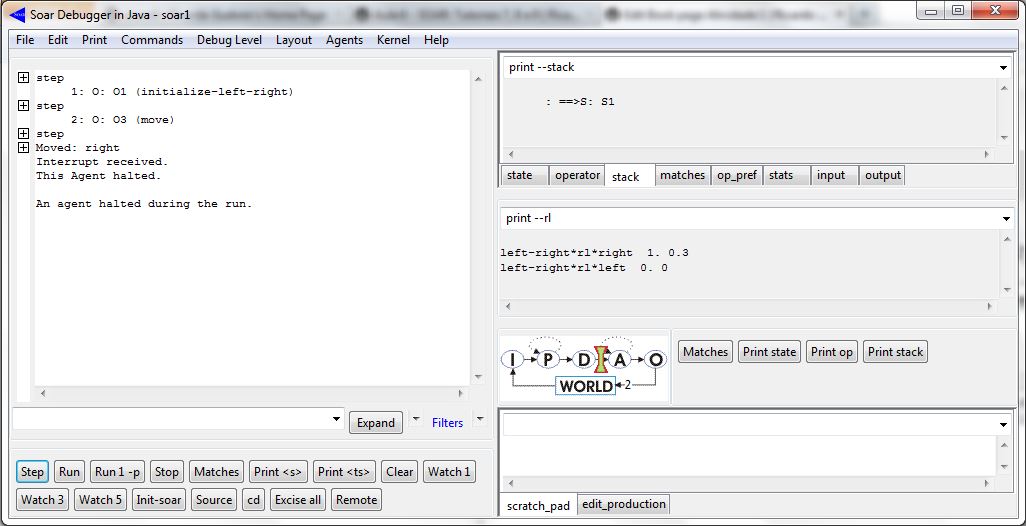
Resultado após rodar o agente várias vezes:

Antes de executar o agente, e obter os resultados exibidos nas telas acima, é necessário habilitar o mecanismo de Reinforcement Learning (RL) do SOAR. Para isso, basta acrecentar, no arquivo _firstload, os seguintes comandos: rl --set learning on e indifferent-selection --epsilon-greedy. O primeiro comando habilita o mecanismo de RL do SOAR. O segundo comando será discutido posteriormente. Para visualizar os resultados da atuação do mecanismo de RL, basta digitar o seguinte comando no SOAR Debugger: print --rl. Inicialmente, quando o agente foi inicializado, não há preferências pela seleção dos dois possíveis operadores do tipo move propostos: left-right*rl*right 0. 0 ; left-right*rl*left 0. 0. Após aplicar o operador move na direção right, uma preferência por essa direção será criada: left-right*rl*right 1. 0.3 ; left-right*rl*left 0. 0. Isso ocorre devido a elaboração de uma recompensa (+1) para a seleção dos operadores que movem o agente nessa direção (right). Agora, haverá sempre uma preferência maior por selecionar esses operadores que movem o agente para a direita. Após rodar o programa do agente algumas vezes (10 vezes), obtém-se o seguinte resultado: left-right*rl*right 10. 0.9717524751 ; left-right*rl*left 0. 0. Observa-se nitidamente que há uma preferência maior, que foi aprendida pelo agente, por mover-se para a direita.
Problema Water Jug
Para transformar um agente já criado, por exemplo: o agente water-jug, num agente capaz de aprender (water-jug-rl) são necessários três passos: criar RL rules, criar uma ou mais regras de recompensa (reward) e habilitar o mecanismo de Reinforcement Learning do SOAR.
No caso do problema Water Jug, o objetivo é fazer o agente aprender as melhores condições sob as quais ele deve esvaziar (empty) um jarro, encher (fill) um jarro e despejar (pour) o conteúdo de um jarro em outro. Em todos esses casos, o agente deve considerar o volume de água contido no jarro (além da capacidade do jarro). O primeiro passo é remover as preferências indiferentes (=) dos operadores, deixando apenas as preferências aceitáveis (+) dos mesmos. Em seguida, deve-se escrever as RL rules, as regras aplicáveis ao mecanismo de aprendizado. A figura abaixo exibe essas regras:
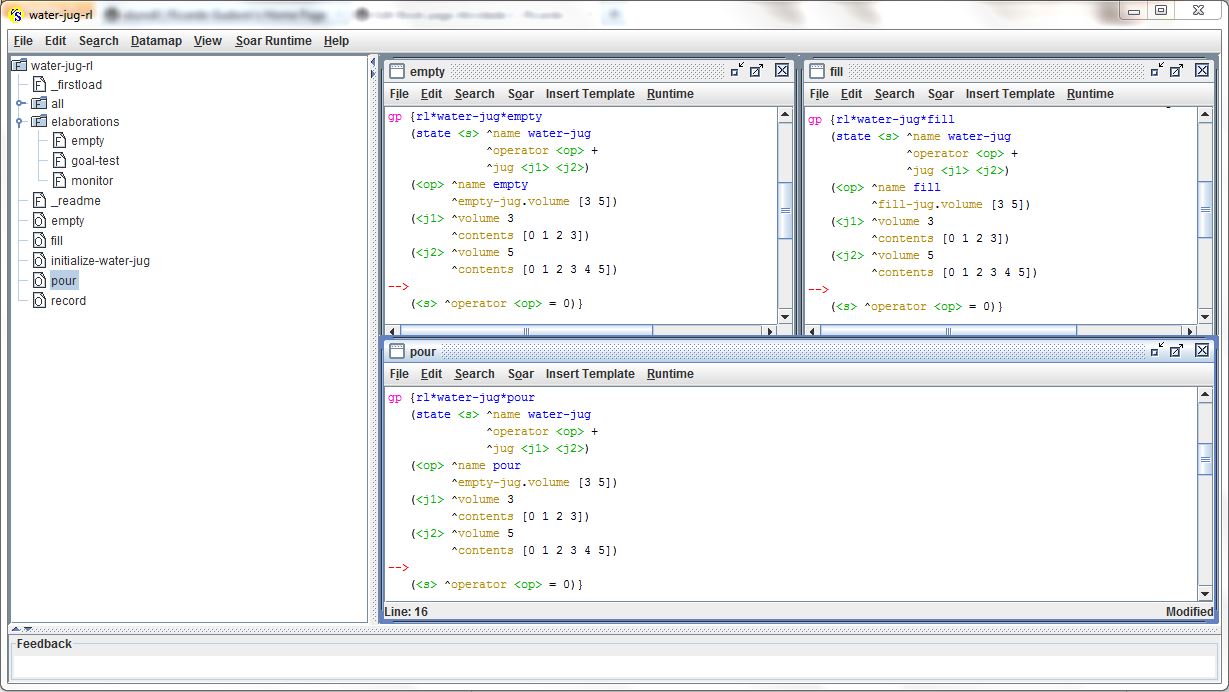
As regras escritas (RL rules) são geradas pelo comando gp, que antecede cada regra. Para cada operador (empty, fill, pour) será necessário gerar um número de regras igual a todas as combinações dos possíveis estados e ações de cada operador. Ou seja, se o operador é aplicado a um jarro de 3 ou de 5 galões, e qual o conteúdo do jarro; lembrando-se que devem ser considerados todos os valores possíveis de conteúdo para cada jarro. Assim, o comando gp vai gerar todas as regras necessárias, considerando todas as combinações possíveis dos estados-ações.
As condições das regras RL detectam a existência de operadores com preferências aceitáveis (^operator <op> +) e criam preferências indiferentes numéricas (<s> ^operator <op> = 0) para esses operadores. O mecanismo de RL do SOAR reconhecerá a existência dessas regras RL e atualizará o valor numérico (preferência) atribuído a cada regra (e ao operador que ela referencia).
As regras de recompensa (reward) trabalham a estrutura do atributo ^reward-link, criado no estado inicial. Essas regras devem ser i-supported para que os valores de recompensa não persistam na memória de trabalho, caso contrário, esses valores seriam considerados múltiplas vezes pelo mecanismo de RL. Os valores de recompensa são armazenados no atributo ^reward.value do ^reward-link, conforme mostra a regra da figura abaixo:
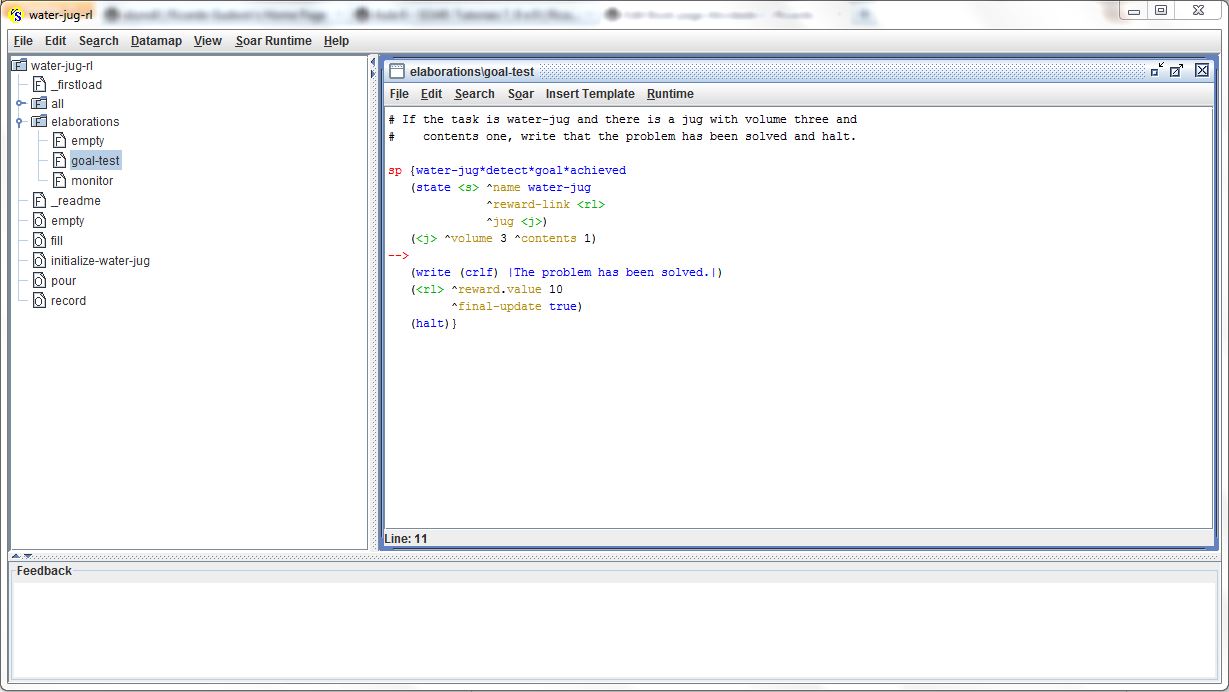
Após rodar o agente, com Reinforcement Learning, foram obtidos os resultados exibidos pelas próximas figuras:
Agente inicializado:
Resultado após encontrar a solução do problema:
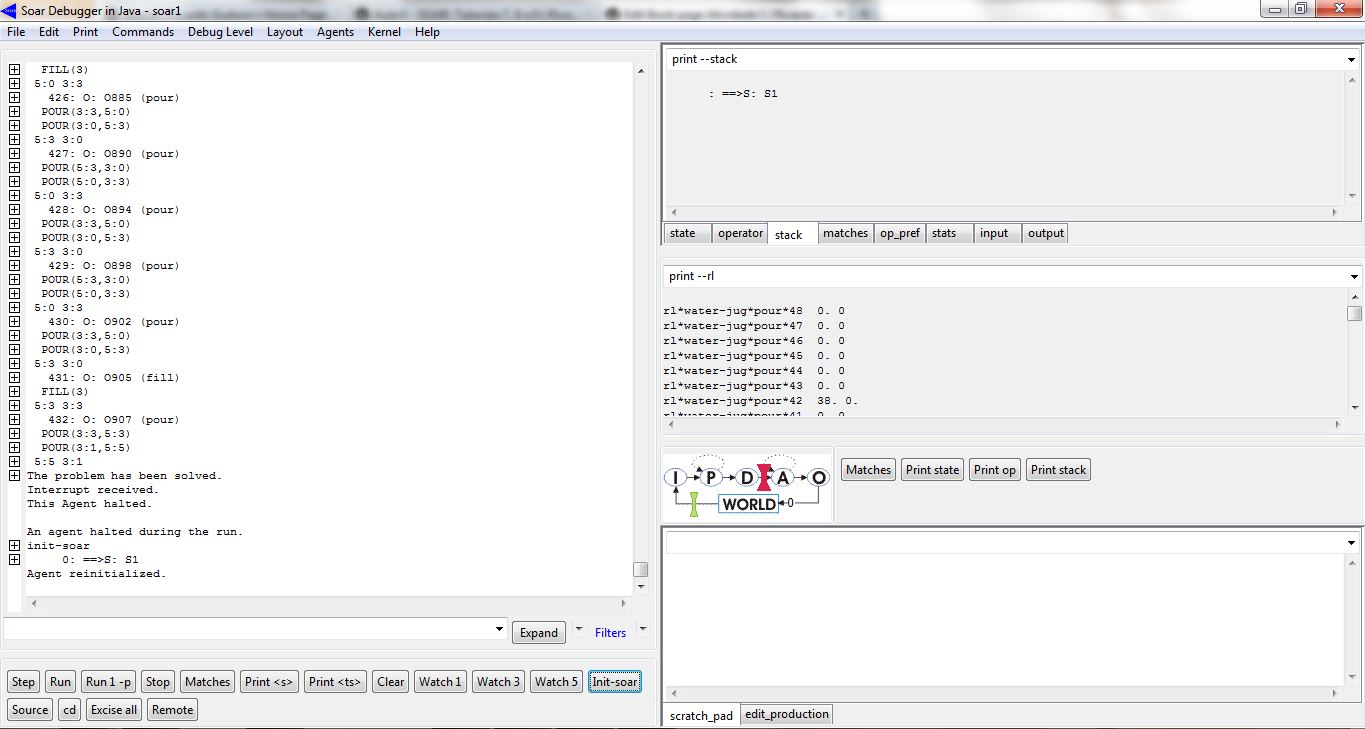
Resultado após rodar o agente várias vezes:
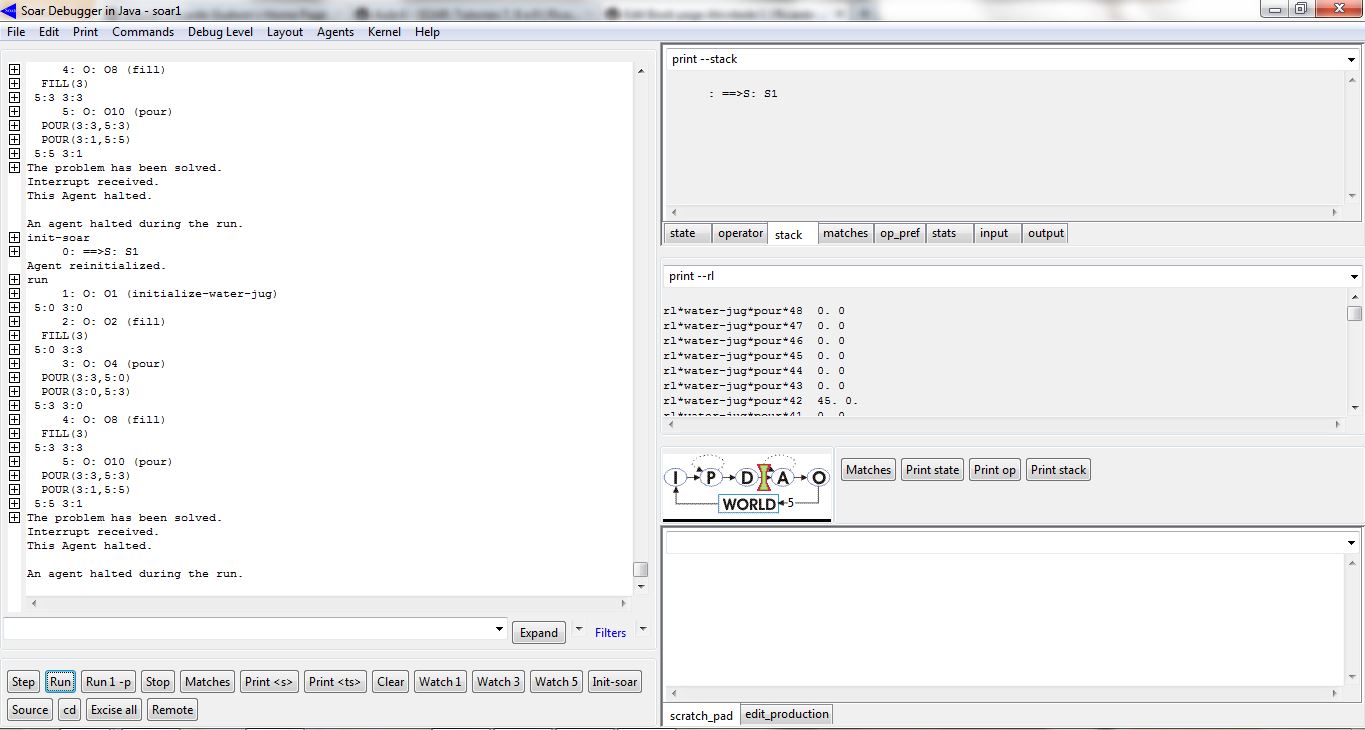
Ao carregar o agente, pode-se visualizar a criação das RL rules pelo comando gp. Foram criadas 48 regras para cada operador (empty, fill, pour). Após rodar o agente, pela primeira vez, foram atribuídos valores de recompensa para alguns operadores. Depois de rodar o agente algumas vezes (cinco vezes), pode-se notar (figura acima) que o agente tem uma tendência por escolher sempre a mesma combinação de operadores que leva à solução do problema. Ou seja, o agente aprendeu uma forma bastante direta de resolver o problema proposto. Isso graças ao mecanismo de Reinforcement Learning do SOAR.
Verificando-se os valores de recompensa atribuídos às RL rules, nota-se que foram atribuídos valores próximos de zero para os operadores empty e valores maiores que zero (tendendo à dez) para alguns operadores fill e pour. Ou seja, na solução do problema, não foram selecionados nenhum dos operadores empty e foram selecionados apenas alguns operadores fill e pour. Os operadores que foram selecionados para a solução do problema, com seus valores de recompensa associados, estão descritos a seguir:
Conteúdo dos jarros: 5:0 3:0 ; Operador selecionado: FILL(3) ; RL rule:
sp {rl*water-jug*fill*1
(state <s> ^name water-jug ^operator <op> + ^jug <j2> ^jug <j1>)
(<op> ^name fill ^fill-jug <f*1>)
(<f*1> ^volume 3)
(<j2> ^volume 5 ^contents 0)
(<j1> ^volume 3 ^contents 0)
-->
(<s> ^operator <op> = 0.48479229)}
Conteúdo dos jarros: 5:0 3:3 ; Operador selecionado: POUR(3:3,5:0) ; RL rule:
sp {rl*water-jug*pour*7
(state <s> ^name water-jug ^operator <op> + ^jug <j2> ^jug <j1>)
(<op> ^name pour ^empty-jug <e*1>)
(<e*1> ^volume 3)
(<j2> ^volume 5 ^contents 0)
(<j1> ^volume 3 ^contents 3)
-->
(<s> ^operator <op> = 2.071089)}
Conteúdo dos jarros: 5:3 3:0 ; Operador selecionado: FILL(3) ; RL rule:
sp {rl*water-jug*fill*25
(state <s> ^name water-jug ^operator <op> + ^jug <j2> ^jug <j1>)
(<op> ^name fill ^fill-jug <f*1>)
(<f*1> ^volume 3)
(<j2> ^volume 5 ^contents 3)
(<j1> ^volume 3 ^contents 0)
-->
(<s> ^operator <op> = 5.218425)}
Conteúdo dos jarros: 5:3 3:3 ; Operador selecionado: POUR(3:3,5:3) ; RL rule:
sp {rl*water-jug*pour*31
(state <s> ^name water-jug ^operator <op> + ^jug <j2> ^jug <j1>)
(<op> ^name pour ^empty-jug <e*1>)
(<e*1> ^volume 3)
(<j2> ^volume 5 ^contents 3)
(<j1> ^volume 3 ^contents 3)
-->
(<s> ^operator <op> = 8.823510000000001)}
Um outro ponto importante, considerado na busca pela solução do problema, são as políticas de exploração. A política de exploração dos operadores determina que, às vezes, pode ser interessante aplicar alguns operadores com baixa preferência, na busca pela solução de um problema, ao invés de selecionar algum operador de maior preferência. Ou seja, durante o processo de Reinforcement Learning, o aprendizado do caminho que leva à solução de um problema deve considerar a escolha de alguns operadores menos prediletos. A escolha de alguns desses operadores pode levar a uma melhor saída para solucionar um problema.
O SOAR permite o ajuste do nível de exploração dos operadores, e dos caminhos alternativos para solucionar um problema, por meio do comando indifferent-selection. Pode-se consultar a política de exploração que está sendo usada, atualmente pelo SOAR, digitando-se o comando indifferent-selection --stats no SOAR Debugger. Há cinco políticas de exploração configuráveis no SOAR: boltzmann, epsilon-greedy, softmax, first, last. A política de exploração usada neste exemplo foi definida pelo comando: indifferent-selection --epsilon-greedy. Essa política adotada permite que, aleatóriamente, algum operador de menor preferência seja selecionado. O valor default de epsilon é 0.1. Ou seja, em 90% das vezes, algum operador de maior preferência será selecionado, sendo que nos 10% restantes, algum outro operador de menor preferência será experimentado. O valor de epsilon pode ser configurado, entre 0 e 1, pelo comando: indifferent-selection --epsilon <value>. Onde <value> refere-se ao valor desejado. Valores próximos de zero limitam a escolha aleatória dos operadores. Valores próximos a um tornam a escolha praticamente aleatória.
Theme by Danetsoft and Danang Probo Sayekti inspired by Maksimer