
- Relatório da Aula 01 (01/03/2013) Introdução
- Relatório da Aula 02 (08/03/2013) SOAR - Tutorial 1
- Relatório da Aula 03 (15/03/2013) SOAR - Tutorial 2
- Relatório da Aula 04 (22/03/2013) SOAR - Tutorial 3
- Relatório da Aula 05 (05/04/2013) SOAR - Tutoriais 4 e 5
- Relatório da Aula 06 (12/04/2013) SOAR - Tutoriais 7, 8 e 9
- Relatório da Aula 07 (19/04/2013) SOAR - Controlando o WorldServer3D
- Relatório da Aula 08 (26/04/2013) CLARION 1
- Relatório da Aula 09 (03/05/2013) CLARION 2
- Relatório da Aula 10 (10/05/2013) CLARION - Controlando o WorldServer3D
- Relatório da Aula 11 (17/05/2013) CLARION - Controlando o WorldServer3D
- Relatório da Aula 12 (24/05/2013) LIDA 1 - Entendendo a Arquitetura
- Relatório da Aula 13 (07/06/2013) LIDA 2 - Exemplos de Implementação Prática
You are here
Relatório da Aula 08 (26/04/2013) CLARION 1

SUMÁRIO
1. Introdução
2. Objetivos
3. Experimentos e Resultados
3.1. Visão Geral da Arquitetura Cognitiva CLARION
3.2. Atividade da Aula - Execução dos Tutoriais disponíveis
3.3. Análise Comparativa entre as Arquiteturas Cognitivas CLARION e SOAR
4. Conclusão
5. Referências Bibliográficas
1. Introdução
Este relatório apresenta uma visão geral da arquitetura CLARION, a descrição das atividades realizadas e os resultados obtidos nas simulações da Aula 8 do Curso IA006 - Laboratório em Arquiteturas Cognitivas, que tomam como base os tutoriais da arquitetura cognitiva CLARION disponíveis no site do projeto (Clarion Project, 2013).
2. Objetivos
A principal motivação dos experimentos desta aula é a compreensão da arquitetura cognitiva CLARION e realizar uma análise comparativa entre ela e a arquitetura cognitiva SOAR, estudada nas aulas anteriores.
Os objetivos principais desta aula são:
- Estudar o material teórico disponível sobre o CLARION;
- Realizar as atividades propostas nos tutoriais disponibilizados;
- Fazer uma análise comparativa entre o SOAR e o CLARION.
3. Experimentos e Resultados
3.1. Visão Geral da Arquitetura CLARION
CLARION (Connectionist Learning with Adaptive Rule Induction ON-line) é uma arquitetura cognitiva proposta inicialmente pelo Prof. Ron Sun, do Instituto Politécnico Rensselaer, como resultado de suas pesquisas nas áreas das ciências cognitivas e da psicologia no objetivo de investigar em profundidade estruturas fundamentais da mente humana. O modelo proposto é uma rede neural híbrida que pode ser usada para simular mecanismos de aprendizado e processos cognitivos presentes nos seres humanos.
CLARION é uma arquitetura formada por subsistemas distintos com representações distintas de conhecimento em cada um deles (representação implícita e representação explícita).
A dicotomia entre as representações existentes caracteriza uma arquitetura em dois níveis, cada qual captura um tipo de processo de representação possível:
- Representação Implícita (nível inferior): é caracterizada por uma representação subsimbólica e distribuída do conhecimento, de natureza inacessível e geralmente não tem um label semântico associado;
- Representação Explícita (nível superior): é caracterizada por uma representação simbólica localista do conhecimento, de natureza mais acessível e manipulável com um significado conceitual mais claro.
O conhecimento implícito pode ser adquirido por métodos de aprendizado por reforço (reinforcement learning) e é melhor capturado por modelos baseados em redes associativas, como as redes neurais; ao passo que o conhecimento explícito pode ser adquirido através do aprendizado instantâneo (one-shot learning) sendo melhor capturado por meio de produções.
Há dois tipos de aprendizado previstos na arquitetura:
- Aprendizado Bottom-Up: quando o conhecimento implícito adquirido é utilizado no aprendizado de conhecimento explícito, ou seja, é quando regras são extraídas e adicionadas no nível superior a partir de padrões exibidos pelas redes neurais no nível inferior.
- Aprendizado Top-Down: quando o conhecimento explícito adquirido presente no nível superior é assimilado no nível inferior.
Um detalhamento destes tipos de aprendizado classifica também os tipos de regras existentes:
- Bottom-Up Rule Learning (RER - Rule-Extraction-Refinement): neste tipo de aprendizado o agente aprende regras usando informações advindas do nível inferior;
- Independent Rule Learning (IRL): neste tipo de aprendizado o agente aprende regras exclusivamente com informações do nível superior;
- Fixed Rules: neste caso o agente possui regras já estabelecidas na mente e permanecem fixas durante as simulações. Este tipo de regra representa um conhecimento a priori, seja ele transferido geneticamente ou conhecimento prévio adquirido a partir de experiências anteriores com o mundo.
Em cada nível podem haver múltiplos módulos, cada qual residindo em um subsistema específico. Os subsistemas existentes são descritos em linhas gerais como:
- Subsistema Centrado em Ação (ACS - Action-Centered Subsytem): é responsável por manipular o conhecimento procedural, mais específico e de natureza mais dinâmica;
- Subsistema Não Centrado em Ação (NACS - Non-Action-Centered Subsystem): é responsável por manipular o conhecimento declarativo, mais genérico e de natureza mais estática.
Além desses dois subsistemas elementares, outros dois complementam a arquitetura:
- Subsistema Motivacional (MS - Motivational Subsystem): é responsável pela geração de drives, motivações e desejos que alteram o comportamento da percepção, ação e cognição.
- Subsistema Metacognitivo (MCS - Meta-Cognitive Subsystem): é responsável pelo monitoramento, direção e modificação das operações de todos os módulos dos outros subsistemas.
Cada subsistema é, portanto, responsável por um conjunto de estruturas e processos que representam as diversas capacidades e funções cognitivas existentes.
3.1.1. O Postulado
Em resumo, as hipóteses teóricas previstas na arquitetura são (Sun, 2003):
- Diferença Representacional: há dois níveis de representação na arquitetura que empregam dois diferentes tipos de representação (implícita e explícita) que tem diferentes níveis de acessibilidade.
- Diferença de Aprendizado: há dois métodos de aprendizado utilizados pelos dois níveis;
- Aprendizado bottom-up e top-down: há duas direções possíveis de aprendizado associados aos tipos de conhecimentos existentes;
- Representação centrada em ação e não centrada em ação: em cada nível, ambas as representações estão presentes.
Estas hipóteses juntas formam a base da arquitetura CLARION. A Figura 1 mostra a visão geral da arquitetura.
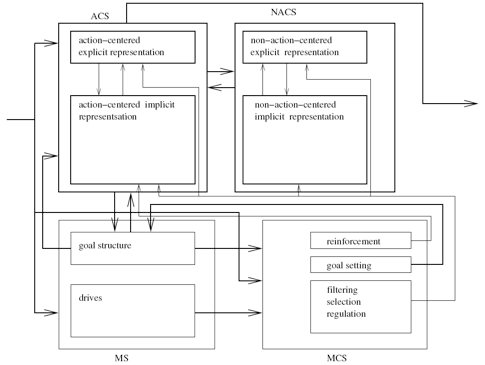
Figura 1 - A arquitetura CLARION.
3.2. Atividade da Aula - Execução dos Tutoriais disponíveis
3.2.1 Preparação
Para utilização do framework CLARION, é necessária a instalação do ambiente de desenvolvimento baseado na tecnologia .NET da Microsoft. A biblioteca do CLARION requer a versão 4.0 do framework .NET e a linguagem de programação C#.
Para as simulações desta aula, será utilizado o MonoDevelop (um ambiente de desenvolvimento integrado de código aberto), que habilita o desenvolvimento de programas baseados em .NET em plataformas baseadas em Unix, entre elas em especial o GNU/Linux. A distribuição utilizada para a instalação do MonoDevelop é o Ubuntu.
A instalação do MonoDevelop foi feita pelo gerenciador de pacotes do Ubuntu, o APT. A Figura 2 mostra o resultado do comando apt-get que fez a instalação.

Figura 2 - Execução do comando apt-get para instalação do MonoDevelop.
Após a conclusão da instalação, basta executá-lo diretamente no console. A Figura 3 mostra a tela inicial do MonoDevelop.
Figura 3 - Tela inicial do MonoDevelop.
Criação do Projeto de Simulação
Para que as simulações propostas nos tutoriais sejam realizadas, é necessário que se crie uma solução para contemplar os projetos a serem desenvolvidos. O tutorial sugere que o nome da solução seja "CLARION_Simulations". As Figuras 4 e 5 mostram a criação da solução e projeto de exemplo criado com saída do texto "Hello World" no console.

Figura 4 - Tela do MonoDevelop durante a criação da solução para as simulações dos tutoriais.
Figura 5 - Tela do MonoDevelop após a criação da solução CLARION_Simulations.
Princípios Básicos para a Criação de Simulações
Embora não exista nenhum requisito para a criação de simulações com o CLARION, alguns princípios básicos são recomendados no intuito de orientar o desenvolvimento. Estes princípios são descritos a seguir:
- Descrever as características e os objetos no mundo;
- Definir as ações e as motivações (metas) que ditam como os agentes interagem com o mundo;
- Inicializar as funções internas dos agentes de modo que eles possam tomar as decisões de ação baseadas em como eles percebem o mundo;
- Prover mecanismos para habilitar os agentes a interagir com o mundo.
Com os princípios básicos colocados, é possível explorar o primeiro tutorial que trata do subsistema centrado em ação (ACS).
3.2.2. Configurando e Usando o Subsistema Centrado em Ação (ACS)
Este tutorial propõe uma tarefa bastante a ser simulada cujo objetivo é introduzir os conceitos básicos para a preparação e execução de simulações no CLARION. O projeto SimpleHelloWorld deve ser criado para conter a classe utilizada na simulação.
A Simulação SimpleHelloWorld
A simulação deverá utilizar apenas o ACS com uma rede neural de retropropagação treinável por reforço no nível inferior e o método de aprendizado RER habilitado a fim de permitir a extração de regras baseadas no reforço.
O objetivo do agente deve compreender o aprendizado da seguinte proposição:
Se alguém diz "Hello" ou "Goodbye" a mim,
então eu devo responder com "Hello" ou "Goodbye", respectivamente.
No final da simulação, a proposição acima deverá ser representada na forma de regras no nível superior do ACS, tendo aprendido tais regras via RER.
O agente não deve ter qualquer conhecimento a-priori a respeito da dinâmica da tarefa, tendo conhecimento apenas das informações perceptivas (entradas) e das ações (saídas).
Desenvolvimento
A Figura 6 mostra o projeto SimpleHelloWorld no MonoDevelop e a Listagem 1 mostra o código-fonte completo da classe SimpleHelloWorld.cs.

Figura 6 - Tela do projeto SimpleHelloWorld no MonoDevelop.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.IO;
using System.Threading;
using System.Diagnostics;
using Clarion;
using Clarion.Framework;
namespace Clarion.Samples
{
public class HelloWorldSimple
{
static void Main(string[] args)
{
//Initialize the task
Console.WriteLine("Initializing the Simple Hello World Task");
int CorrectCounter = 0;
int NumberTrials = 10000;
int progress = 0;
World.LoggingLevel = TraceLevel.Off;
TextWriter orig = Console.Out;
StreamWriter sw = File.CreateText("HelloWorldSimple.txt");
DimensionValuePair hi = World.NewDimensionValuePair("Salutation", "Hello");
DimensionValuePair bye = World.NewDimensionValuePair("Salutation", "Goodbye");
ExternalActionChunk sayHi = World.NewExternalActionChunk("Hello");
ExternalActionChunk sayBye = World.NewExternalActionChunk("Goodbye");
//Initialize the Agent
Agent John = World.NewAgent("John");
SimplifiedQBPNetwork net = AgentInitializer.InitializeImplicitDecisionNetwork(
John, SimplifiedQBPNetwork.Factory);
net.Input.Add(hi);
net.Input.Add(bye);
net.Output.Add(sayHi);
net.Output.Add(sayBye);
John.Commit(net);
net.Parameters.LEARNING_RATE = 1;
John.ACS.Parameters.PERFORM_RER_REFINEMENT = false;
//Run the task
Console.WriteLine("Running the Simple Hello World Task");
Console.SetOut(sw);
Random rand = new Random();
SensoryInformation si;
ExternalActionChunk chosen;
for (int i = 0; i < NumberTrials; i++)
{
si = World.NewSensoryInformation(John);
//Randomly choose an input to perceive.
if (rand.NextDouble() < .5)
{
//Say "Hello"
si.Add(hi, John.Parameters.MAX_ACTIVATION);
si.Add(bye, John.Parameters.MIN_ACTIVATION);
}
else
{
//Say "Goodbye"
si.Add(hi, John.Parameters.MIN_ACTIVATION);
si.Add(bye, John.Parameters.MAX_ACTIVATION);
}
//Perceive the sensory information
John.Perceive(si);
//Choose an action
chosen = John.GetChosenExternalAction(si);
//Deliver appropriate feedback to the agent
if (chosen == sayHi)
{
//The agent said "Hello".
if (si[hi] == John.Parameters.MAX_ACTIVATION)
{
//The agent responded correctly
Trace.WriteLineIf(World.LoggingSwitch.TraceWarning,
"John was correct");
//Record the agent's success.
CorrectCounter++;
//Give positive feedback.
John.ReceiveFeedback(si, 1.0);
}
else
{
//The agent responded incorrectly
Trace.WriteLineIf(World.LoggingSwitch.TraceWarning,
"John was incorrect");
//Give negative feedback.
John.ReceiveFeedback(si, 0.0);
}
}
else
{
//The agent said "Goodbye".
if (si[bye] == John.Parameters.MAX_ACTIVATION)
{
//The agent responded correctly
Trace.WriteLineIf(World.LoggingSwitch.TraceWarning,
"John was correct");
//Record the agent's success.
CorrectCounter++;
//Give positive feedback.
John.ReceiveFeedback(si, 1.0);
}
else
{
//The agent responded incorrectly
Trace.WriteLineIf(World.LoggingSwitch.TraceWarning,
"John was incorrect");
//Give negative feedback.
John.ReceiveFeedback(si, 0.0);
}
}
Console.SetOut(orig);
progress = (int)(((double)(i+1) / (double)NumberTrials) * 100);
Console.CursorLeft = 0;
Console.Write(progress + "% Complete..");
Console.SetOut(sw);
}
//Report Results
Console.WriteLine("Reporting Results for the Simple Hello World Task");
Console.WriteLine("John got " + CorrectCounter
+ " correct out of " + NumberTrials + " trials (" +
(int)Math.Round(((double)CorrectCounter /
(double)NumberTrials) * 100) + "%)");
Console.WriteLine("At the end of the task,
John had learned the following rules:");
foreach (var i in John.GetInternals(Agent.InternalContainers.ACTION_RULES))
Console.WriteLine(i);
sw.Close();
Console.SetOut(orig);
Console.CursorLeft = 0;
Console.WriteLine("100% Complete..");
//Kill the agent to end the task
Console.WriteLine("Killing John to end the program");
John.Die();
Console.WriteLine("John is Dead");
Console.WriteLine("The Simple Hello World Task has finished");
Console.WriteLine("The results have been saved to \"HelloWorldSimple.txt\"");
Console.Write("Press any key to exit");
Console.ReadKey(true);
}
}
}
Listagem 1 - Código-fonte do projeto SimpleHelloWorld.
A execução da simulação gera uma saída no console informando o total de ensaios realizados até atingir o número total de 10.000 rodadas. A Listagem 2 mostra o trecho inicial e o trecho final desta saída no console.
Trial #00001: (sayHi ) John was incorrect Trial #00002: (sayBye) John was correct Trial #00003: (sayHi ) John was correct Trial #00004: (sayBye) John was correct Trial #00005: (sayBye) John was correct Trial #00006: (sayBye) John was correct Trial #00007: (sayHi ) John was correct Trial #00008: (sayBye) John was correct Trial #00009: (sayBye) John was correct Trial #00010: (sayHi ) John was correct Trial #00011: (sayBye) John was correct Trial #00012: (sayHi ) John was incorrect Trial #00013: (sayHi ) John was incorrect Trial #00014: (sayHi ) John was incorrect Trial #00015: (sayBye) John was correct Trial #00016: (sayBye) John was correct Trial #00017: (sayBye) John was correct Trial #00018: (sayHi ) John was incorrect Trial #00019: (sayBye) John was correct Trial #00020: (sayBye) John was correct Trial #00021: (sayBye) John was correct Trial #00022: (sayHi ) John was incorrect Trial #00023: (sayBye) John was correct Trial #00024: (sayBye) John was correct Trial #00025: (sayHi ) John was incorrect Trial #00026: (sayHi ) John was incorrect Trial #00027: (sayBye) John was correct Trial #00028: (sayBye) John was correct Trial #00029: (sayBye) John was correct Trial #00030: (sayHi ) John was correct Trial #00031: (sayHi ) John was correct Trial #00032: (sayBye) John was correct Trial #00033: (sayBye) John was correct Trial #00034: (sayBye) John was correct Trial #00035: (sayBye) John was correct Trial #00036: (sayBye) John was correct Trial #00037: (sayHi ) John was correct Trial #00038: (sayHi ) John was correct Trial #00039: (sayBye) John was correct Trial #00040: (sayHi ) John was incorrect Trial #00041: (sayHi ) John was correct Trial #00042: (sayHi ) John was incorrect Trial #00043: (sayHi ) John was incorrect Trial #00044: (sayHi ) John was correct Trial #00045: (sayBye) John was correct Trial #00046: (sayBye) John was correct Trial #00047: (sayBye) John was correct Trial #00048: (sayBye) John was correct Trial #00049: (sayBye) John was correct Trial #00050: (sayHi ) John was incorrect ..... ....... ..... ....... trials from #51 to #9950 omitted ..... ....... Trial #09951: (sayHi ) John was correct Trial #09952: (sayHi ) John was correct Trial #09953: (sayHi ) John was correct Trial #09954: (sayHi ) John was correct Trial #09955: (sayBye) John was correct Trial #09956: (sayBye) John was correct Trial #09957: (sayBye) John was correct Trial #09958: (sayHi ) John was correct Trial #09959: (sayHi ) John was correct Trial #09960: (sayHi ) John was correct Trial #09961: (sayBye) John was correct Trial #09962: (sayHi ) John was correct Trial #09963: (sayHi ) John was correct Trial #09964: (sayHi ) John was correct Trial #09965: (sayHi ) John was correct Trial #09966: (sayHi ) John was correct Trial #09967: (sayHi ) John was correct Trial #09968: (sayBye) John was correct Trial #09969: (sayHi ) John was correct Trial #09970: (sayBye) John was correct Trial #09971: (sayHi ) John was correct Trial #09972: (sayBye) John was correct Trial #09973: (sayHi ) John was correct Trial #09974: (sayBye) John was correct Trial #09975: (sayHi ) John was correct Trial #09976: (sayBye) John was correct Trial #09977: (sayHi ) John was correct Trial #09978: (sayHi ) John was correct Trial #09979: (sayHi ) John was correct Trial #09980: (sayBye) John was correct Trial #09981: (sayBye) John was correct Trial #09982: (sayHi ) John was correct Trial #09983: (sayBye) John was correct Trial #09984: (sayHi ) John was correct Trial #09985: (sayBye) John was correct Trial #09986: (sayBye) John was correct Trial #09987: (sayHi ) John was correct Trial #09988: (sayHi ) John was correct Trial #09989: (sayHi ) John was correct Trial #09990: (sayHi ) John was correct Trial #09991: (sayHi ) John was correct Trial #09992: (sayHi ) John was correct Trial #09993: (sayHi ) John was correct Trial #09994: (sayHi ) John was correct Trial #09995: (sayHi ) John was correct Trial #09996: (sayBye) John was correct Trial #09997: (sayHi ) John was correct Trial #09998: (sayHi ) John was correct Trial #09999: (sayBye) John was correct Trial #10000: (sayBye) John was correct
Listagem 2 - Trecho da execução do programa SimpleHelloWorld.
É possível notar que o agente inicia a simulação com uma taxa de acerto menor que aquela atingida no final da simulação. Este fato é decorrente do processo de aprendizado, baseado em um rede neural com retropropagação treinada a partir do algoritmo de Q-Learning simplificado, que faz com que o agente adquira o conhecimento por reforço, indicado conforme o agente acerta a saudação que deve ser dada a partir daquela informada a ele.
Resultados
O resultado final da simulação é a extração de regras que representam o conhecimento adquirido a respeito da proposição a partir do aprendizado por reforço. A Listagem 3 mostra o resultado do programa e as regras extraídas pelo algoritmo RER.
Reporting Results for the Simple Hello World Task John got 9745 correct out of 10000 trials (97%) At the end of the task, John had learned the following rules: Condition: (Dimension = Salutation, Value = Hello), Setting = True (Dimension = Salutation, Value = Goodbye), Setting = False Action: ExternalActionChunk Hello: DimensionValuePairs: (Dimension = SemanticLabel, Value = Hello) Condition: (Dimension = Salutation, Value = Hello), Setting = False (Dimension = Salutation, Value = Goodbye), Setting = True Action: ExternalActionChunk Goodbye: DimensionValuePairs: (Dimension = SemanticLabel, Value = Goodbye)
Listagem 3 - Resultado da simulação SimpleHelloWorld com as regras extraídas pelo algoritmo RER.
A seguir será dada continuidade com a extensão da simulação SimpleHelloWorld que faz uso da estrutura de metas, que permite a definição de metas a serem atingidas pelo agente.
3.2.3. Configurando e Usando a Estrutura de Metas (Goal Structure)
Este tutorial propõe o uso da estrutura de metas contida na arquitetura. Esta estrutura está localizada no topo do subsistema motivacional (MS) e define as metas que influenciarão o comportamento do agente (a partir do nível de ativação das metas).
Segundo a sua teoria, Clarion permite que sejam definidas ações que afetam a estrutura de metas. Essas ações são chamadas de ações de meta (goal actions). Estas ações podem realizar as operações na estrutura de metas e são classificadas de acordo com os seguintes tipos:
- SET: adiciona uma meta na estrutura de metas;
- RESET: remove uma meta da estrutura de metas;
- RESET_ALL: remove todas as metas da estrutura de metas;
- SET_RESET: combina as ações RESET_ALL e SET.
O uso destas ações no subsistema centrado em ação deve ser feito pela especificação na camada de saída do componente que representa a rede de decisões implícitas (IDN's).
A Simulação FullHelloWorld
De acordo com a teoria do Clarion, há vários parâmetros para os vários mecanismos existentes com o intuito de melhorar a performance do agente na execução das suas tarefas. Estes parâmetros estão implementados na arquitetura com dois escopos definidos: (i) parâmetros globais, conhecidos também de parâmetros estáticos; e (ii) parâmetros locais, também chamados de parâmetros de instância.
A simulação deverá utilizar alguns parâmetros para refinar o comportamento do agente implementado na seção anterior. Estes parâmetros deverão alterar o comportamento do algoritmo de extração e refinamento de regras (RER) através do ajuste dos limiares de generalização e especialização, que tratam da frequência com que a generalização e a especialização ocorrem durante a simulação.
Desenvolvimento
A Figura 7 mostra o projeto FullHelloWorld no MonoDevelop e a Listagem 4 mostra o código-fonte completo da classe responsável pela inicialização e configuração do agente e da execução da simulação em si.
Figura 7 - Tela do projeto FullHelloWorld no MonoDevelop.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.IO;
using System.Threading;
using System.Diagnostics;
using Clarion;
using Clarion.Framework;
using Clarion.Framework.Extensions;
using Clarion.Framework.Templates;
namespace Clarion.Samples
{
public class HelloWorldFull
{
static void Main(string[] args)
{
//Initialize the task
Console.WriteLine("Initializing the Full Hello World Task");
int CorrectCounter = 0;
int NumberTrials = 20000;
World.LoggingLevel = TraceLevel.Off;
int progress = 0;
TextWriter orig = Console.Out;
StreamWriter sw = File.CreateText("HelloWorldFull.txt");
DimensionValuePair hi = World.NewDimensionValuePair("Salutation", "Hello");
DimensionValuePair bye = World.NewDimensionValuePair("Salutation", "Goodbye");
ExternalActionChunk sayHi = World.NewExternalActionChunk("Hello");
ExternalActionChunk sayBye = World.NewExternalActionChunk("Goodbye");
GoalChunk salute = World.NewGoalChunk("Salute");
GoalChunk bidFarewell = World.NewGoalChunk("Bid Farewell");
//Initialize the Agent
Agent John = World.NewAgent("John");
SimplifiedQBPNetwork net =
AgentInitializer.InitializeImplicitDecisionNetwork(
John, SimplifiedQBPNetwork.Factory);
net.Input.Add(salute);
net.Input.Add(bidFarewell);
net.Input.Add(hi);
net.Input.Add(bye);
net.Output.Add(sayHi);
net.Output.Add(sayBye);
net.Parameters.LEARNING_RATE = 1;
John.Commit(net);
RefineableActionRule.GlobalParameters.SPECIALIZATION_THRESHOLD_1 = -.6;
RefineableActionRule.GlobalParameters.GENERALIZATION_THRESHOLD_1 = -.1;
RefineableActionRule.GlobalParameters.INFORMATION_GAIN_OPTION =
RefineableActionRule.IGOptions.PERFECT;
AffiliationBelongingnessDrive ab =
AgentInitializer.InitializeDrive(John,
AffiliationBelongingnessDrive.Factory,
.5, (DeficitChangeProcessor)HelloWorldFull_DeficitChange);
DriveEquation abd = AgentInitializer.InitializeDriveComponent(
ab, DriveEquation.Factory);
ab.Commit(abd);
John.Commit(ab);
AutonomyDrive aut = AgentInitializer.InitializeDrive(
John, AutonomyDrive.Factory, .5,
(DeficitChangeProcessor)HelloWorldFull_DeficitChange);
DriveEquation autd =
AgentInitializer.InitializeDriveComponent(aut, DriveEquation.Factory);
aut.Commit(autd);
John.Commit(aut);
GoalSelectionModule gsm =
AgentInitializer.InitializeMetaCognitiveModule(
John, GoalSelectionModule.Factory);
GoalSelectionEquation gse =
AgentInitializer.InitializeMetaCognitiveDecisionNetwork(
gsm, GoalSelectionEquation.Factory);
gse.Input.Add(ab.GetDriveStrength());
gse.Input.Add(aut.GetDriveStrength());
GoalStructureUpdateActionChunk su = World.NewGoalStructureUpdateActionChunk();
GoalStructureUpdateActionChunk bu = World.NewGoalStructureUpdateActionChunk();
su.Add(GoalStructure.RecognizedActions.SET_RESET, salute);
bu.Add(GoalStructure.RecognizedActions.SET_RESET, bidFarewell);
gse.Output.Add(su);
gse.Output.Add(bu);
gse.SetRelevance(su, ab, 1);
gse.SetRelevance(bu, aut, 1);
gsm.Commit(gse);
John.Commit(gsm);
John.MS.Parameters.CURRENT_GOAL_ACTIVATION_OPTION =
MotivationalSubsystem.CurrentGoalActivationOptions.FULL;
//Run the task
Console.WriteLine("Running the Full Hello World Task");
Console.SetOut(sw);
Random rand = new Random();
SensoryInformation si;
ExternalActionChunk chosen;
for (int i = 0; i < NumberTrials; i++)
{
si = World.NewSensoryInformation(John);
//Randomly choose an input to perceive.
if (rand.NextDouble() < .5)
{
//Say "Hello"
si.Add(hi, John.Parameters.MAX_ACTIVATION);
si.Add(bye, John.Parameters.MIN_ACTIVATION);
si[typeof(AffiliationBelongingnessDrive),
AffiliationBelongingnessDrive.MetaInfoReservations.STIMULUS] = 1;
}
else
{
//Say "Goodbye"
si.Add(hi, John.Parameters.MIN_ACTIVATION);
si.Add(bye, John.Parameters.MAX_ACTIVATION);
si[typeof(AutonomyDrive),
AutonomyDrive.MetaInfoReservations.STIMULUS] = 1;
}
//Perceive the sensory information
John.Perceive(si);
//Choose an action
chosen = John.GetChosenExternalAction(si);
//Deliver appropriate feedback to the agent
if (chosen == sayHi)
{
//The agent said "Hello".
if (si[hi] == John.Parameters.MAX_ACTIVATION)
{
//The agent responded correctly
Trace.WriteLineIf(World.LoggingSwitch.TraceWarning,
"John was correct");
//Record the agent's success.
CorrectCounter++;
//Give positive feedback.
John.ReceiveFeedback(si, 1.0);
}
else
{
//The agent responded incorrectly
Trace.WriteLineIf(World.LoggingSwitch.TraceWarning,
"John was incorrect");
//Give negative feedback.
John.ReceiveFeedback(si, 0.0);
}
}
else
{
//The agent said "Goodbye".
if (si[bye] == John.Parameters.MAX_ACTIVATION)
{
//The agent responded correctly
Trace.WriteLineIf(World.LoggingSwitch.TraceWarning,
"John was correct");
//Record the agent's success.
CorrectCounter++;
//Give positive feedback.
John.ReceiveFeedback(si, 1.0);
}
else
{
//The agent responded incorrectly
Trace.WriteLineIf(World.LoggingSwitch.TraceWarning,
"John was incorrect");
//Give negative feedback.
John.ReceiveFeedback(si, 0.0);
}
}
Console.SetOut(orig);
progress = (int)(((double)(i+1) / (double)NumberTrials) * 100);
Console.CursorLeft = 0;
Console.Write(progress + "% Complete..\n");
Console.SetOut(sw);
}
//Report Results
Console.WriteLine("Reporting Results for the Full Hello World Task");
Console.WriteLine("John got " + CorrectCounter
+ " correct out of " + NumberTrials + " trials (" +
(int)Math.Round(((double)CorrectCounter /
(double)NumberTrials) * 100) + "%)");
Console.WriteLine(
"At the end of the task, John had learned the following rules:");
foreach (var i in John.GetInternals(Agent.InternalContainers.ACTION_RULES))
Console.WriteLine(i);
sw.Close();
Console.SetOut(orig);
Console.CursorLeft = 0;
Console.WriteLine("100% Complete..");
//Kill the agent to end the task
Console.WriteLine("Killing John to end the program");
John.Die();
Console.WriteLine("John is Dead");
Console.WriteLine("The Full Hello World Task has finished");
Console.WriteLine("The results have been saved to \"HelloWorldFull.txt\"");
Console.Write("Press any key to exit");
Console.ReadKey(true);
}
public static double HelloWorldFull_DeficitChange(
ActivationCollection si, Drive target)
{
var cg = ((SensoryInformation)si).AffiliatedAgent.CurrentGoal;
if (cg != null)
{
if ((cg == World.GetGoalChunk("Salute") &&
target is AffiliationBelongingnessDrive) ||
(cg == World.GetGoalChunk("Bid Farewell") && target is AutonomyDrive))
target.Parameters.DEFICIT_CHANGE_RATE = .999;
else
target.Parameters.DEFICIT_CHANGE_RATE = 1.001;
}
return target.Deficit * target.Parameters.DEFICIT_CHANGE_RATE;
}
}
}
Listagem 4 - Código-fonte do projeto FullHelloWorld.
A execução da simulação gera uma saída no console informando o total de ensaios realizados até atingir o número total de 20.000 rodadas. A Listagem 5 mostra o trecho inicial e o trecho final desta saída no console.
Trial #00001: (sayHi ) John was incorrect Trial #00002: (sayHi ) John was incorrect Trial #00003: (sayHi ) John was incorrect Trial #00004: (sayBye) John was correct Trial #00005: (sayHi ) John was incorrect Trial #00006: (sayBye) John was incorrect Trial #00007: (sayHi ) John was correct Trial #00008: (sayBye) John was correct Trial #00009: (sayHi ) John was incorrect Trial #00010: (sayBye) John was correct Trial #00011: (sayHi ) John was incorrect Trial #00012: (sayBye) John was incorrect Trial #00013: (sayHi ) John was correct Trial #00014: (sayHi ) John was incorrect Trial #00015: (sayBye) John was incorrect Trial #00016: (sayBye) John was correct Trial #00017: (sayBye) John was incorrect Trial #00018: (sayHi ) John was incorrect Trial #00019: (sayBye) John was incorrect Trial #00020: (sayBye) John was incorrect Trial #00021: (sayBye) John was incorrect Trial #00022: (sayBye) John was incorrect Trial #00023: (sayBye) John was incorrect Trial #00024: (sayBye) John was incorrect Trial #00025: (sayHi ) John was incorrect Trial #00026: (sayHi ) John was correct Trial #00027: (sayHi ) John was correct Trial #00028: (sayBye) John was incorrect Trial #00029: (sayHi ) John was incorrect Trial #00030: (sayHi ) John was incorrect Trial #00031: (sayHi ) John was incorrect Trial #00032: (sayHi ) John was incorrect Trial #00033: (sayBye) John was correct Trial #00034: (sayHi ) John was incorrect Trial #00035: (sayBye) John was incorrect Trial #00036: (sayBye) John was correct Trial #00037: (sayBye) John was correct Trial #00038: (sayBye) John was correct Trial #00039: (sayBye) John was incorrect Trial #00040: (sayBye) John was incorrect Trial #00041: (sayBye) John was correct Trial #00042: (sayBye) John was incorrect Trial #00043: (sayBye) John was incorrect Trial #00044: (sayBye) John was correct Trial #00045: (sayBye) John was incorrect Trial #00046: (sayBye) John was incorrect Trial #00047: (sayBye) John was correct Trial #00048: (sayBye) John was correct Trial #00049: (sayBye) John was incorrect Trial #00050: (sayBye) John was incorrect Trial #00050: (sayHi ) John was incorrect ..... ....... ..... ....... trials from #51 to #19950 omitted ..... ....... Trial #09951: (sayHi ) John was correct Trial #19950: (sayBye) John was correct Trial #19951: (sayHi ) John was correct Trial #19952: (sayBye) John was correct Trial #19953: (sayBye) John was correct Trial #19954: (sayBye) John was correct Trial #19955: (sayHi ) John was correct Trial #19956: (sayHi ) John was correct Trial #19957: (sayHi ) John was correct Trial #19958: (sayHi ) John was correct Trial #19959: (sayBye) John was correct Trial #19960: (sayBye) John was correct Trial #19961: (sayBye) John was correct Trial #19962: (sayBye) John was correct Trial #19963: (sayHi ) John was correct Trial #19964: (sayBye) John was correct Trial #19965: (sayBye) John was correct Trial #19966: (sayHi ) John was incorrect Trial #19967: (sayHi ) John was correct Trial #19968: (sayHi ) John was correct Trial #19969: (sayBye) John was correct Trial #19970: (sayHi ) John was correct Trial #19971: (sayHi ) John was correct Trial #19972: (sayHi ) John was correct Trial #19973: (sayBye) John was correct Trial #19974: (sayBye) John was correct Trial #19975: (sayHi ) John was correct Trial #19976: (sayHi ) John was correct Trial #19977: (sayHi ) John was correct Trial #19978: (sayBye) John was correct Trial #19979: (sayBye) John was correct Trial #19980: (sayBye) John was correct Trial #19981: (sayBye) John was correct Trial #19982: (sayHi ) John was correct Trial #19983: (sayBye) John was correct Trial #19984: (sayHi ) John was correct Trial #19985: (sayHi ) John was correct Trial #19986: (sayBye) John was correct Trial #19987: (sayHi ) John was correct Trial #19988: (sayBye) John was correct Trial #19989: (sayHi ) John was correct Trial #19990: (sayHi ) John was correct Trial #19991: (sayHi ) John was correct Trial #19992: (sayBye) John was correct Trial #19993: (sayBye) John was correct Trial #19994: (sayHi ) John was incorrect Trial #19995: (sayHi ) John was correct Trial #19996: (sayHi ) John was correct Trial #19997: (sayHi ) John was correct Trial #19998: (sayHi ) John was correct Trial #19999: (sayBye) John was incorrect Trial #20000: (sayHi ) John was correct
Listagem 5 - Trecho da execução do programa FullHelloWorld.
Como era esperado, da mesma forma que a simulação anterior, o agente inicia a simulação com uma taxa de acerto menor que aquela atingida no final da simulação. Este fato é decorrente do processo de aprendizado, baseado em um rede neural com retropropagação treinada a partir do algoritmo de Q-Learning simplificado, que faz com que o agente adquira o conhecimento por reforço. No entanto, a diferença nesta simulação é que a seleção é de ação leva em conta a estrutura de metas e a influência do drive de pertencimento e afiliação e do drive de autonomia, dependendo da saudação a ser escolhida.
Resultados
O resultado final da simulação, depois de 20.000 rodadas, é a extração de regras que representam o conhecimento adquirido sobre a saudação de resposta a ser dada, conforme a saudação recebida pelo agente. A Listagem 6 mostra o resultado do programa e as regras extraídas pelo algoritmo RER.
Reporting Results for the Full Hello World Task John got 18882 correct out of 20000 trials (94%) At the end of the task, John had learned the following rules: Condition: (Dimension = GoalChunk, Value = Salute), Setting = True (Dimension = GoalChunk, Value = Bid Farewell), Setting = True (Dimension = Salutation, Value = Hello), Setting = False (Dimension = Salutation, Value = Goodbye), Setting = True Action: ExternalActionChunk Goodbye: DimensionValuePairs: (Dimension = SemanticLabel, Value = Goodbye) Condition: (Dimension = GoalChunk, Value = Salute), Setting = True (Dimension = GoalChunk, Value = Bid Farewell), Setting = False (Dimension = Salutation, Value = Hello), Setting = True (Dimension = Salutation, Value = Goodbye), Setting = False Action: ExternalActionChunk Hello: DimensionValuePairs: (Dimension = SemanticLabel, Value = Hello) Condition: (Dimension = GoalChunk, Value = Salute), Setting = False (Dimension = GoalChunk, Value = Bid Farewell), Setting = True (Dimension = Salutation, Value = Hello), Setting = True (Dimension = Salutation, Value = Goodbye), Setting = False Action: ExternalActionChunk Hello: DimensionValuePairs: (Dimension = SemanticLabel, Value = Hello)
Listagem 6 - Resultado da simulação SimpleHelloWorld com as regras extraídas pelo algoritmo RER.
3.3. Análise Comparativa entre as Arquiteturas Cognitivas CLARION e SOAR
As arquiteturas cognitivas CLARION e SOAR possuem vários aspectos em comum mas são baseadas fundamentalmente em correntes teóricas distintas. Em um sentido amplo, admite-se que SOAR incorpora teorias advindas do cognitivismo simbólico, ao passo que CLARION é resultado de teorias baseadas no conexionismo.
SOAR é um sistema de produção baseado na hipótese de sistemas de símbolos físicos. Este aspecto implica que seus mecanismos e processos atuem sob uma abordagem de resolução de problemas (problem solving). O comportamento é governado por regras explícitas que determinam o raciocínio e a manipulação de conhecimento com o objetivo de atingir uma meta especificada. Dentre os mecanismos que dão suporte ao ciclo de decisão estão as memórias de trabalho, memória semântica, memória episódica e mecanismos de aprendizado baseados em chunking e aprendizado por reforço.
CLARION é uma arquitetura cognitiva orientada a aspectos psicológicos da mente humana. Estes aspectos encontram-se representados em módulos que formam subsistemas especializados. Estes subsistemas tratam do processo cognitivo a partir da manipulação de conhecimento procedural, conhecimento declarativo, motivações e conhecimento sobre si próprio e sobre o próprio processo cognitivo. Em cada subsistema há uma representação dual da cognição (implícita e explícita) que são implementadas por meio de redes neurais, redes associativas e chunks. Estão também presentes a memória de trabalho, a memória semântica, a memória epsódica e mecanismos de aprendizado baseados em chunking e aprendizado por reforço.
A diferença crucial entre SOAR e CLARION é que no SOAR não há distinção entre conhecimento implícito e explícito nem tampouco distinção entre as representações distribuídas e as representações localistas/simbólicas. O aprendizado é baseado na especialização de regras usando somente representações simbólicas. No SOAR, ainda, é necessário um conhecimento inicial (conhecimento a priori) expresso única e exclusivamente por meio de produções e a partir dele, não há aprendizado autônomo como ocorre no CLARION.
Além disso, ambos, SOAR e CLARION, possuem procedimentos de raciocínio baseados no encadeamento para frente (forward chaining reasoning). No entanto, CLARION conta com o método adicional de raciocínio baseado em similaridade que não existe no SOAR.
O estabelecimento de metas e seleção de ação é mais sofisticada no CLARION do que no SOAR. No SOAR as metas estão engendradas nas produções e a seleção de ação é feita por meio de ciclos de decisão baseados na proposição, seleção e aplicação de operadores; ao passo que no CLARION as metas são consideradas motivações tangíveis, ou seja, objetivos explícitos mantidos pelo subsistema motivacional. Eles são colocados em uma estrutura dedicada que é manipulada diretamente pelo subsistema centrado em ação sofrendo influências de outros processos motivacionais existentes (os drives).
Por fim, o SOAR também não conta nativamente com processos motivacionais e processos metacognitivos. No CLARION, estes processos são capturados por subsistemas específicos e tem um papel fundamental nas simulações de sistemas inteligentes fundamentados em teorias cognitivas mais recentes.
4. Conclusão
Nesta aula foram estudadas as características principais da arquitetura cognitiva CLARION a partir da leitura dos tutoriais e da execução de simulações que exploraram os aspectos fundamentais que formam a base teórica da arquitetura.
O CLARION se apresenta com fundamentação em teorias cognitivas recentes, com forte influência de correntes conexionistas e modelos psicológicos da mente humana. Diferente do SOAR, que se apoiou inicialmente em correntes simbolicistas, CLARION traz consigo duas representações de conhecimento distintas capazes de capturar modalidades diferentes de conhecimento com tipos e métodos de aprendizado específicos.
É possível afirmar que CLARION reproduz algumas capacidades mentais do aparato cognitivo humano com elevado grau de fidelidade se comparado com fenônemos mentais observáveis e estende, em certo grau, as possibilidade na criação de agentes cognitivos mais sofisticados se comparado com o SOAR, a partir de modelos computacionais da motivação e da metacognição.
5. Referências Bibliográficas
Sun, Ron (2003). A Tutorial on CLARION 5.0. Rensselaer Polytechnic Institute. Disponível em: <http://www.cogsci.rpi.edu/~rsun/sun.tutorial.pdf>. Acesso em: 1 maio 2013.
Clarion Project (2013). The Clarion Cognitive Architecture Project. Rensselaer Polytechnic Institute. Disponível em: <https://sites.google.com/site/clarioncognitivearchitecture/>. Acesso em: 1 maio 2013.
Theme by Danetsoft and Danang Probo Sayekti inspired by Maksimer