
- Aula 01 - Introdução
- Aula 02 - SOAR: Tutorial 1
- Aula 03 - SOAR: Tutorial 2
- Aula 04 - SOAR: Tutorial 3
- Aula 05 - SOAR: Tutoriais 4 e 5
- Aula 06 - SOAR: Tutoriais 7,8 e 9
- Aula 07 - SOAR: Controlando o WorldServer3D
- Aula 08 e Aula 09 - Clarion 1,2
- Aula 10 e Aula 11 - Clarion: Controlando o WorldServer3D
- Aula 12 - LIDA 1: Entendendo a Arquitetura
- Aula 13 - LIDA 2: Exemplos de Implementação Prática
- Aula 14 e Aula 15 - Projeto
You are here
Atividade 2
Planejamento e Aprendizado
O SOAR permite que sejam usadas estratégias de planejamento na busca pela solução dos problemas. Uma estratégia bem simples de planejamento é o "look-ahead". Os programas SOAR podem usar sub-metas para planejar e aprender. Com apenas poucas modificações, pode-se implementar o planejamento nos problemas Water Jug e Missionários e Canibais, já estudados anteriormente. O aprendizado será implementado pelo uso de chunking que é uma forma de generalização baseada em explanação. O chunking cria regras de controle de busca, além de poder criar outros tipos de regras tais como elaborações, proposição e aplicação de operadores.
Os programas SOAR que usam planejamento look-ahead testarão operadores, internamente, para avaliá-los antes de aplicá-los, de fato, na tarefa real. O planejamento provê um modo alternativo de comparar operadores baseando-se nos estados que eles produzem. O chunking constrói regras que resumem as comparações e avaliações que ocorrem na busca look-ahead. Assim, posteriormente, as regras disparam sem ter que realizar buscas desnecessárias, convertendo deliberação em reação. O planejamento no SOAR não cria uma sequência de operadores aplicados cegamente, mas, aprende um conjunto de regras dependentes do contexto que preferem ou evitam operadores específicos para determinados estados. Os planos no SOAR são mais flexíveis, ou seja, planos aprendidos para um problema podem ser transferidos para o contexto de outro problema.
Problema Water Jug
O planejamento no SOAR é implementado através do mecanismo de detecção de impasses e criação de sub-estados. Normalmente, as regras que propõem os operadores possuem preferências indiferentes à seleção dos operadores. Porém, ao se trabalhar com planejamento, essa indiferença pela seleção dos operadores precisa ser eliminada. Será necessário definir qual operador pode ser melhor aplicado, num estado, para se chegar à solução do problema. É nisso que consiste o planejamento: escolher os melhores operadores para serem aplicados nos estados que levam à solução do problema.
No problema Water Jug, ao se eliminar a preferência indiferente (<s> ^operator <o> + =) pelos operadores (<s> ^operator <o> +), ocorrerá impasses do tipo tie, ou seja, não há preferências suficientes para se escolher entre dois ou mais operadores. A figura abaixo exibe o resultado (tela do SOAR Debugger) quando ocorre esse tipo de impasse:

Pode-se observar na figura acima que foi criado um novo sub-estado (2: ==>S: S3) devido ao surgimento de um impasse do tipo tie (S: S3 (operator tie)). Analisando-se o novo sub-estado criado (comando p s3), pode-se perceber que o mesmo possui alguns atributos característicos: ^choices multiple, ^impasse tie, ^item. Os argumentos ^item são gerados para cada operador que contribuiu com a geração do impasse detectado.
Quando ocorrer esse tipo de impasse, a meta desejada será determinar qual o melhor operador para ser aplicado no estado atual. Isso será realizado por meio do uso de operadores de avaliação que serão selecionados e aplicados no sub-estado. Esses operadores farão a avaliação de cada um dos possíveis operadores que podem ser aplicados na solução do problema, naquele estado corrente. As avaliações (falha, sucesso ou um valor numérico) serão posteriormente convertidas em preferências pela seleção dos operadores que levam à solução do problema. Após terem sido criadas preferências pela seleção dos operadores, algum operador (melhor avaliado) poderá ser selecionado e o sub-estado criado será excluído da memória de trabalho.
Os operadores serão avaliados mediante a análise dos possíveis estados que seriam criados após a aplicação desses operadores, a partir do sub-estado gerado. Os estados podem ser avaliados como um estado desejado, ou um estado falho, ou ainda, como sendo um estado inicial. Também pode ser aplicada uma função que leva a uma estimativa do quanto aquele estado está próximo do estado final desejado.
O problema da Seleção, isto é, a avaliação dos operadores que devem ser selecionados quando ocorre um sub-estado gerado pela ocorrência de um impasse, requer o conhecimento de algumas características do problema que serão discutidas a seguir. Dentre as quais: Representação do Estado, a representação dos objetos de avaliação que atribuem avaliações aos operadores; Regra de Criação do Estado Inicial, visto que o problema da seleção emerge a partir de um sub-estado criado pelo impasse, um estado inicial é gerado automaticamente; Regras de Proposição de Operadores, o único operador proposto deve ser o próprio operador de avaliação que será sempre proposto quando ocorrer um impasse; Regras de Aplicação de Operadores, a aplicação dos operadores requer a ocorrência de um sub-estado e a existência de operadores aplicáveis ao sub-estado criado; Regras de Monitoração de Estados e Operadores, não serão necessárias para o problema da seleção; Regra de Reconhecimento do Estado Desejado, o reconhecimento do estado desejado é automático, ou seja, quando houver preferências suficientes, o procedimento de decisão selecionará um operador, resolvendo o impasse e removendo o sub-estado criado; Regra de Reconhecimento de Estado Falho, não há estados falhos para o problema da seleção; Regras de Controle de Busca, estas regras ajudam a direcionar qual operador deveria ser avaliado primeiramente.
Representação do Estado
Os operadores de avaliação, durante a ocorrência do impasse criando um sub-estado, devem criar e comparar avaliações sobre os possíveis operadores aplicáveis ao super-estado do problema. Essas avaliações serão usadas, posteriormente, para criar preferências para os operadores aplicáveis no super-estado. As avaliações devem incluir o nome do operador (do super-estado) avaliado, além de um valor de avaliação atribuído a esse operador. Esses valores podem ser simbólicos ou numéricos. Pode-se também incluir um atributo para armazenar informações sobre o estado desejado, auxiliando na avaliação dos operadores.
Para o problema do Water Jug, o operador de avaliação (evaluate-operator) será proposto na ocorrência de um impasse (^impasse tie). Esse operador de avaliação possui um objeto de avaliação (^evaluation) como um atributo. Esse objeto (^evaluation) conterá as informações sobre a representação do estado do problema de seleção. Ou seja, esse objeto definirá o nome (^super-operator.name) dos operadores do super-estado (empty, fill, pour) que causaram o impasse, além de um valor (best, equal, worst) atribuído a cada operador. As regras de avaliação dos operadores (evaluate-operator) serão responsáveis pelos valores atribuídos a cada operador, de acordo com o último operador que foi aplicado no super-estado.
Criação do Estado Inicial e Proposição de Operadores
O estado inicial, para o problema da seleção, será criado automaticamente (como um sub-estado) assim que ocorrer um impasse (do tipo tie). No entanto, os objetos de avaliação deverão ser criados pela aplicação de operadores que precisam detectar a ocorrência do impasse e a criação de um novo sub-estado na memória de trabalho, para serem propostos.
Observando-se, novamente, a primeira figura exibida acima, nota-se algumas características interessantes sobre o novo sub-estado criado (2: ==>S: S3 (operator tie)). Essas características serão exploradas pelas regras exibidas na figura abaixo:
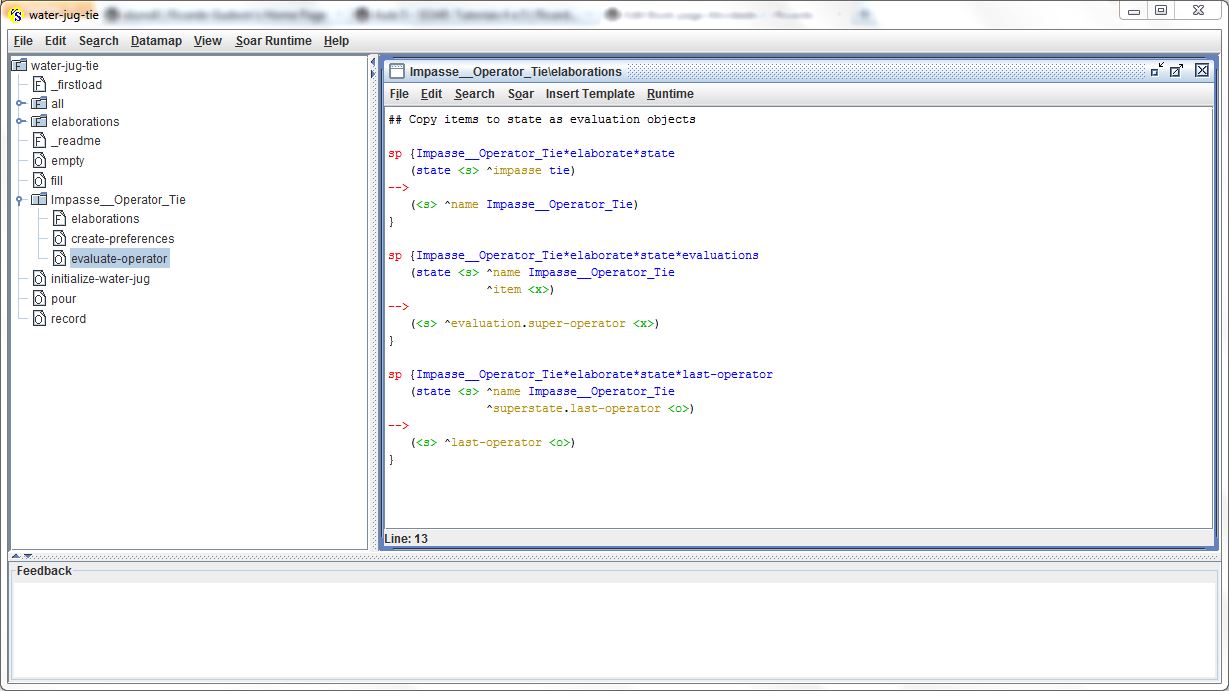
A primeira regra, da figura acima, detecta a criação de um (sub) estado que contenha um atributo do tipo ^impasse (state <s> ^impasse tie). Havendo um estado desse tipo, na memória de trabalho, a regra irá renomear o estado criado como sendo um estado do tipo "Impasse__Operator_Tie" (<s> ^name Impasse__Operator_Tie). Agora, tendo renomeado o sub-estado criado, outras regras poderão propor os operadores para resolver o problema da seleção.
O único operador que será proposto para o problema da seleção é o operador de avaliação (evaluate-operator). Antes de propor este operador, as demais regras exibidas na figura acima tratam de criar atributos, no sub-estado criado, cujas informações serão usadas por esse operador. Essas regras disparam quando o sub-estado é renomeado (state <s> ^name Impasse__Operator_Tie). Uma dessas regras explora os atributos ^item do sub-estado criado. Esses atributos armazenam os operadores que deram origem ao impasse, sendo que essa regra lê esses atributos (state <s> ^item <x>), repassando-os como novos atributos do tipo ^evaluation (<s> ^evaluation.super-operator <x>). A próxima figura exibe esses novos atributos criados no sub-estado (^evaluation E3, ^evaluation E4). A outra regra (figura acima) cria um novo atributo no sub-estado criado que armazena o último operador (<s> ^last-operator <o>) que foi aplicado no super-estado (state <s> ^superstate.last-operator <o>) para levar à solução do problema (Water Jug). A figura abaixo também exibe esse novo atributo criado no sub-estado:
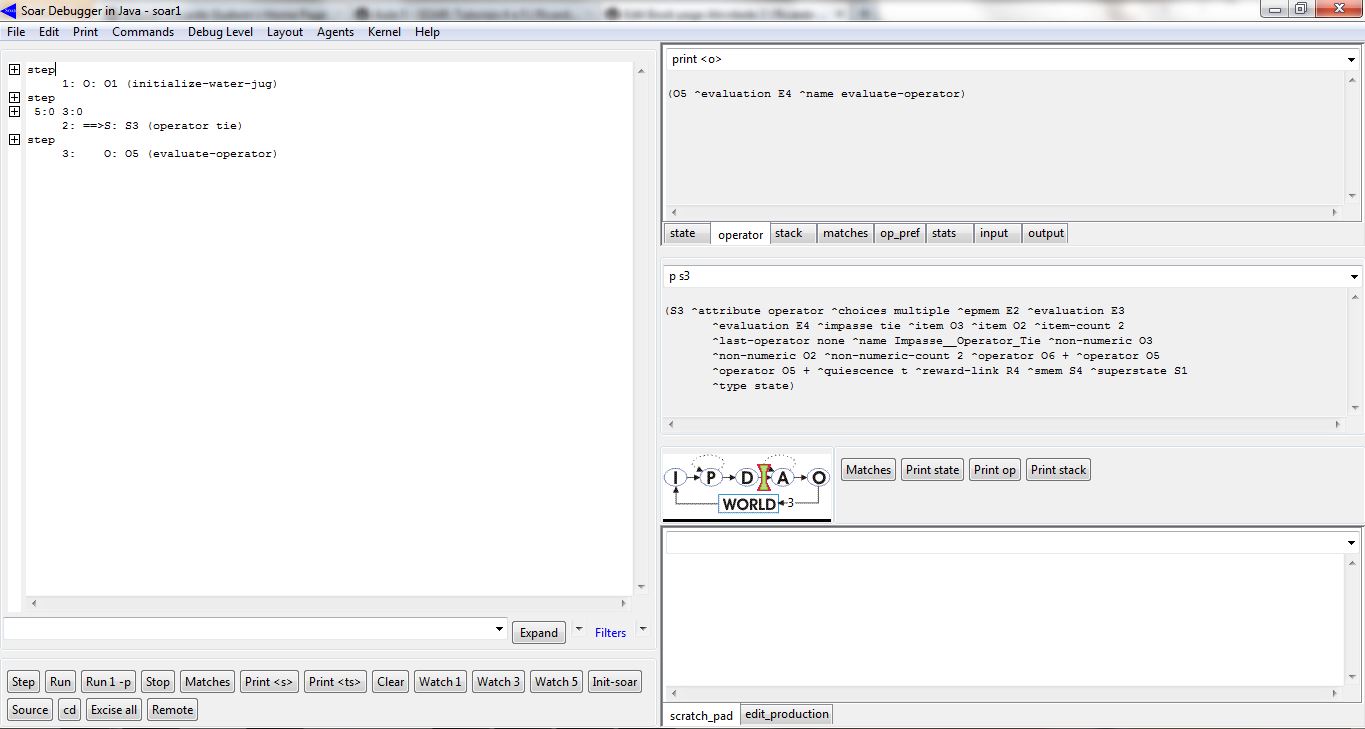
A figura acima exibe o operador de avaliação (O: O5 (evaluate-operator)) que foi proposto no novo sub-estado criado pela ocorrência do impasse (S: S3 (operator tie)). Esse operador será proposto para cada objeto de avaliação (^evaluation <x>) criado que ainda não contenha um valor atribuído ao mesmo (-(<x> ^value)), conforme a regra abaixo:
sp {Impasse__Operator_Tie*propose*evaluate-operator
(state <s> ^name Impasse__Operator_Tie
^evaluation <x>)
-(<x> ^value)
-->
(<s> ^operator <op> + =)
(<op> ^name evaluate-operator
^evaluation <x>)}
O próximo passo será aplicar cada um desses operadores que foram propostos.
Aplicação dos Operadores e Criação de Preferências
Os operadores de avaliação serão aplicados por regras distintas para cada tipo de operador (do super-estado) que deu origem ao impasse e que é um candidato a ser selecionado, desfazendo o impasse gerado. Deve-se considerar o quanto o estado criado pela possível aplicação do operador, no super-estado, se aproxima do estado final desejado. Devem ser criadas heurísticas, para a aplicação dos operadores de avaliação, de acordo com o problema a ser solucionado.
Assim, a solução do problema da seleção (no sub-estado) também depende do próprio problema a ser solucionado (no super-estado). Poderá ser necessário simular, internamente, novos estados possíveis de serem gerados (e seus possíveis resultados) para, só então, ser possível avaliar adequadamente cada operador do super-estado. No problema Water Jug, isso não será necessário.
Para o problema Water Jug, os operadores do super-estado serão avaliados simbolicamente com valores do tipo best, equal ou worst. Esses valores serão, posteriormente, usados para criar preferências pela seleção dos operadores do super-estado. Será usada uma heurística para determinar o valor correto que deverá ser atribuído a cada operador (do super-estado) avaliado. Assim, serão necessárias algumas regras de aplicação para as possíveis versões do mesmo operador de avaliação (evaluate-operator) que podem ser propostas. A figura abaixo exibe as regras que aplicam os operadores de avaliação possíveis:

As regras de aplicação do operador de avaliação (<op> ^name evaluate-operator) consideram o último operador que foi aplicado no super-estado (state <s> ^last-operator) e o operador que contribuiu com a geração do impasse (<x> ^super-operator.name). De acordo com cada operador que já foi aplicado (fill, empty, pour), cada possível operador aplicável (para desfazer o impasse) terá um valor de avaliação (best, equal, worst) que refletirá a preferência pela seleção desse operador. A figura, a seguir, exibe os operadores de avaliação selecionados durante o impasse gerado:
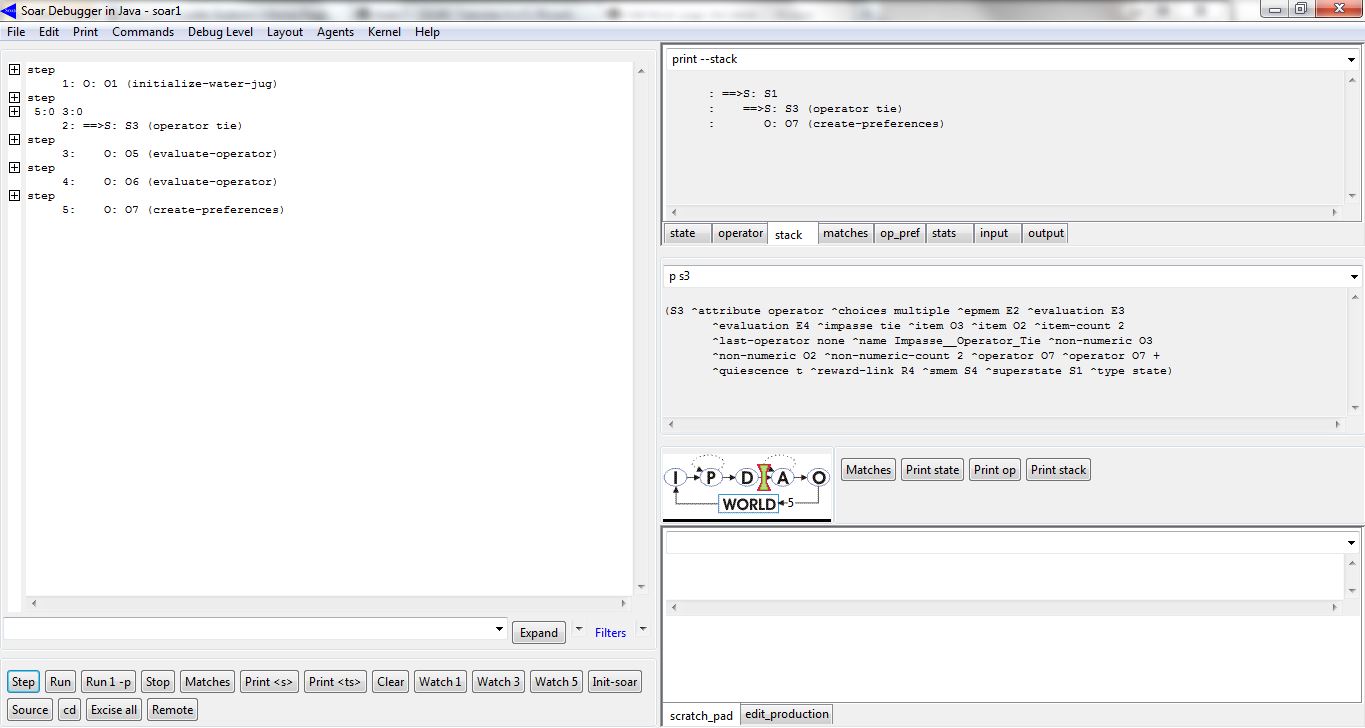
Foram selecionados (e aplicados) dois operadores de avaliação (evaluate-operator), e logo em seguida, foi proposto (e aplicado) o operador responsável pela criação das preferências pela seleção dos operadores do super-estado do problema. A figura abaixo exibe as regras que criam as preferências para esses operadores:
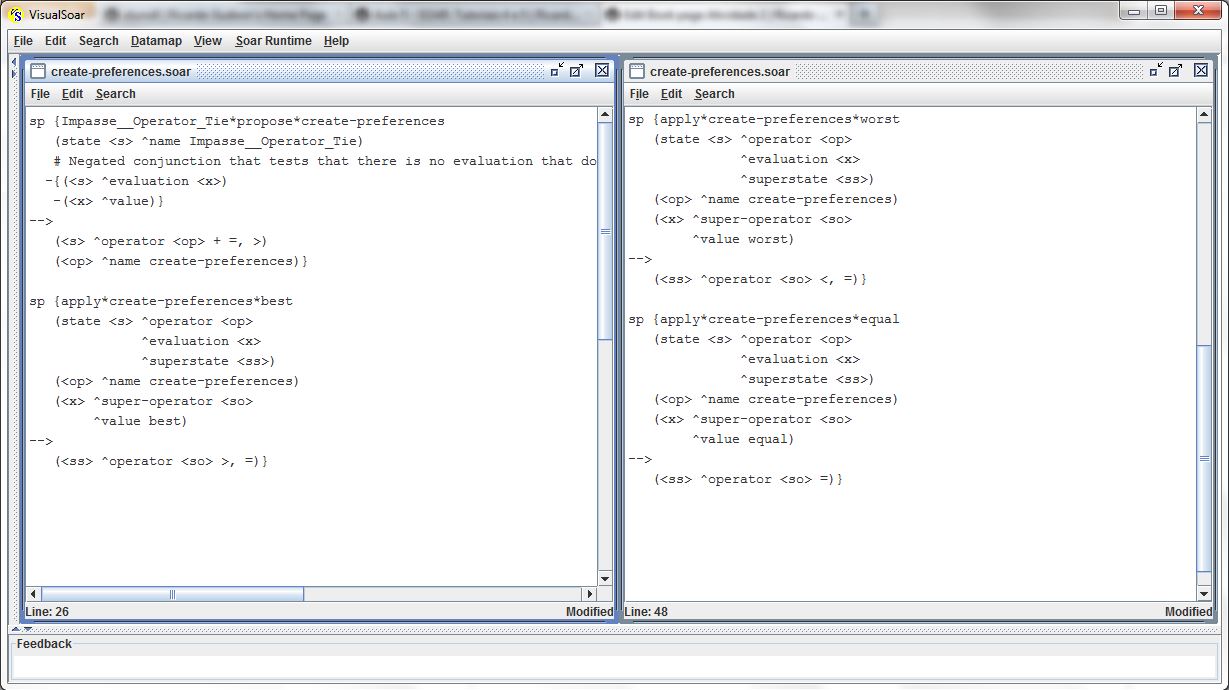
De acordo com os valores (best, equal, worst) de cada operador avaliado, serão criadas as preferências melhor (<ss> ^operator <so> >, =), indiferente (<ss> ^operator <so> =) ou pior (<ss> ^operator <so> <, =) para esses operadores avaliados. Tendo sido criadas preferências para a seleção dos operadores no super-estado, agora o impasse poderá ser resolvido e o sub-estado criado será removido da memória de trabalho. A figura abaixo exibe os resultados dessas operações:

Percebe-se, na figura acima, que um operador pode ser selecionado (O: O2 (fill)), desfazendo o impasse. Após aplicar esse operador (FILL(3)), um novo impasse foi gerado (S: S5 (operator tie)) e o processo de solução do problema de seleção será retomado, novamente. Rodando-se o programa, após alguns passos e alguns sub-estados gerados, a solução do problema é alcançada ("The problem has been solved.").
Chunking
O SOAR implementa um mecanismo de aprendizado denominado chunking. O chunking é invocado quando um resultado é produzido num sub-estado. O mecanismo de chunking irá criar novas regras onde as ações serão os resultados obtidos nos subestados. Por exemplo, o chunking poderá criar uma nova regra de elaboração das preferências pela seleção de um operador, mediante a percepção de que uma situação (condições que foram atendidas no sub-estado) sempre leva a uma maior preferência por determinado operador. Assim, com o mecanismo de chunking ativado, não será mais necessário realizar o planejamento das ações a serem tomadas quando uma nova situação assemelha-se com uma situação já conhecida (aprendida) pelo mecanismo de chunking.
O chunking analisa os elementos da memória de trabalho (WME's) que casaram com as condições da regra que gerou um resultado no sub-estado criado. Se alguns desses WME's estão relacionados ao super-estado, então, esses elementos tornam-se condições numa nova regra que gera esse mesmo resultado alcançado nesse sub-estado. O mecanismo de chunking se encarrega de realizar o backtracing de todas as condições que levaram ao disparo daquela regra, associando os WME's identificados nesse processso com as condições dessa nova regra que será criada. Após coletar todas as condições necessárias para a nova regra, o SOAR converte todos os identificadores associados aos WME's em variáveis e adiciona a nova regra à memória de regras (Rule Memory). Essa nova regra criada pelo mecanismo de chunking estará, então, disponível para ser disparada igual às demais regras escritas pelo programador.
A produção water-jug-look-ahead também implementa um planejamento look-ahead para solucionar o problema Water Jug. A criação de novas regras pelo mecanismo de chunking pode ser demonstrada rodando-se essa produção no SOAR Debugger. Essa produção possui uma abordagem um pouco diferente da produção water-jug-tie discutida anteriormente. A figura, a seguir, exibe algumas regras adicionadas a essa produção para implementar o planejamento das ações a serem tomadas no super-estado do problema:
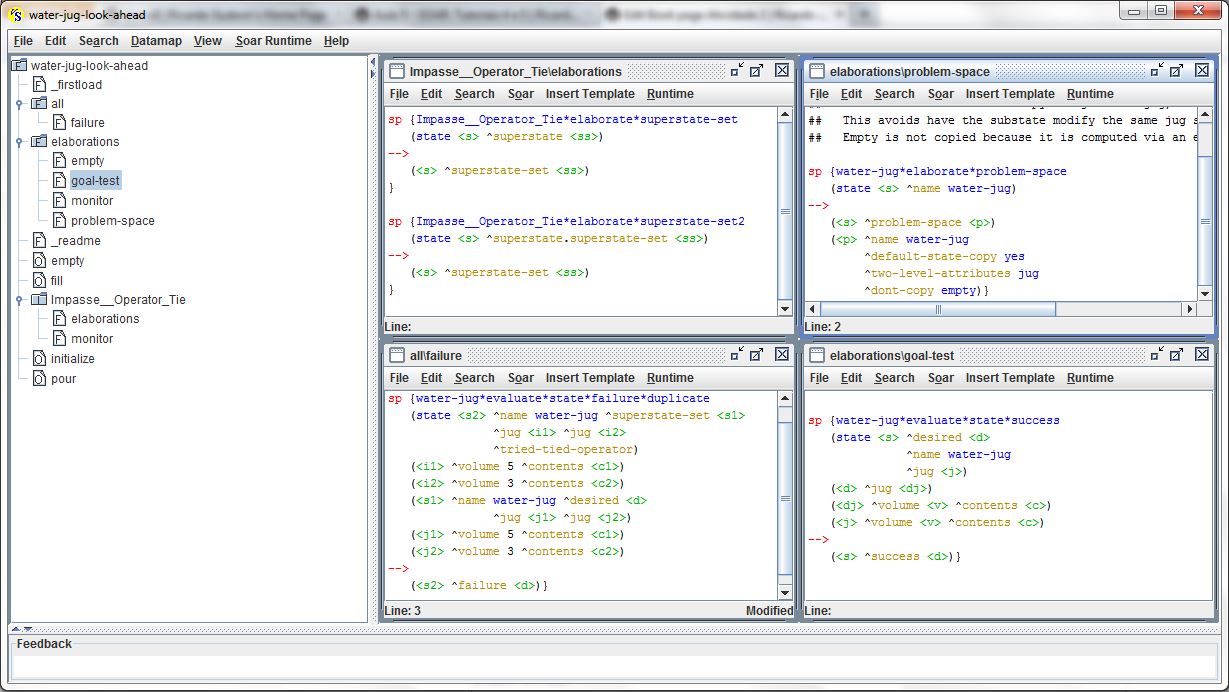
Uma dessas regras se encarrega de gravar cópias do super-estado (state <s> ^superstate <ss>) e de todos os conjuntos de super-estados associados a ele (state <s> ^superstate.superstate-set <ss>). Outra regra define alguns atributos associados ao espaço do problema (<s> ^problem-space <p>). As demais regras detectam a ocorrência de um estado falho (<s2> ^failure <d>) ou do estado final desejado (<s> ^success <d>).
Para visualizar a criação de novas regras pelo mecanismo de chunking, usando essa produção, é necessário configurar o arquivo _firstload (do projeto) incluindo o seguinte comando: learn --on. Esse comando ativará o mecanismo de aprendizado, isto é, o chunking do SOAR. Também será necessário digitar o comando watch --learning print, na janela de comando do SOAR Debugger, para visualizar a criação dos chunks em tempo de execução. A figura abaixo exibe alguns chunks que foram criados:

Pode-se visualizar a criação, em tempo de execução, de um chunking relacionado a um impasse do tipo tie: Building chunk-94*d184*tie*2. As janelas direitas do SOAR Debugger exibem mais informações sobre os chunks criados. O comando print --chunk exibe os chunks que foram criados durante a execução do programa. E, por exemplo, o comando p chunk-94*d184*tie*2 imprime a nova regra que foi criada pelo mecanismo de chunking. Essa regra está exibida abaixo:
sp {chunk-94*d184*tie*2
:chunk
(state <s1> ^name water-jug ^operator <o1> + ^problem-space <p1>
^desired <d1> ^jug <j1> ^jug <j2>)
(<o1> ^name fill ^jug <j1>)
(<p1> ^name water-jug)
(<j1> ^contents 0 ^volume 3)
(<j2> ^contents 0 ^volume 5)
(<d1> ^jug <j3>)
(<j3> ^contents 1 ^volume 3)
-->
(<s1> ^operator <o1> >)}
Percebe-se que essa é uma regra de elaboração de operadores. A ação dessa regra consiste em aumentar a preferência pela seleção de um operador (<s1> ^operator <o1> >) que foi proposto no sub-estado criado pelo impasse. Esse operador refere-se à ação FILL(3), ou seja, o operador fill (<o1> ^name fill ^jug <j1>) que enche um jarro de 3 galões (<j1> ^contents 0 ^volume 3) teve sua preferência aumentada. As condições para disparar essa regra são, basicamente, que haja um jarro de 3 galões vazio (<j1> ^contents 0 ^volume 3) e um jarro de 5 galões também vazio (<j2> ^contents 0 ^volume 5). Tendo sido criada essa nova regra, futuramente, quando essas mesmas condições se repetirem, essa regra será disparada. Isto é, haverá uma preferência maior em selecionar o operador que enche o jarro de 3 galões.
Problema Missionários e Canibais
A produção mac-planning implementa o planejamento e o aprendizado por meio de chunking. Essa produção usa uma avaliação numérica para avaliar os operadores aplicáveis no super-estado do problema. A avaliação considera o número de missionários e canibais transportados para a outra margem do rio. Sendo que a preferência maior será por operadores que movem mais missionários e/ou canibais para a margem do rio desejada. A figura abaixo ilustra a regra de avaliação dos operadores:
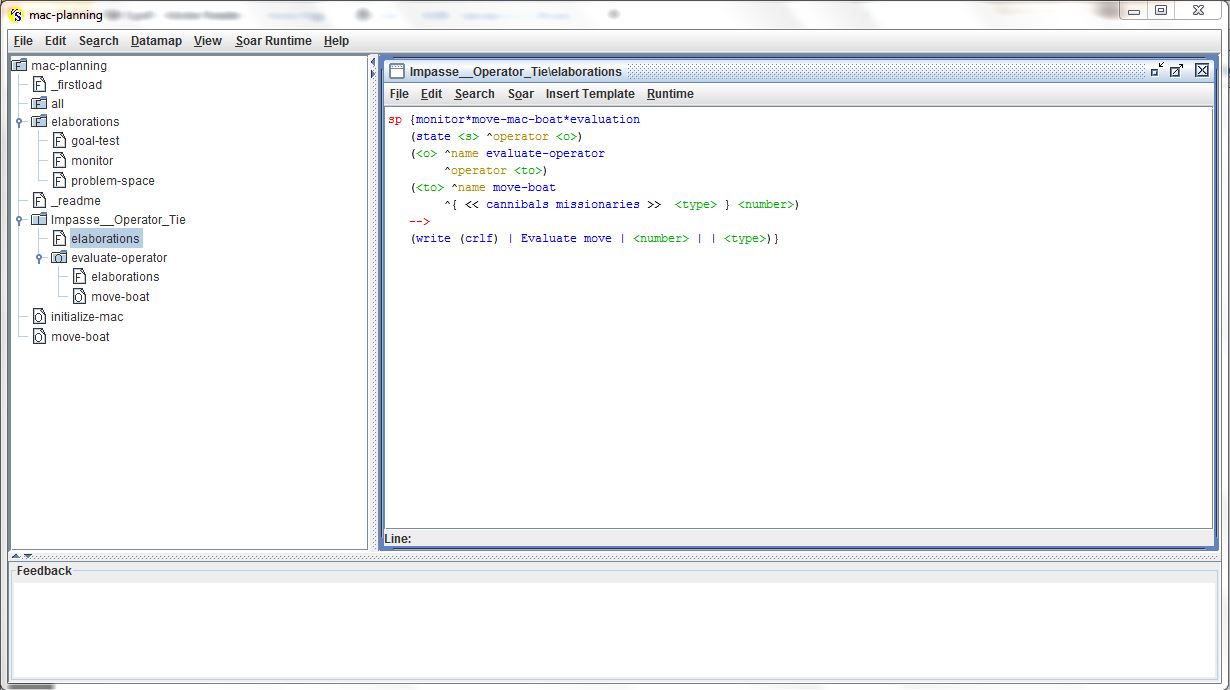
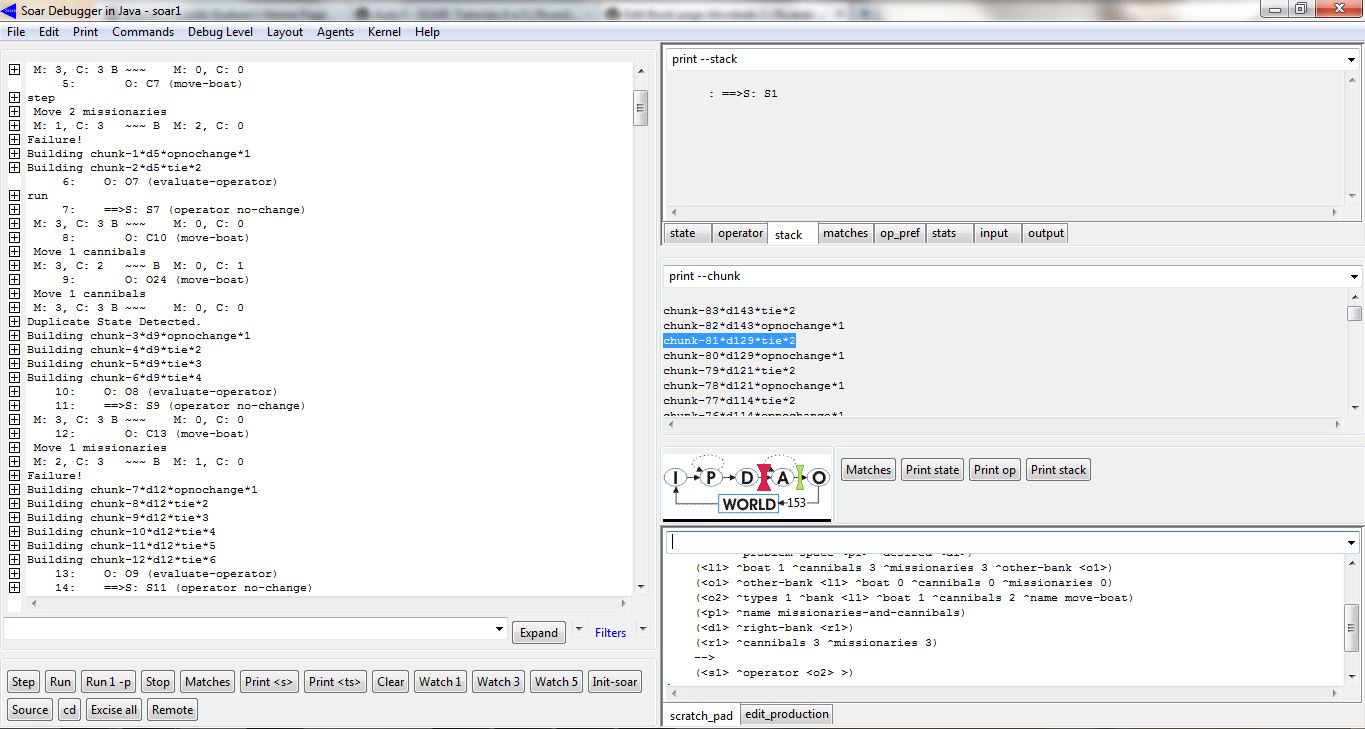
Rodando-se essa produção, no SOAR Debugger, obteve-se o seguinte resultado exibido na figura a seguir. Pode-se visualizar a criação dos chunks pelo mecanismo de aprendizado do SOAR.
Theme by Danetsoft and Danang Probo Sayekti inspired by Maksimer