
- Aula 01 - Introdução
- Aula 02 - SOAR: Tutorial 1
- Aula 03 - SOAR: Tutorial 2
- Aula 04 - SOAR: Tutorial 3
- Aula 05 - SOAR: Tutoriais 4 e 5
- Aula 06 - SOAR: Tutoriais 7,8 e 9
- Aula 07 - SOAR: Controlando o WorldServer3D
- Aula 08 e Aula 09 - Clarion 1,2
- Aula 10 e Aula 11 - Clarion: Controlando o WorldServer3D
- Aula 12 - LIDA 1: Entendendo a Arquitetura
- Aula 13 - LIDA 2: Exemplos de Implementação Prática
- Aula 14 e Aula 15 - Projeto
You are here
Atividade 1
CLARION
O CLARION é uma arquitetura cognitiva desenvolvida pelo grupo de pesquisa do Prof. Ron Sun, na Universidade de Michigan. O CLARION é uma arquitetura cognitiva que incorpora a distinção entre processos implícitos e explícitos, focando na captura das interações entre esses dois tipos de processos. A representação do conhecimento implícito é realizada de forma sub-simbólica, isto é, esse tipo de conhecimento é representado de forma distribuída dentro de uma rede neural artificial. O conhecimento explícito será representado de forma simbólica, por uma modelagem computacional desse conhecimento.
Devido à natureza dual do conhecimento trabalhado pela arquitetura, a arquitetura está particionada em dois níveis. Cada nível usa um tipo de representação e captura um tipo correspondente de processo (implícito ou explícito). Cada nível corresponde a múltiplos módulos. Dois módulos estão presentes em ambos níveis. São os sub-sistemas: ACS (Action-Centered Subsystem) e NACS (Non-Action-Centered Subsystem). O ACS encapsula o conhecimento procedural (redes neurais) e o NACS, o conhecimento declarativo (regras).
Os processos NACS baseiam-se em conhecimentos que não envolvem ações recomendadas, ou seja, não são direcionados numa única direção específica. Os processos ACS baseiam-se em conhecimentos que recomendam algum tipo de tomada de decisão, ou seja, são direcionados numa direção específica.
O módulo ACS (de ambos os níveis) possui uma Memória de Trabalho (Working Memory), para armazenar informações temporárias, e uma GS (Goal Structure). A GS é usada para organizar as atividades do agente. A GS direciona as ações do agente de acordo com seus drives, desejos e motivações.
O módulo NACS (de ambos os níveis) representa o conhecimento declarativo que é mais estático e genérico. Esse tipo de conhecimento é comumente referido como Memória Semântica (Semantic Memory). Essa memória semântica constitui o conhecimento sobre o mundo de forma conceitual e simbólica. Os módulos NACS servem como memória de longa duração, podendo armazenar informações episódicas.
Em ambos os módulos, ACS e NACS, o conhecimento explícito é representado por regras e chunks. As regras incluem as action rules (ACS) e as associative rules (NACS). Os chunks estão envolvidos na representação dessas regras, descrevendo as condições e as conclusões das regras.
Além do ACS e do NACS, o CLARION também possui outros dois componentes: o MS (Motivational Subsystem) e o MCS (Meta-Cognitive Subsystem). O MS é responsável pelos estados motivacionais, ou seja, os drives e goals. Os drives são definidos como "forças" motivacionais que estão por trás das tomadas de decisão de ambos os processos ACS e NACS. Os goals (metas) são abstraídos dos drives, provendo motivações específicas e fornecendo um contexto para as ações que o agente deverá tomar. As ações serão selecionadas de acordo com seus "valores" relacionados a meta (goal) atual. O MCS está relacionado à definição de metas (goals) a partir dos drives, e, à definição dos parâmetros para as tomadas de decisão e raciocínio, a partir dos estados motivacionais.
Os módulos ACS contêm as redes de decisão de ações de baixo nível implícitas, grupos de action rules de alto nível explícitas, memória de trabalho e goal structure. Esses módulos constituem os componentes anatômicos primários da mente, decidindo o que o agente deve fazer a cada passo do caminho. Os módulos NACS contêm o conhecimento geral explícito (memória semântica explícita) e as redes de memória associativa implícitas (memória semântica implícita). Esses módulos suplementam os módulos ACS de várias formas. Os dois módulos, ACS e NACS, constituem os dois subsistemas do CLARION. Eles operam sob a influência dos módulos (processos) MS e MCS.
O aprendizado, na arquitetura CLARION, se divide em dois níveis: bottom level e top level. No bottom level, o aprendizado ocorre por meio de redes neurais. As redes neurais aprendem o conhecimento implícito, representando-o de forma distribuídas nos seus nós (pesos da rede neural). As redes neurais mapeiam estados a avaliações das ações, ou, entradas a suas saídas associadas. Outra forma de aprendizado usado no bottom level ocorre por meio de reinforcement learning. O Q-learning é normalmente usado, sendo que para este tipo de aprendizado não é necessário fornecer um mapeamento entre entradas/saídas desejadas.
No top level, o aprendizado ocorre por três métodos. O conhecimento implícito, aprendido, pode ser usado para se extrair regras que representam o conhecimento explícito. Essas regras serão posteriormente refinadas para melhor representarem o conhecimento do mundo exterior ao agente. O conhecimento explícito também pode ser adquirido sem se recorrer ao conhecimento implícito já aprendido. Podem ser criadas regras independentes que serão continuamente testadas para se atestar, através da experiência, suas validades. Pode-se também usar regras pré-definidas, codificadas no "DNA" do agente ou adquiridas de experiências prévias, para codificar o conhecimento explícito sem a necessidade do agente interagir com seu ambiente para aprendê-las.
Arquitetura do CLARION:
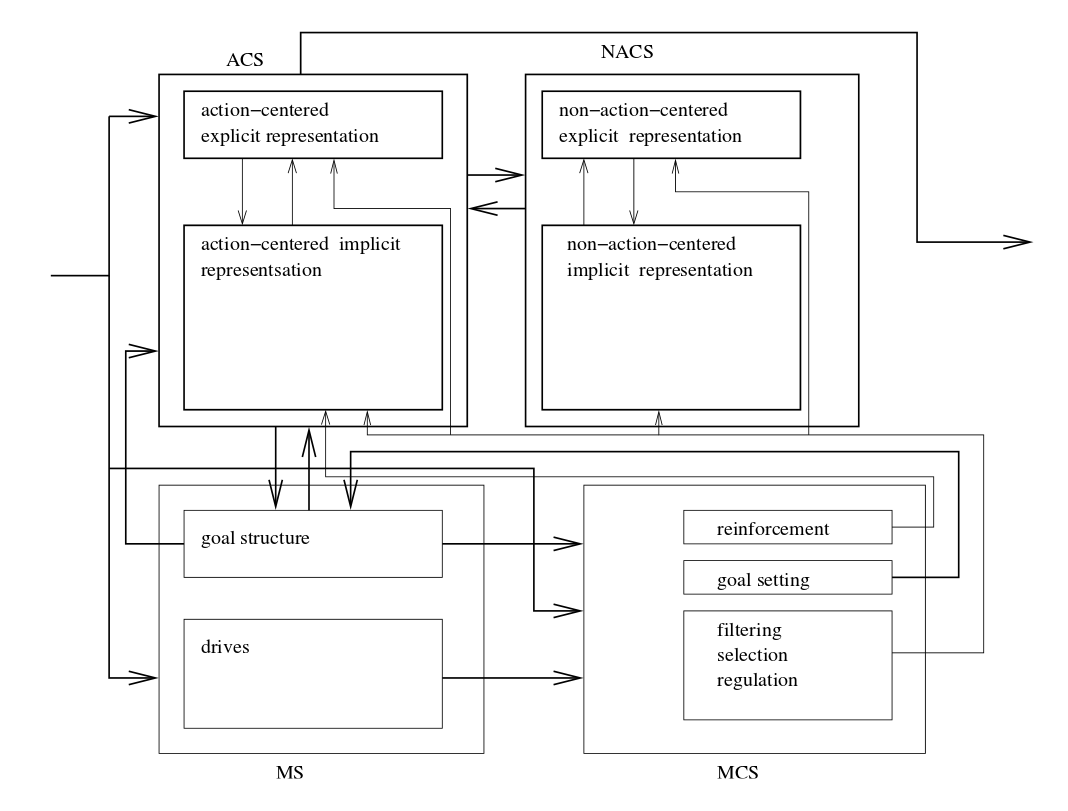
A arquitetura do CLARION (figura acima) está particionada em quatro módulos: ACS, NACS, MS, MCS. Os módulos ACS e NACS são sub-divididos em dois níveis: top level (conhecimento explícito) e bottom level (conhecimento implícito). Sendo que cada nível possui seus próprios métodos de aprendizado.
Princípios Básicos
Os programas CLARION usados para controlar um agente baseiam-se em princípios gerais de uso de arquiteturas cognitivas. Quando desenvolvendo programas CLARION, deve-se ter em mente alguns procedimentos básicos para se criar os ambientes de simulação. Deve-se descrever as características e os objetos do mundo. Definir as ações e motivações (goals) que definirão como o agente irá interagir com o seu mundo. Inicializar as funções internas do agente para que ele possa tomar decisões baseadas em como o agente percebe o seu mundo. Prover mecanismos para capacitar o agente a interagir com seu mundo.
A arquitetura do CLARION disponibiliza uma Biblioteca (CLARIONLibrary.dll) que contém os recursos necessários para se desenvolver um agente CLARION. Para se utilizar os seu recursos adequadamente, é importante compreender as diferenças entre dois tipos de objetos disponíveis na arquitetura: objetos descritivos e objetos funcionais. Os objetos descritivos são usados para descrever as características de outros objetos, tais como, o próprio agente, seu mundo, suas metas e ações, seu conhecimento declarativo, entre outros. Esses objetos incluem: Dimension-value pairs, Agents, Chunks. Os objetos descritivos são armazenados no "mundo" (World) do agente. Existe um único objeto World que descreve o mundo do agente, inclusive o próprio agente.
Os objetos funcionais são objetos responsáveis por realizar alguma tarefa (função) dentro da arquitetura do CLARION. Esses objetos descrevem os processos e mecanismos que compõem as operações internas do agente. Tais objetos constituem-se componentes ou módulos. Alguns módulos disponíveis no CLARION: Implicit Decision Networks, Action Rules, Drives, Meta-cognitive Modules.
Usando o ACS
O programa HelloWorld - Simple.cs demonstra alguns conceitos básicos sobre a operação do módulo ACS. Este programa usa uma rede neural, do tipo backpropagation, com aprendizado do tipo reinforcement learning. Essa rede atua no bottom level do ACS. No top level, será usado o aprendizado RER (Rule Extraction and Refinement) para extrair as regras baseadas no aprendizado (reinforcement learning) do bottom level. A meta do agente será aprender as seguintes regras: "Se alguém disser 'hello' ou 'goodbye', para o agente, então o agente deverá responder 'hello' ou 'goodbye' respectivamente". No final da tarefa de aprendizado (treinamento da rede neural), o agente deverá ter aprendido, via aprendizado RER, as afirmações anteriores que serão representadas, no top level, por meio de regras. O único conhecimento a priori disponibilizado para o agente refere-se apenas às entradas e saídas descritas pelas afirmações.
A primeira tarefa, para construir este agente CLARION, é criar o mundo do agente. O mundo, World, do agente contém todas as informações que o agente precisa para perceber e atuar corretamente no seu mundo, além do próprio agente. As linhas de código abaixo são responsáveis por essa tarefa:
DimensionValuePair hi = World.NewDimensionValuePair("Salutation", "Hello");
DimensionValuePair bye = World.NewDimensionValuePair("Salutation", "Goodbye");
ExternalActionChunk sayHi = World.NewExternalActionChunk("Hello");
ExternalActionChunk sayBye = World.NewExternalActionChunk("Goodbye");
Agent John = World.NewAgent("John");
São criadas variáveis do tipo DimensionValuePair para representar as informações sensoriais do ambiente de simulação, mundo, do agente. O nome "Salutation" está associado aos valores "Hello" e "Goodbye" que o agente pode perceber de seu ambiente. As variáveis do tipo ExternalActionChunk representam as ações externas que o agente pode executar; neste caso, o agente pode responder "Hello" ou "Goodbye" para as saudações recebidas. O método NewAgent() cria um agente no mundo instanciado. Esse agente possui um nome, "John", para referênciá-lo no mundo. Até este passo, o agente não possui nenhum conhecimento a respeito do seu mundo e nem possui mecanismos funcionais para interagir com o mundo. As próximas linhas de código serão responsáveis pela configuração do agente criado:
SimplifiedQBPNetwork net = AgentInitializer.InitializeImplicitDecisionNetwork(John, SimplifiedQBPNetwork.Factory);
net.Input.Add(hi);
net.Input.Add(bye);
net.Output.Add(sayHi);
net.Output.Add(sayBye);
John.Commit(net);
net.Parameters.LEARNING_RATE = 1;
John.ACS.Parameters.PERFORM_RER_REFINEMENT = false;
O objeto SimplifiedQBPNetwork é uma rede neural backpropagation com aprendizado Q-learning. Essa rede neural constitui o objeto funcional responsável pela instanciação da IDN (Implicit Decision Network) no bottom level do ACS. O objeto AgentInitializer é responsável por inicializar os objetos funcionais que serão usados pelo agente para interagir com seu mundo. A rede neural (SimplifiedQBPNetwork) será ligada ao agente ("John") criado. Essa rede pertence ao agente e não pode ser usada por nenhum outro agente. O próximo passo será fornecer ao agente a capacidade de escolher ações, baseando-se nas informações sensórias recebidas do mundo. As entradas, variáveis Dimension-value pairs, e as saídas, variáveis Chunks, serão adicionadas à rede (SimplifiedQBPNetwork) por meio de suas interfaces de entrada e saída: Input e Output.
Os procedimentos discutidos anteriormente são responsáveis pela fase de inicialização da simulação. Nessa fase, os objetos funcionais são criados e configurados para serem usados pelo agente. Ao término dessa fase, é necessário informar ao agente que todos os objetos já estão disponíveis para uso. O método Commit() realiza essa tarefa. Após a realização dos procedimentos anteriores, pode ainda ser necessário realizar alguns ajustes. As duas últimas linhas do código, exibido anteriormente, realizam alguns desses ajustes. Os ajustes otimizam a performance do agente.
Depois que o agente e o seu mundo foram criados e configurados, a próxima etapa será configurar o ambiente de simulação do agente CLARION. O ambiente deve agir como um intermediário entre o agente e o seu mundo. As seguintes informações deverão ser providas pelo ambiente de simulação. Especificar para o agente a informação sensória que ele percebe num dado ciclo de percepção-ação. Capturar e gravar a ação escolhida pelo agente. Atualizar o estado do mundo, baseado nas ações do agente. Prover um retorno para o agente a respeito da eficiência, boa ou ruim, de suas ações. Rastrear o desempenho do agente para ser reportado no final da realização das tarefas. As linhas de código abaixo auxiliam a interação do agente com o seu mundo:
Random rand = new Random();
SensoryInformation si;
ExternalActionChunk chosen;
A variável SensoryInformation captura as informações sensoriais do mundo, enviando-as para o agente. A variável ExternalActionChunk captura as decisões, ações, tomadas pelo agente, que serão aplicadas no mundo. Um número aleatório (Random) será usado para simular as mudanças sensorias do mundo do agente. Um loop do tipo for será usado para simular cada passo, número de tentativas (NumberTrials = 10000), do ciclo de percepção-ação do agente, na qual a ação escolhida será capturada e uma informação será retornada (sobre a eficiência da ação tomada) e gravada. As próximas linhas de código são executadas dentro do loop responsável pelo ciclo de decisão do agente:
si = World.NewSensoryInformation(John);
if (rand.NextDouble() < .5)
{
si.Add(hi, John.Parameters.MAX_ACTIVATION);
si.Add(bye, John.Parameters.MIN_ACTIVATION);
}
else
{
si.Add(hi, John.Parameters.MIN_ACTIVATION);
si.Add(bye, John.Parameters.MAX_ACTIVATION);
}
John.Perceive(si);
chosen = John.GetChosenExternalAction(si);
O método NewSensoryInformation() fornece um objeto para capturar as informações sensórias sobre o mundo do agente. Esse objeto é de uso exclusivo do agente (John) e informa ao agente, além do estado do mundo, as informações sobre os estados internos (goals, drives, working memory, etc) do agente. A estrutura if-else configura as duas possibilidades de ativação das informações sensórias. Isto é, se o agente percebe a mensagem "Hello" ou "Goodbye". Essa escolha será aleatória. O próximo passo é fazer o agente perceber as informações sensórias captadas do mundo, e escolher uma ação adequada. Os métodos Perceive() e GetChosenExternalAction() são responsáveis por essas tarefas.
Após escolher e capturar uma ação, o passo seguinte será determinar as consequências da ação tomada, gravar os resultados e "recompensar" ou "punir" o agente. Devem ser consideradas as duas saídas (ações) possíveis: o agente responder "Hello" (chosen == sayHi) ou "Goodbye" (chosen == sayBye). Para cada ação possível, devem ser consideradas as informações sensórias percebidas pelo agente. Isto é, se o agente percebeu uma mensagem "Hello" (si[hi] == John.Parameters.MAX_ACTIVATION) ou "Goodbye" (si[bye] == John.Parameters.MAX_ACTIVATION). A figura abaixo ilustra um trecho de código referente à uma resposta do agente:

O método ReceiveFeedback() retorna uma resposta, para o agente, sobre a ação tomada. Essa resposta será compensatória (1.0), quando o agente responder corretamente, e de punição (0.0), quando o agente responder errôneamente. O agente também recebe um retorno sobre a informação sensória captada, relacionada à ação tomada. A arquitetura do CLARION será responsável pelo aprendizado do agente (bottom level) mediante as respostas retornadas para cada par de informação percepção-ação. As respostas retornadas ao agente estarão dentro da faixa entre 0 e 1.
O último passo a ser tomado, após o término da simulação, é destruir o agente criado. O método Die() realiza essa tarefa. Embora o agente seja eliminado do mundo (World) criado, suas configurações internas ainda podem ser acessadas e gravadas se necessário. A figura abaixo exibe os resultados gerados pela simulação do ambiente deste agente:

A figura mostra que 98% das tentativas de resposta do agente forma bem sucedidas. Ou seja, o agente aprendeu a responder "Hello" para uma saudação de "Hello" e "Goodbye" para uma saudação de "Goodbye". Assim, no top level, essas regras foram geradas a partir do aprendizado bottom level.
Usando a Goal Structure
A Goal Structure (GS) é responsável por armazenar as metas do agente. As metas são descritas por objetos, do mundo (World), do tipo GoalChunk. A Goal Structure faz parte do top level do módulo MS; no entanto, todas as interações entre a Goal Structure e o ambiente de simulação são realizadas pela classe Agent. As linhas de código abaixo descrevem algumas operações relacionadas com o uso da GS:
IEnumerable<GoalChunk> gsContents = (IEnumerable<GoalChunk>)John.GetInternals(Agent.InternalWorldObjectContainers.GOAL_STRUCTURE);
GoalChunk currentGoal = John.CurrentGoal;
GoalChunk g = World.NewGoalChunk();
John.MS.Parameters.CURRENT_GOAL_ACTIVATION_OPTION =MotivationalSubsystem.CurrentGoalActivationOptions.FULL;
John.MS.Parameters.GOAL_STRUCTURE_BEHAVIOR_OPTION =MotivationalSubsystem.GoalStructureBehaviorOptions.STACK;
É possível visualizar o conteúdo da GS por meio do método GetInternals(). Pode-se também capturar a meta atual do agente por meio da propriedade CurrentGoal. O método NewGoalChunk() cria um chunk, no mundo (World), para representar a meta do agente. É possível ajustar alguns parâmetros para "afinar" o comportamento da GS. As duas últimas linhas do código acima realizam alguns desses ajustes. Pode-se ajustar o comportamento da GS para que se comporte como uma lista ou uma pilha (STACK). Também pode-se ajustar o nível de ativação da meta atual (CURRENT_GOAL). As próximas linhas de código demonstram como inicializar e usar uma meta (goal) como parte de um componente:
GoalChunk g = World.NewGoalChunk();
Agent John = World.NewAgent("John");
SimplifiedQBPNetwork net =AgentInitializer.InitializeImplicitDecisionNetwork(John,SimplifiedQBPNetwork.Factory);
net.Input.Add(g);
O exemplo de código acima cria uma meta, um agente e uma rede neural (SimplifiedQBPNetwork) e usa a meta criada como parte da entrada (Input) da rede. É importante perceber que todas as metas, no mundo, são sempre especificadas para fazer parte da informação sensória interna. Portanto, as metas sempre serão ativadas quando o agente perceber (SensoryInformation) algo.
As metas podem ser ativadas manualmente, na GS, ou por meio de action chunks. As linhas de código abaixo exemplificam essas ações:
John.SetGoal(g, 1);
John.ResetGoal(g);
GoalStructureUpdateActionChunk gAct = World.NewGoalStructureUpdateActionChunk();
gAct.Add(GoalStructure.RecognizedActions.SET, g);
net.Output.Add(gAct);
Para ativar (ou adicionar) uma meta, manualmente, na GS, basta chamar o método SetGoal() do agente. São especificados dois itens: a meta a ser ativada e o seu nível de ativação. Para desativar (ou remover) uma meta da GS do agente, basta chamar o método ResetGoal().
A outra forma de ativar uma meta é por meio do uso de goal actions no ACS. As últimas linhas do código acima exemplificam esse procedimento. Na teoria do CLARION, as ações que afetam a GS são chamadas goal actions. No exemplo acima, a goal action (gAct) é um action chunk que insere a meta (g) na GS do agente. A enumeração RecognizedActions define uma lista de comandos possíveis de serem executados na GS. Há quatro comandos possíveis. O comando SET adiciona a meta na GS. O comando RESET remove a meta da GS. O comando RESET_ALL remove todas as metas da GS. E o comando SET_RESET combina o comando anterior com o comando SET. Para permitir que um componente, neste caso a rede neural (net), use a ação criada (gAct), essa ação deve ser adicionada à saída (Output) do componente. Quando o ACS selecionar a goal action (gAct) criada, a arquitetura irá executar os comandos especificados por essa ação (goal action).
ACS Nível Intermediário
Algumas vezes pode ser necessário realizar procedimentos para sintonizar algumas características do agente, com o intuito de otimizar sua performance na execução das tarefas. Um exemplo desse tipo de procedimento é a classe RefineableActionRule que implementa um tipo de regra ajustável, normalmente extraída pelo mecanismo de RER do CLARION. Alguns parâmetros dessa classe permitem ajustar a frequência na qual alguns processos (especialização e generalização) ocorrem. As linhas de código abaixo exemplificam esses ajustes:
RefineableActionRule.GlobalParameters.SPECIALIZATION_THRESHOLD_1 = -.6;
RefineableActionRule.GlobalParameters.GENERALIZATION_THRESHOLD_1 = -.2;
A biblioteca do CLARION também disponibiliza parâmetros relacionados à forma de aprendizado do agente. É possível "desligar" alguns tipos de aprendizado, tais como, refinamento de regras, bottom-up learning ou extração de regras, top-down learning e/ou aprendizado bottom level. As linhas de código abaixo exemplificam alguns desses procedimentos:
ActionCenteredSubsystem.GlobalParameters.PERFORM_RER_REFINEMENT = false;
ActionCenteredSubsystem.GlobalParameters.PERFORM_RULE_EXTRACTION = false;
ActionCenteredSubsystem.GlobalParameters.PERFORM_TOP_DOWN_LEARNING = false;
ActionCenteredSubsystem.GlobalParameters.PERFORM_BL_LEARNING = false;
Ao se ajustar os parâmetros globais, conforme as linhas de código acima, deve-se observar que esses parâmetros devem ser ajustados antes de se instanciar o agente (ou o componente relacionado aos parâmetros ajustados). Alguns parâmetros podem ser ajustados de forma genérica ou específica, isto é, o ajuste irá afetar apenas uma classe específica ou várias classes relacionadas a esse parâmetro. As linhas de código abaixo exibem essas diferenças:
Rule.GlobalParameters.POSITIVE_MATCH_THRESHOLD = .75;
IRLRule.GlobalParameters.POSITIVE_MATCH_THRESHOLD = .75;
No primeiro caso, a classe Rule engloba as classes RefineableActionRule, IRLRule, AssociativeRule, dentre outras classes que derivam dela. Portanto, qualquer parâmetro que for ajustado, dessa classe, também terá efeito sobre as outras classes relacionadas à classe Rule. No segundo exemplo, acima, o parâmetro ajustado terá efeito apenas (especificamente) sobre uma única classe.
Também é possível alterar parâmetros localmente, ou seja, alterar alguns parâmetros apenas para um agente instanciado, sem afetar outros agentes também criados. A linha de código abaixo ilustra isso:
John.ACS.Parameters.PERFORM_RER_REFINEMENT = false;
Outro componete do ACS configurável é a Memória de Trabalho (Working Memory). A memória de trabalho é usada pelo agente para armazenar todo o conhecimento do mundo, isto é, declarative chunks, action chunks previamente usados, dentre outros. Apesar de encontrar-se dentro do módulo ACS, toda a interação do ambiente de simulação com a memória de trabalho é configurada pelo agente (classe Agent), como ilustra a linha de código abaixo:
IEnumerable<Chunk> wmContents =
(IEnumerable<Chunk>)John.GetInternals(Agent.InternalWorldObjectContainers.WORKING_MEMORY);
O método GetInternals() permite visualizar o conteúdo da memória de trabalho do agente. A memória de trabalho armazena chunks que possuem informações a respeito do mundo. Os objetos do mundo (chunks) podem ser adicionados à memória de trabalho manualmente ou por meio de objetos do tipo WorkingMemoryUpdateActionChunk. As linhas de código abaixo exemplificam esses métodos:
John.SetWMChunk(ch, 1);
John.ResetWMChunk(ch);
WorkingMemoryUpdateActionChunk wmAct = World.NewWorkingMemoryUpdateActionChunk();
wmAct.Add(WorkingMemory.RecognizedActions.SET, ch);
net.Output.Add(wmAct);
Para adicionar, manualmente, um chunk na memória de trabalho do agente, basta invocar o método SetWMChunk() do agente. Deve ser passado um parâmetro a respeito do nível de ativação do chunk. Para remover um chunk, basta usar o método ResetWMChunk(). Os action chunks também podem ser usados para atualizar a memória de trabalho durante a simulação do ambiente do agente. Esses action chunks (WorkingMemoryUpdateActionChunk) possuem informações sobre como será realizado o procedimento de atualização da memória de trabalho. O objeto wmAct cria uma "ação" que mantém atualizado o conteúdo do chunk ch criado na memória de trabalho do agente. Em seguida, pode-se configurar o componente que usará essa ação, no caso, uma rede neural (net). Sempre que o ACS selecionar esse action chunk, o sistema irá executar os comandos especificados por essa ação.
MS & MCS Nível Intermediário
Os drives são usados pelos módulos Motivacional (MS) e Metacognitivo (MCS) para realizar alguns procedimentos de tomada de decisão. Os drives usam fatores relacionados tanto às informações externas quanto aos estados internos do agente. Esses fatores são responsáveis pela ativação do drive. Os drives encontram-se no bottom level do módulo MS. Um drive pode pertencer a um dos seguintes grupos: approach drives, avoidance drives, both drives, unspecified drives. As linhas de código abaixo demonstram a criação de um drive e a especificação de seu grupo:
FoodDrive food = AgentInitializer.InitializeDrive(John, FoodDrive.Factory, .5);
FoodDrive foodDrive = AgentInitializer.InitializeDrive
(John, FoodDrive.Factory, .5, MotivationalSubsystem.DriveGroupSpecifications.BOTH);
A primeira linha de código, acima, cria um drive do tipo "comida" (FoodDrive) para o agente (John) criado. Há a opção de se alterar o grupo ao qual o drive pertence, conforme ilustra a última instrução do código acima. No entanto, esse procedimento não precisa ser realizado após criar-se um drive.
Após criar um drive, o próximo passo necessário é criar um componente do tipo ImplicitComponent dentro do drive. O ideal é usar uma rede "pré-treinada" (BPNetwork) como componente implícito. No entanto, um componete mais simples de ser configurado é o componente DriveEquation. A linha de código seguinte exemplifica o uso desse componente:
DriveEquation foodEq =
AgentInitializer.InitializeDriveComponent(foodDrive, DriveEquation.Factory);
A equação usada para calcular a "força" do drive baseia-se em variáveis do tipo typical drive inputs. Essas variáveis são parâmetros relacionados ao drive (UNIVERSAL_GAIN, DRIVE_GAIN, BASE_LINE) e ao MS (SYSTEM_GAIN). Podem ser usados dimension-value pairs para representar essas variáveis. Se o componente usado em conjunto com o drive possuir qualquer uma dessas variáveis (typical inputs), o sistema automaticamente preencherá essas variáveis com os valores apropriado às suas entradas. Após criar o drive e instanciar seu componente (DriveEquation), o próximo passo é usar o comando Commit() para indicar a permissão de uso do drive e ligá-lo ao agente criado. As linhas de código abaixo ilustram esses procedimentos:
foodDrive.Commit(foodEq);
John.Commit(foodDrive);
Ao se usar typical inputs, é necessário especificar a ativação do parâmetro STIMULUS da entrada (input). As linhas de código abaixo demonstram o procedimento para ativar esse parâmetro para o drive de "comida" num objeto de informação sensória do agente:
si = World.NewSensoryInformation(John);
si[typeof(FoodDrive), FoodDrive.MetaInfoReservations.STIMULUS] = 1;
John.Perceive(si);
As informações discutidas até este ponto relatam os procedimentos para configurar um drive no bottom level do MS. Para se usar o drive configurado, será preciso implementar alguns módulos do MCS que irão atuar baseados nos drives criados. Um módulo MCS age como um "mini-ACS", isto é, as ações do MCS manipulam os aspectos internos do agente. Um módulo do MCS muito usado é o GoalSelectionModule. As linhas de código abaixo exibem o procedimento para inicializar esse módulo dentro do agente criado:
GoalSelectionModule gsm =
AgentInitializer.InitializeMetaCognitiveModule(John, GoalSelectionModule.Factory);
GoalSelectionEquation gse =
AgentInitializer.InitializeMetaCognitiveDecisionNetwork(gsm, GoalSelectionEquation.Factory);
As últimas linhas acima demonstram como inicializar um objeto GoalSelectionEquation dentro do bottom level do GoalSelectionModule. A camada de entrada do objeto GoalSelectionEquation pode conter drive strength dimension-value pairs ou outros tipos de objetos descritivos do mundo. A camada de saída, no entanto, pode conter apenas goal structure update action chunks. Após configurar o objeto GoalSelectionEquation, ele irá calcular a "força" da meta (goal) que o módulo GoalSelectionModule usará para selecionar um GoalStructureUpdateActionChunk. A meta associada com esse action chunk será colocada ou removida na GoalStructure pela inicialização de um goal structure update event dentro do sistema. Esse evento influenciará o MS, que executará a atualização baseando-se nas especificações da ação. As linhas de código abaixo finalizam os procedimentos de configuração do módulo meta-cognitivo para ser usado pelo agente:
gse.Input.Add(foodDrive.GetDriveStrength());
GoalStructureUpdateActionChunk gAct = World.NewGoalStructureUpdateActionChunk();
gAct.Add(GoalStructure.RecognizedActions.SET_RESET, g);
gse.Output.Add(gAct);
SomeGoalSelectionEquation.SetRelevance(SomeGoalStructureUpdateActionChunk,
SomeDrive or SomeWorldObject, SomeRelevanceValue);
gse.SetRelevance(gAct, foodDrive, 1);
gsm.Commit(gse);
John.Commit(gsm);
A primeira linha do código acima adiciona o drive strength dimension-value pair do FoodDrive à camada de entrada do GoalSelectionEquation. Em seguida, as próximas três linhas inicializam o GoalStructureUpdateActionChunk que adiciona uma meta (g) na camada de saída do GoalSelectionEquation. A linha seguinte informa a relevância que cada entrada tem sobre cada saída. O próximo passo será relacionar o FoodDrive ao GoalStructureUpdateActionChunk. Para finalizar, o componente configurado será associado ao módulo meta-cognitivo, e este ao agente criado.
Usando o NACS
O NACS disponibiliza um mecanismo de raciocínio, conforme ilustrado no exemplo do Reasoner – Simple.cs. Abaixo, seguem as linhas de código do método Main desse programa:
public static void Main()
{
InitializeWorld();
Agent reasoner = World.NewAgent();
//Adds all of the declarative chunks to the GKS
foreach (DeclarativeChunk dc in chunks)
reasoner.AddKnowledge(dc);
//Initializes the Hopfield network in the bottom level of the NACS
HopfieldNetwork net = AgentInitializer.InitializeAssociativeMemoryNetwork
(reasoner, HopfieldNetwork.Factory);
//Species all of the dimension-value pairs as nodes for the Hopfield network
net.Nodes.AddRange(dvs);
//Commits the Hopfield network
reasoner.Commit(net);
//Encodes the patterns into the Hopfield network
EncodeHopfieldNetwork(net);
//Sets up the rules in the top level of the NAS
SetupRules(reasoner);
//Specifies that the NACS should perform 2 reasoning iterations
reasoner.NACS.Parameters.REASONING_ITERATION_COUNT = 2;
//Sets the conclusion threshold to 1
//(indicating that only fully matched conclusions should be returned)
reasoner.NACS.Parameters.CONCLUSION_THRESHOLD = 1;
//Initiates reasoning and outputs the results
DoReasoning(reasoner);
//Kills the reasoning agent
reasoner.Die();
Console.WriteLine("Press any key to exit");
Console.ReadKey();
}
Esse método realiza a chamada de outro método, InitializeWorld(), que inicializa o mundo (World) com 30 variáveis do tipo DimensionValuePair e 5 variáveis do tipo DeclarativeChunk. O próximo passo do método Main adiciona os DeclarativeChunk's criados ao GKS (General Knowledge Store) do NACS, usando o método AddKnowledge() do agente.
Em seguida, será criada uma rede do tipo HopfieldNetwork que será inicializada na AMN (Associative Memory Network) do NACS, pelo método InitializeAssociativeMemoryNetwork(). Os DimensionValuePair's criados serão adicionados como nós (Nodes.AddRange()) da rede. Essa rede é do tipo auto-associativa, ou seja, a partir dos nós (conhecimento) da rede, o conhecimento codificado na rede será reconstruído. O conhecimento que se deseja codificar na rede são os DeclarativeChunk's que formam cinco padrões conforme ilustra o código abaixo:
static int [][] patterns =
{
new int [] {1, 3, 5, 11, 13, 16, 19, 23, 27},
new int [] {3, 6, 7, 8, 12, 15, 20, 21, 26},
new int [] {2, 4, 8, 9, 11, 17, 18, 24, 30},
new int [] {1, 4, 10, 12, 15, 17, 19, 22, 29},
new int [] {3, 5, 8, 10, 14, 18, 20, 25, 28}
};
O método InitializeWorld(), descrito abaixo, é responsável por associar os padrões acima (números inteiros em cada padrão) com os valores de cada DimensionValuePair. Cada um dos sub-arrays acima especifica um diferente padrão de ativação para as 30 variáveis criadas.
static void InitializeWorld()
{
//Initialize the dimension-value pairs
for (int i = 1; i <= nodeCount; i++)
{
dvs.Add(World.NewDimensionValuePair("Dim", i));
}
//Initializes the declarative chunks
for (int i = 0; i < patterns.Length; i++)
{
//Generates a declarative chunk and specifies that the semantic label associated with the declarative chunk should NOT be added to the
//dimension-value pairs of that chunk
DeclarativeChunk dc =
World.NewDeclarativeChunk(i, addSemanticLabel:false);
//Adds the appropriate dimension-value pairs (as indicated by the "patterns" array) for each declarative chunk pattern representation
foreach (var dv in dvs)
{
if (patterns[i].Contains(dv.Value))
{
dc.Add(dv);
}
}
//Adds the declarative chunk to the chunks list
chunks.Add(dc);
}
}
O método EncodeHopfieldNetwork(), chamado em Main, codifica os padrões na rede e testa a acurácia da codificação realizada. Esse método está descrito abaixo. O método Encode() codifica os padrões baseando-se num conjunto de dados (NewDataSet()).
static void EncodeHopfieldNetwork(HopfieldNetwork net)
{
//Tracks the accuracy of correctly encoded patterns
double accuracy = 0;
//Continue encoding until all of the patterns are successfully recalled
do
{
//Specifies to use the "N spins" transmission option during the encoding phase
net.Parameters.TRANSMISSION_OPTION =
HopfieldNetwork.TransmissionOptions.N_SPINS;
List<ActivationCollection> sis = new List<ActivationCollection>();
foreach (DeclarativeChunk dc in chunks)
{
//Gets a new "data set" object (to be used by the Encode method to encode the pattern)
ActivationCollection si = ImplicitComponentInitializer.NewDataSet();
//Sets up the pattern
si.AddRange(dc, 1);
sis.Add(si);
}
//Encodes the pattern into the Hopfield network
ImplicitComponentInitializer.Encode(net, sis);
//Specifies to use the "let settle" transmission option during the testing phase
net.Parameters.TRANSMISSION_OPTION =
HopfieldNetwork.TransmissionOptions.LET_SETTLE;
//Tests the net to see if it has learned the patterns
accuracy = ImplicitComponentInitializer.Encode(net, sis, testOnly: true);
Console.WriteLine(((int)accuracy * 100) + "% of the patterns were successfully recalled.");
} while (accuracy < 1);
}
Após codificar o conhecimento no bottom level do NACS, o passo seguinte será gerar e adicionar as regras associativas (associative rules) no top level. Neste exemplo, devem ser criadas cinco regras para os chunks criados. Se for apresentado o DeclarativeChunk representando o padrão 1, o top level deve concluir qual o DeclarativeChunk que representa adequadamente o padrão 2. As linhas de código abaixo são responsáveis por esse procedimento de geração de regras:
static void SetupRules(Agent reasoner)
{
//Iterates through each of the chunks (except the last one, for obvious reasons) and creates an associative rule using that chunk as the
//condition, and the next chunk in the chunks list as the conclusion.
for (int i = 0; i < chunks.Count - 1; i++)
{
//Initializes the rule
RefineableAssociativeRule ar =
AgentInitializer.InitializeAssociativeRule(reasoner,
RefineableAssociativeRule.Factory, chunks[i + 1]);
//Specifies that the current chunk must be activated as part of the condition for the rule
ar.GeneralizedCondition.Add(chunks[i], true);
//Commits the rule
reasoner.Commit(ar);
}
}
A etapa final é responsável por gerar o "raciocínio" do agente. Para isto, será usado o método PerformReasoning() disponibilizado pelo NACS do agente; este método ativa o mecanismo de geração de raciocínio do NACS. Será necessário especificar a entrada que será usada para iniciar o raciocínio. As linhas de código abaixo exibem o método responsável por esse procedimento:
static void DoReasoning(Agent reasoner)
{
int correct = 0;
//Iterates through each pattern
foreach (DeclarativeChunk dc in chunks)
{
//Gets an input to use for reasoning. Note that the World.GetSensoryInformation method can also be used here
ActivationCollection si = ImplicitComponentInitializer.NewDataSet();
int count = 0;
//Sets up the input
foreach (DimensionValuePair dv in dvs)
{
if (((double)count / (double)dc.Count < (1 - noise)))
{
if (dc.Contains(dv))
{
si.Add(dv, 1);
++count;
}
else
si.Add(dv, 0);
}
else
si.Add(dv, 0); //Zeros out the dimension-value pair if "above the noise level"
}
Console.WriteLine("Input to reasoner:\r\n" + si);
Console.WriteLine("Output from reasoner:");
//Performs reasoning based on the input. The conclusions returned from this method will be in the form of a
//collection of "Chunk Tuples." A chunk tuple is simply just a chunk combined with its associated activation.
var o = reasoner.NACS.PerformReasoning(si);
//Iterates through the conclusions from reasoning
foreach (var i in o)
{
Console.WriteLine(i.CHUNK);
if (i.CHUNK == dc)
correct++;
}
}
Console.WriteLine("Retrieval Accuracy: " +
(int)(((double)correct / (double)chunks.Count) * 100) + "%");
}
O método PerformReasoning() retorna a conclusão do raciocínio na forma de Chunk Tuples que são chunks de conclusão associados com suas ativações. Como entradas são usadas reconstruções parciais, com ruídos (noise), de cada um dos cinco padrões.
Após rodar este exemplo, o agente deve exibir o seguinte comportamento. Na primeira iteração, o bottom level irá completar o padrão de entrada parcial. Na segunda iteração, o top level irá receber as conclusões associadas com o padrão reconstruído do bottom level e irá concluir qual deve ser o padrão seguinte. Em seguida, serão gerados os chunks de conclusão para cada iteração do raciocínio. Por exemplo, se a entrada for baseada na reconstrução parcial do padrão 1, as conclusões do raciocício seriam os DeclarativeChunk's associados aos padrões 1 e 2.
Customização Nível Básico
A biblioteca do CLARION disponibiliza alguns algoritmos para controlar o comportamento do agente criado. Caso seja necessário, a biblioteca também disponibiliza a opção de customizar o comportamento do agente, permitindo a re-escrita de alguns algoritmos por meio do uso de métodos delegados. As linhas de código abaixo exibem um exemplo simples do uso de delegados:
public delegate bool EligibilityChecker
(SensoryInformation currentInput = null, ClarionComponent target = null);
public bool Custom_EligibilityCheck (SensoryInformation currentInput = null,
ClarionComponent target = null)
{
... // Do operations to determine if the target component is eligible
return true or false;
}
O primeiro método acima exibe a assinatura para o método delegado que verifica a eligibilidade de um componente. O segundo método implementa o método delegado que usa as mesmas entradas e retorna um valor do mesmo tipo daquele definido pela assinatura do método. Este método delegado permite que sejam feitas verificações internas adicionais para atestar as condições que definem quando um componente deve ser usado. Após criar o método delegado, este deve ser especificado para ser usado por um componente em particular. As linhas de código seguintes ilustram essa operação:
BPNetwork net = AgentInitializer.InitializeImplicitDecisionNetwork
(John, BPNetwork.Factory, (EligibilityChecker)Custom_EligibilityCheck);
Dependendo do tipo de tarefa que o agente precise executar, pode ser necessário a criação de regras customizadas. Esse tipo de regra é mais complexo do que as regras implementáveis pela classe RefineableActionRule. Neste caso, a biblioteca do CLARION disponibiliza duas classes para lidar com a criação e uso dessas regras mais complexas: IRLRule e FixedRule. Para inicializar um objeto de uma dessas classes de regras, será necessário definir um delegado (exibido abaixo) para auxiliar o sistema na determinação da eligibilidade da regra, ou seja, se a regra é eligível para a recomendação de uma ação num dado momento de execução do agente.
public delegate double SupportCalculator
(SensoryInformation currentInput, Rule target = null);
O uso de uma regra do tipo IRLRule se faz necessário quando um certo fator de condição da regra for, ele próprio, condicionado por outro fator daquela mesma condição da regra. Por exemplo, no seguinte caso: If {dim1, a} OR {dim2, c}, but NOT {dim2, d} then recommend the {do_something} action, otherwise don’t recommend it. Onde "{dim, ...}" são variáveis do tipo Dimension-Value Pair. As linhas de código abaixo exibem o método delegado que captura as condições necessárias desta regra:
public double CalculateSupport_IRL(SensoryInformation si, Rule r)
{
var d1 = from d in si
where d.WORLD_OBJECT.AsDimensionValuePair.Dimension == "dim1" &&
r.GeneralizedCondition[d.WORLD_OBJECT] == true
select d;
return (r.GeneralizedCondition["dim2","c"] == true && si["dim2", "c"] > 0 &&
r.GeneralizedCondition["dim2", "d"] == false && si["dim2", "d"] == 0)?
d1.Max(e => e.ACTIVATION) : 0;
}
A primeira linha do código acima captura todos os Dimension-Value Pair's, em dim1, que fazem parte da condição. A segunda linha do código retorna a máxima ativação (para capturar a operação OR) dos Dimension-Value Pair's que foram encontrados na primeira linha, se {dim2, c} é ativado e {dim2, d} não for ativado. Depois de definir o método delegado, agora a regra IRLRule pode ser definida e usada pelo agente. As linhas de código seguintes realizam as etapas de inicialização da regra, configuração das condições iniciais da regra, e associação (commit) da regra criada ao agente criado:
// During the initialization method:
IRLRule rule1 = AgentInitializer.InitializeActionRule
(John, IRLRule.Factory, some_action, SupportDelegate);
DimensionValuePair dv1 = World.NewDimensionValuePair(“dim1”, “a”);
DimensionValuePair dv2 = World.NewDimensionValuePair(“dim1”, “b”);
DimensionValuePair dv3 = World.NewDimensionValuePair(“dim2”, “c”);
DimensionValuePair dv4 = World.NewDimensionValuePair(“dim2”, “d”);
...
// At some other point in your code:
public SupportCalculator SupportDelegate
{
get
{ return CalculateSupport_IRL; }
}
// Elided rule initialization (see above)
rule1.GeneralizedCondition.Add(dv1, true);
rule1.GeneralizedCondition.Add(dv2, false);
rule1.GeneralizedCondition.Add(dv3, true);
rule1.GeneralizedCondition.Add(dv4, false);
John.Commit(rule);
Uma regra do tipo FixedRule pode ser usada quando parte do algoritmo para determinar o suporte de uma regra requer que seja efetuada algum tipo de tradução matemática de partes da informação sensória. Por exemplo, no seguinte caso: If {operator, +} and {digit1, x} + {digit2, y} > 9, then recommend the {carryover} action, otherwise don’t recommend it. O seguinte método delegado captura as condições desta regra:
public double CalculateSuppot_FR(SensoryInformation si, Rule r)
{
if (si["operator", "+"] > 0)
{
var d1 = (from d in si
where d.WORLD_OBJECT.AsDimensionValuePair.Dimension == "digit1"
select d).OrderByDescending(e => e.ACTIVATION).First();
var d2 = (from d in si
where d.WORLD_OBJECT.AsDimensionValuePair.Dimension == "digit2"
select d).OrderByDescending(e => e.ACTIVATION).First();
if (((int)d1.WORLD_OBJECT.AsDimensionValuePair.Value.AsIComparable) +
((int)d2.WORLD_OBJECT.AsDimensionValuePair.Value.AsIComparable) > 9)
return 1;
else return 0;
}
else
return 0;
}
A primeira declaração if encontra os "dígitos" (digit1, digit2) mais ativados. Na sequência, são verificados se o operador "+" está ativado na informação sensória, e, se a soma dos dois dígitos requer a ação de "carry-over". As linhas de código abaixo exibem os procedimentos para inicializar a regra criada:
// During the initialization method:
FixedRule rule = AgentInitializer.InitializeActionRule
(John, FixedRule.Factory, carry_action, SupportDelegate);
John.Commit(rule);
...
// At some other point in your code:
public SupportCalculator SupportDelegate
{
get
{ return CalculateSupport_FR; }
}
A biblioteca do CLARION também disponibiliza um método delegado que permite criar uma equação personalizada para ser usada por uma rede neural, por exemplo, no bottom level do ACS. As linhas de código seguintes ilustram esse procedimento:
public delegate void Equation
(ActivationCollection input, ActivationCollection output);
public void LinearEquation
(ActivationCollection input, ActivationCollection output)
{
output["Variable", "Y"] = input["Variable", "X"];
}
GenericEquation eq = AgentInitializer.InitializeImplicitDecisionNetwork
(John, GenericEquation.Factory, (Equation)LinearEquation);
Acima são exibidas a assinatura do método delegado, um exemplo de equação personalizada, e, a inicialização dessa equação para ser usada pelo agente. As próximas linhas de código definem as entradas e saídas da equação e associam-na ao agente criado:
public void InitializeAgent()
{
DimensionValuePair x = World.NewDimensionValuePair("Variables", "X");
DimensionValuePair y = World.NewDimensionValuePair("Variables", "Y");
Agent John = World.NewAgent("John");
... //Elided additional agent initialization
GenericEquation eq = AgentInitializer.InitializeImplicitDecisionNetwork
(John, GenericEquation.Factory, (Equation)LinearEquation);
eq.Input.Add(x);
eq.Output.Add(y);
eq.Parameters.MIN_ACTIVATION = -10;
eq.Parameters.MAX_ACTIVATION = 10;
John.Commit(eq);
}
Customização Nível Avançado
Os quatro módulos da arquitetura do CLARION utilizam componentes específicos disponibilizados pela biblioteca do CLARION, conforme descrito a seguir.
O módulo ACS é definido pela classe ActionCenteredSubsystem. O bottom level do ACS aceita componentes que estendem a classe ImplicitComponent. O top level do ACS aceita três tipos de regras derivadas das classes RefineableActionRule, IRLRule, ou FixedRule.
O módulo NACS é definido pela classe NonActionCenteredSubsystem. O bottom level do NACS aceita componentes que estendem a classe ImplicitComponent. O top level do NACS aceita componentes que estendem a classe AssociativeRule.
O módulo MS é definido pela classe MotivationalSubsystem. O bottom level do MS aceita componentes que derivam da classe Drive. Esta classe espera componentes que derivem da classe ImplicitComponent. O top level do MS não trabalha com um tipo específico de componente. Ao invés disso, este nível trabalha com o conceito de metas (goals).
O módulo MCS é definido pela classe MetaCognitiveSubsystem. O bottom level do MCS aceita componentes que estendem a classe ImplicitComponent. O top level do MCS aceita componentes que derivam da classe RefineableActionRule.
A biblioteca do CLARION também disponibiliza algumas interfaces úteis que informam ao sistema as capacidades de um componente. A interface ITrainable informa que o componente é treinável, enquanto que a interface IReinforcementTrainable informa que o componente pode usar reinforcement learning. No caso do uso de Q-learning, essa informação é disponibilizada pela interface IUsesQLearning. As definições de regras também são disponibilizadas por meio de interfaces: IExtractsRules informa que o componente pode extrair regras; IRefineable indica que o componente pode ser refinado.
O CLARION permite criar componentes customizados definidos pelo usuário. Para implementar um componente customizado são necessárias três coisas que todo componente deve ter. Uma classe Factory que é usada pela classe AgentInitializer para gerar o componente. Uma classe Parameters que armazena todos os parâmetros ajustáveis do componente, para melhorar sua performance. Um método Commit e um método Retract que adicionam e removem, respectivamente, o componente (ao adicionar o componente, este não poderá ser editado a não ser que seja retraído para fazê-lo editável).
A classe Factory deve implementar uma das seguintes interfaces: IimplicitComponentFactory (caso o componente seja um ImplicitComponent), IActionRuleFactory (caso o componente seja uma ActionRule), IAssociativeRuleFactory (caso o componente seja uma AssociativeRule), IDriveFactory (caso o componente seja um Drive). As linhas de código abaixo demonstram um exemplo de criação e de uso de um componente customizado. Esse exemplo cria um componente do tipo ImplicitComponent e inicializa-o no bottom level do ACS.
public class SomeCustomComponent : ImplicitComponent
{
public class SomeCustomComponentFactory :
IimplicitComponentFactory<SomeCustomComponent>{
public SomeCustomComponent Generate(params dynamic[] parameters){
//Elided code for parsing-out the parameters
return new SomeCustomComponent();
}
}
protected SomeCustomComponent()
: base (new
ImplicitComponentParameters(ImplicitComponent.GlobalParameters)) { }
private static SomeCustomComponentFactory factory =
new SomeCustomComponentFactory();
public static SomeCustomComponentFactory Factory{
get{
return factory;
}
}
}
SomeCustomComponent comp =
AgentInitializer.InitializeImplicitDecisionNetwork
(SomeAgent, SomeCustomComponent.Factory);
Os parâmetros de uma classe podem ser acessados e manipulados globalmente ou localmente. A implementação de uma classe Parameters permite a realização desses ajustes. O código acima implementa os parâmetros globais (ImplicitComponent.GlobalParameters) do componente. Os parâmetros locais do componente podem ser implementados como classes internas ao componente, conforme exemplo seguinte:
public class SomeCustomComponent : ImplicitComponent
{
public class SomeCustomComponentParameters : ImplicitComponentParameters{
...
}
... //Elided factory class, etc.
}
Para finalizar a implementação do componente customizado, resta implementar os métodos Commit e Retract. As linhas de código abaixo exemplificam essas operações:
public override void Commit(){
if (!CommitLock.IsWriteLockHeld){
CommitLock.EnterWriteLock();
//Call the base class’s “Commit” method
base.Commit();
//Perform whatever “lock downs” and “wire-ins” are needed here
CommitLock.ExitWriteLock();
}
else{
//Call the base class’s “Commit” method
base.Commit();
//Perform whatever “lock downs” and “wire-ins” are needed here
}
}
public override void Retract(){
if (!CommitLock.IsWriteLockHeld){
CommitLock.EnterWriteLock();
//Call the base class’s “Retract” method
base.Retract();
//Perform whatever “unlocks” are needed here
CommitLock.ExitWriteLock();
}
else{
//Call the base class’s “Retract” method
base.Retract();
//Perform whatever “unlocks” are needed here
}
}
Os exemplos de código anteriores demonstram as etapas para implementar um componente customizado do tipo ImplicitComponent. Também é possível, conforme citado anteriormente, implementar um Drive customizado. A implementação desse tipo de componente customizado é semelhante aos passos desenvolvidos no exemplo anterior. Um componente customizado também pode ser serializável.
Características Úteis
A biblioteca do CLARION disponibiliza algumas funcionalidades úteis para auxiliar no desenvolvimento dos agentes. A classe Agent possui o método GetInternals() que permite visualizar os objetos contidos dentro do agente. É possível investigar quais as regras aprendidas pelo agente, através da chamada deste método. Os objetos possíveis de serem investigados são: Drives, Action rules, Implicit decision networks, Associative rules, Associative memory networks, Associative episodic memory networks, Meta cognitive modules.
Outro recurso interessante permite visualizar os processos internos do agente que estão sendo disparados em tempo de execução. Esse recurso é disponibilizado pelo mecanismo de logging do CLARION. A classe Trace permite o uso desse recurso, que pode ser ajustado pelo uso do enumerador TraceLevel.
O CLARION também permite ao agente interagir assincronamente com o ambiente de simulação. Isso é possível por meio do uso da classe abstrata AsynchronousSimulatingEnvironment.
Theme by Danetsoft and Danang Probo Sayekti inspired by Maksimer