
- Relatório da Aula 01 (01/03/2013) Introdução
- Relatório da Aula 02 (08/03/2013) SOAR - Tutorial 1
- Relatório da Aula 03 (15/03/2013) SOAR - Tutorial 2
- Relatório da Aula 04 (22/03/2013) SOAR - Tutorial 3
- Relatório da Aula 05 (05/04/2013) SOAR - Tutoriais 4 e 5
- Relatório da Aula 06 (12/04/2013) SOAR - Tutoriais 7, 8 e 9
- Relatório da Aula 07 (19/04/2013) SOAR - Controlando o WorldServer3D
- Relatório da Aula 08 (26/04/2013) CLARION 1
- Relatório da Aula 09 (03/05/2013) CLARION 2
- Relatório da Aula 10 (10/05/2013) CLARION - Controlando o WorldServer3D
- Relatório da Aula 11 (17/05/2013) CLARION - Controlando o WorldServer3D
- Relatório da Aula 12 (24/05/2013) LIDA 1 - Entendendo a Arquitetura
- Relatório da Aula 13 (07/06/2013) LIDA 2 - Exemplos de Implementação Prática
You are here
Relatório da Aula 06 (12/04/2013) SOAR - Tutoriais 7, 8 e 9

SUMÁRIO
1. Introdução
2. Objetivos
3. Experimentos e Resultados
3.1. Atividade 1 - Tutorial 7 do Soar - Aprendizado por Reforço (Reinforcement Learning)
3.2. Atividade 2 - Tutorial 8 do Soar - Memória Semântica (Semantic Memory)
3.3. Atividade 3 - Tutorial 9 do Soar - Memória Episódica (Episodic Memory)
4. Conclusão
5. Referências Bibliográficas
1. Introdução
Este relatório apresenta a descrição das atividades e os resultados obtidos nos experimentos propostos na Aula 6 do Curso IA006 - Laboratório em Arquiteturas Cognitivas. Estes experimentos dão continuidade ao aprendizado da arquitetura cognitiva Soar.
As atividades do Tutorial 7 explorarão um tipo específico de aprendizado, diferente do chunking e comum na implementação de sistemas inteligentes, conhecido como aprendizado por reforço. As atividades do Tutorial 8 explorarão um tipo específico de memória, também disponível no Soar e diferente da memória de trabalho, conhecida como memória semântica. Por fim, as atividades do Tutorial 9 explorarão outro tipo de memória disponível conhecido como memória episódica. É esperado que estes novos recursos possam ser utilizados na criação de estratégias de controles mais sofisticados na implementação de agentes inteligentes.
Os objetivos gerais a serem atingidos nesta aula são apresentados na seção 2. A seção 3 traz a descrição dos experimentos realizados, seus objetivos específicos e os resultados obtidos em cada um deles. A seção 4 apresenta as conclusões obtidas a partir dos experimentos.
2. Objetivos
A principal motivação dos experimentos desta aula é fornecer um arcabouço de recursos adicionais e de grande valia para a criação de agentes inteligentes por meio dos novos recursos apresentados nos tutoriais.
Os objetivos principais destes experimentos são:
- Estudar os mecanismos de aprendizado por reforço e os de memória semântica e episódica;
- Explorar programas Soar que utilizem tais recursos.
3. Experimentos e Resultados
3.1. Atividade 1
3.1.1. Objetivos específicos
- Realizar as atividades propostas no Tutorial 7 do Soar;
- Realizar simulações de programas Soar que façam uso do mecanismo de aprendizado por reforço.
3.1.2. Desenvolvimento
No Soar, o aprendizado por reforço permite que agentes alterem seu comportamento ao longo do tempo por meio da alteração dos valores numéricos das preferências de indiferença na memória procedural em resposta a um sinal de recompensa (Laird, 2012). Este mecanismo de aprendizado é diferente do chunking. O chunking é uma forma de aprendizado de disparo imediato que aumenta a performance de execução do agente por meio da sumarização dos resultados obtidos na solução de subproblemas; ao passo que o aprendizado por reforço é uma forma de aprendizado que altera o comportamento do agente estatisticamente.
O agente "esquerda-direita"
Os experimentos a serem realizados nesta atividade serão baseados em um agente que escolherá uma entre duas direções possíveis: direita ou esquerda. Embora o agente não tenha conhecimento, uma das direções é mais preferível que a outra. Depois de tomar a decisão, o agente receberá uma recompensa, que nada mais é que uma informação sobre o quão boa foi a decisão tomada. Neste caso, ele receberá uma recompensa de -1 se escolher a esquerda e +1 se escolher a direita. Ao utilizar o aprendizado por reforço, o agente aprenderá rapidamente que escolher a direita é mais vantajoso. A Figura 1 mostra a estrutura do programa left-right.soar no VisualSoar. A Listagem 1 mostra as produções criadas no programa.

Figura 1 - Estrutura do programa left-right.soar no VisualDebugger.
# Initialization ------------------------ sp {propose*initialize-left-right (state <s> ^superstate nil -^name) --> (<s> ^operator <o> +) (<o> ^name initialize-left-right)} sp {apply*initialize-left-right (state <s> ^operator <op>) (<op> ^name initialize-left-right) --> (<s> ^name left-right ^direction <d1> <d2> ^location start) (<d1> ^name left ^reward -1) (<d2> ^name right ^reward 1)} # Move ---------------------------------- sp {left-right*propose*move (state <s> ^name left-right ^direction.name <dir> ^location start) --> (<s> ^operator <op> +) (<op> ^name move ^dir <dir>)} sp {left-right*rl*left (state <s> ^name left-right ^operator <op> +) (<op> ^name move ^dir left) --> (<s> ^operator <op> = 0)} sp {left-right*rl*right (state <s> ^name left-right ^operator <op> +) (<op> ^name move ^dir right) --> (<s> ^operator <op> = 0)} sp {apply*move (state <s> ^operator <op> ^location start) (<op> ^name move ^dir <dir>) --> (<s> ^location start - <dir>) (write (crlf) |Moved: | <dir>)} # Reward -------------------------------- sp {elaborate*reward (state <s> ^name left-right ^reward-link <r> ^location <d-name> ^direction <dir>) (<dir> ^name <d-name> ^reward <d-reward>) --> (<r> ^reward.value <d-reward>)} # Conclusion ---------------------------- sp {elaborate*done (state <s> ^name left-right ^location {<> start}) --> (halt) }
Listagem 1 - Código-fonte do programa left-right.soar.
O programa left-right.soar armazena as direções e as recompensas associadas no estado. Ele pode mover-se em qualquer uma das duas direções assumindo que, em princípio, ambas são indiferentes. Quando o agente toma a decisão em favor de uma direção, ele é recompensado caso a direção escolhida seja a correta. Assim que recebida a recompensa, o programa termina.
A execução do agente
O aprendizado por reforço está desabilitado por padrão no Soar. Para habilitá-lo, devem ser executados os seguintes comandos:
rl --set learning on indifferent-selection –-epsilon-greedy
Listagem 2 - Comandos para ativação do aprendizado por reforço.
Para a execução do programa left-right.soar com o SoarDebugger, argumentos na linha de comando podem ser inseridos com a mesma finalidade de ativar o aprendizado por reforço. A Figura 2 mostra a linha de comando para execução com aprendizado por reforço.

Figura 2 - Execução do SoarDebugger com ativação do aprendizado por reforço na linha de comando.
Ao executar o programa, no primeiro ciclo pode ser visto que a inicialização foi realizada. Ao ser executado o comando print --rl para listagem dos valores de preferências, é possível ver que ambas as direções estão com o valor zero (Figura 3).
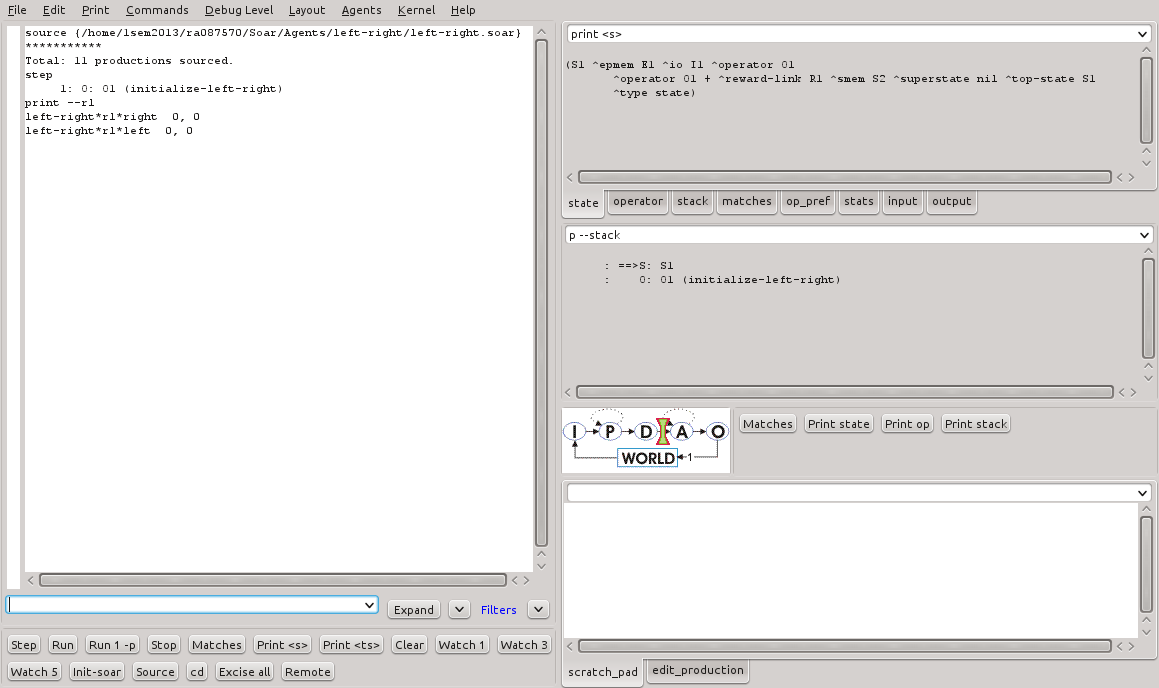
Figura 3 - Primeiro ciclo de execução do programa left-right.soar.
Após a execução de mais dois ciclos, a saída do comando print --rl é mostrada na Figura 4.

Figura 4 - Dois ciclos de execução adicionais do programa left-right.soar.
É possível notar, agora, que os valores de indiferença para as direções foram alteradas. Esta alteração foi feita imediatamente após a aplicação do operador move. A Listagem 3 mostra os valores de indiferença para cada caso.
# Ciclo 1 left-right*rl*right 0. 0 left-right*rl*left 0. 0 # 2 ciclos subsequentes, se escolhido a direção 'direita' left-right*rl*right 1. 0.3 left-right*rl*left 0. 0 # 2 ciclos subsequentes, se escolhido a direção 'esquerda' left-right*rl*right 0. 0 left-right*rl*left 1. -0.3
Listagem 3 - Valores de preferência para as direções.
Ao reiniciar o agente, a execução do comando print --rl revela que os valores não foram alterados. O armazenamento destes valores entre várias execuções é o método pelo qual o agente aprende no aprendizado por reforço. A Figura 5 mostra 20 execuções sucessivas do programa.
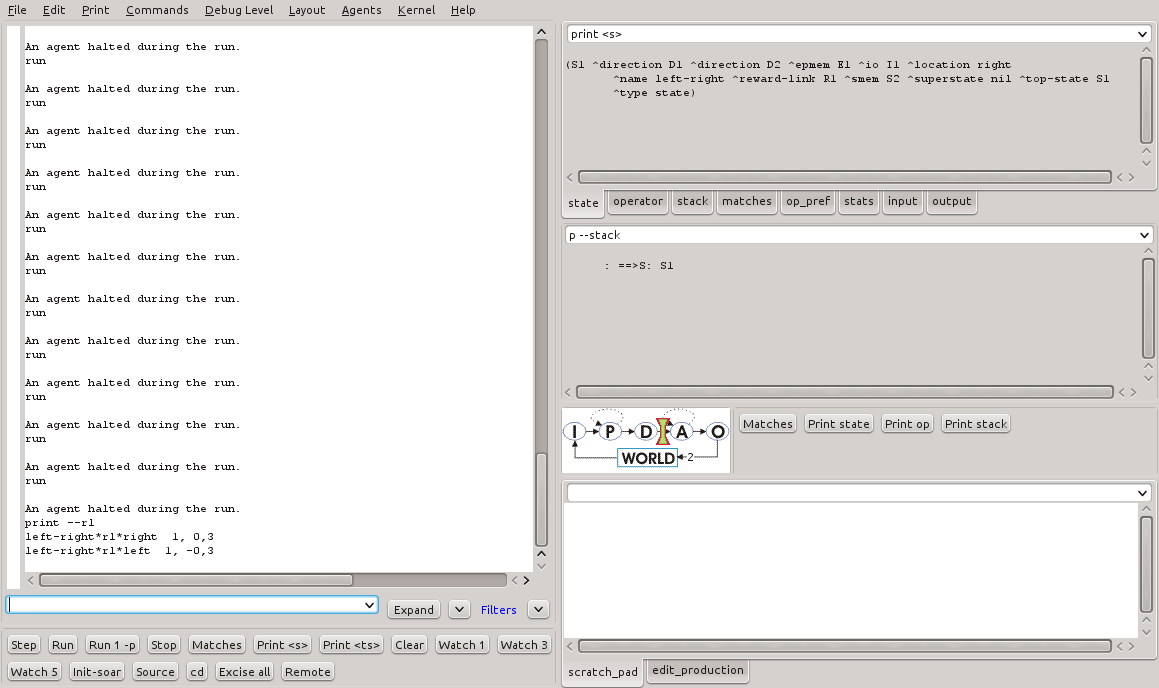
Figura 5 - Valores de preferência depois de 20 execuções sucessivas do programa left-right.soar.
É possível observar que o valor de indiferença para a direção da direta cresce gradativamente ao passo que o valor de indiferença para a direção da esquerda diminui. Da mesma forma, nota-se que a direção da direita passa a ser escolhida com maior frequência. A Figura 6 mostra o resultado das escolhas da direita em sequência.
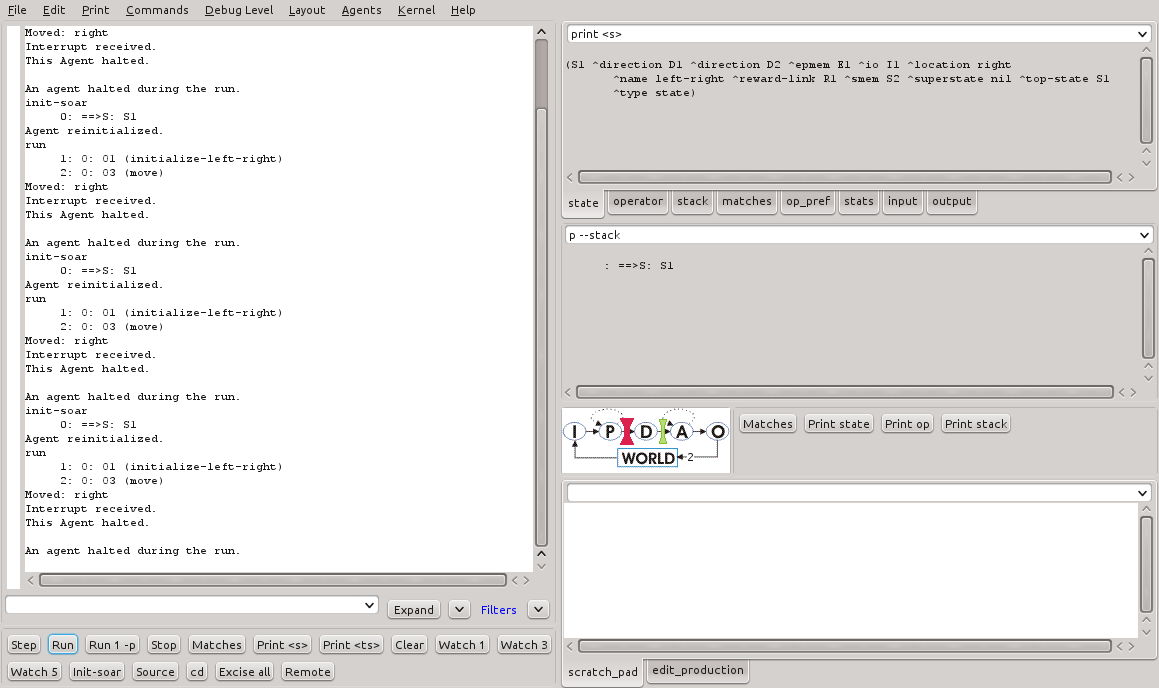
Figura 6 - Escolha mais frequente da direção da direita após vários ciclos de execução do programa left-right.soar.
É possível notar que a frequência com que a direção da direta é escolhida pelo agente aumenta em função do valor de indiferença memorizado. O agente, neste caso, prefere a escolha por esta direção dado que a recompensa é maior.
As regras para o Aprendizado por Reforço
As regras que são reconhecidas como atualizáveis pelo mecanismo de aprendizado por reforço segue a sintaxe mostrada na Listagem 4.
sp {my*rl*proposal*rule
(state <s> ^operator <op> +
^condition <c>)
-->
(<s> ^operator <op> = number)
}
Listagem 4 - Sintaxe das regras atualizáveis pelo mecanismo de aprendizado por reforço.
Nestas regras, não importam o nome e as condições presentes, porém, a ação deve seguir a sintaxe indicando um número que refere-se ao valor de preferência de indiferença. Este valor será continuamente atualizado pelo mecanismo de aprendizado a cada ciclo de decisão conforme a política de aprendizado vigente.
O Aprendizado por Reforço e o problema dos Jarros d'Água
O objetivo deste experimento é fazer com que o agente aprenda as melhores condições para se esvaziar um jarro, encher um jarro ou transferir água de um jarro para outro. Para tal, as adaptações a serem feitas no programa water-jug.soar envolvem a modificação dos operadores empty, fill e pour para que sejam regras de aprendizado por reforço atualizáveis.
A Figura 7 mostra a estrutura do programa water-jug-rl.soar no VisualDebugger com as adaptações realizadas.
Figura 7 - Estrutura do programa water-jug-rl.soar no VisualDebugger.
Basicamente, os seguintes passos devem ser executados para suporte ao aprendizado por reforço:
- Criação/alteração das regras de proposição de operadores com preferências de aceitabilidade;
- Criação das regras atualizáveis pelo aprendizado por reforço representando cada estado associado à ação;
- Criação das regras de recompensa;
Para o programa water-jug-rl.soar, o primeiro passo é implementado pela remoção da preferência de indiferença das regras de proposição de operadores, conforme mostrado pela Listagem 5.
sp {water-jug*propose*empty
(state <s> ^name water-jug
^jug <j>)
(<j> ^contents > 0)
-->
(<s> ^operator <o> +)
(<o> ^name empty
^empty-jug <j>)}
sp {water-jug*propose*fill
(state <s> ^name water-jug
^jug <j>)
(<j> ^empty > 0)
-->
(<s> ^operator <o> +)
(<o> ^name fill
^fill-jug <j>)}
sp {water-jug*propose*pour
(state <s> ^name water-jug
^jug <i> { <><i><j> })
(<i> ^contents > 0 )
(<j> ^empty > 0)
-->
(<s> ^operator <o> +)
(<o> ^name pour
^empty-jug <i>
^fill-jug <j>)}
Listagem 5 - Adaptação das regras de proposição de operadores.
O segundo passo requer a elaboração de regras atualizáveis que contemplam as combinações possíveis de representações de estado. Ou seja, uma regra para contemplar cada quantidade de água possível em cada um dos jarros para cada ação possível. Para problemas simples, as regras de aprendizado por reforço podem ser criadas facilmente. Neste caso, há um total de 144 regras a serem criadas (3 ações * 2 jarros * 4 valores possíveis de conteúdo para o jarro menor * 6 valores possíveis de conteúdo para o jarro maior). Escrevê-las a mão é bastante trabalhoso e suscetível a erros.
Para resolver este problema, o Soar disponibiliza um comando específico: gp (generate productions). Com este comando, as regras são automaticamente criadas e disponibilizadas na memória de regras para uso. A Listagem 6 mostra o uso do comando gp para criação de regras de aprendizado do programa water-jug-rl.soar considerando as três ações possíveis.
gp {rl*water-jug*empty (state <s> ^name water-jug ^operator <op> + ^jug <j1> <j2>) (<op> ^name empty ^empty-jug.volume [3 5]) (<j1> ^volume 3 ^contents [0 1 2 3]) (<j2> ^volume 5 ^contents [0 1 2 3 4 5]) --> (<s> ^operator <op> = 0)} gp {rl*water-jug*fill (state <s> ^name water-jug ^operator <op> + ^jug <j1> <j2>) (<op> ^name fill ^fill-jug.volume [3 5]) (<j1> ^volume 3 ^contents [0 1 2 3]) (<j2> ^volume 5 ^contents [0 1 2 3 4 5]) --> (<s> ^operator <op> = 0)} gp {rl*water-jug*pour (state <s> ^name water-jug ^operator <op> + ^jug <j1> <j2>) (<op> ^name pour ^empty-jug.volume [3 5]) (<j1> ^volume 3 ^contents [0 1 2 3]) (<j2> ^volume 5 ^contents [0 1 2 3 4 5]) --> (<s> ^operator <op> = 0)}
Listagem 6 - Comandos para geração automática das regras de aprendizado no programa water-jug-rl.soar.
Para o terceiro passo, devem ser criadas as regras de recompensa. Tais regras são como regras comuns no Soar, exceto pelo fato de que elas modificam a estrutura reward-link do estado para refletir a recompensa associada com a decisão atual por parte do agente. Os valores de recompensa devem ser armazenados no elemento value do atributo reward do identificador reward-link (state.reward-link.reward.value). A Listagem 7 mostra a alteração da regra para detecção do estado desejado de modo que uma recompensa é atribuída quando o objetivo é atingido.
sp {water-jug*detect*goal*achieved
(state <s> ^name water-jug
^jug <j>
^reward-link <rl>)
(<j> ^volume 3 ^contents 1)
-->
(write (crlf) |The problem has been solved.|)
(<rl> ^reward.value 10)
(halt)}
Listagem 7 - Regra de recompensa no programa water-jug-rl.soar.
Simulação
A primeira execução do programa water-jug-rl.soar é mostrada na Listagem 8. Algumas execuções subsequentes são suficientes para que o agente aprenda quais operadores devem ser preferidos com maior frequência e o programa, então, resolve o problema com um número bem menor de passos. A Listagem 9 mostra os resultados da execução com o aprendizado por reforço. A Figura 8 mostra o resultado otimizado no SoarDebugger.
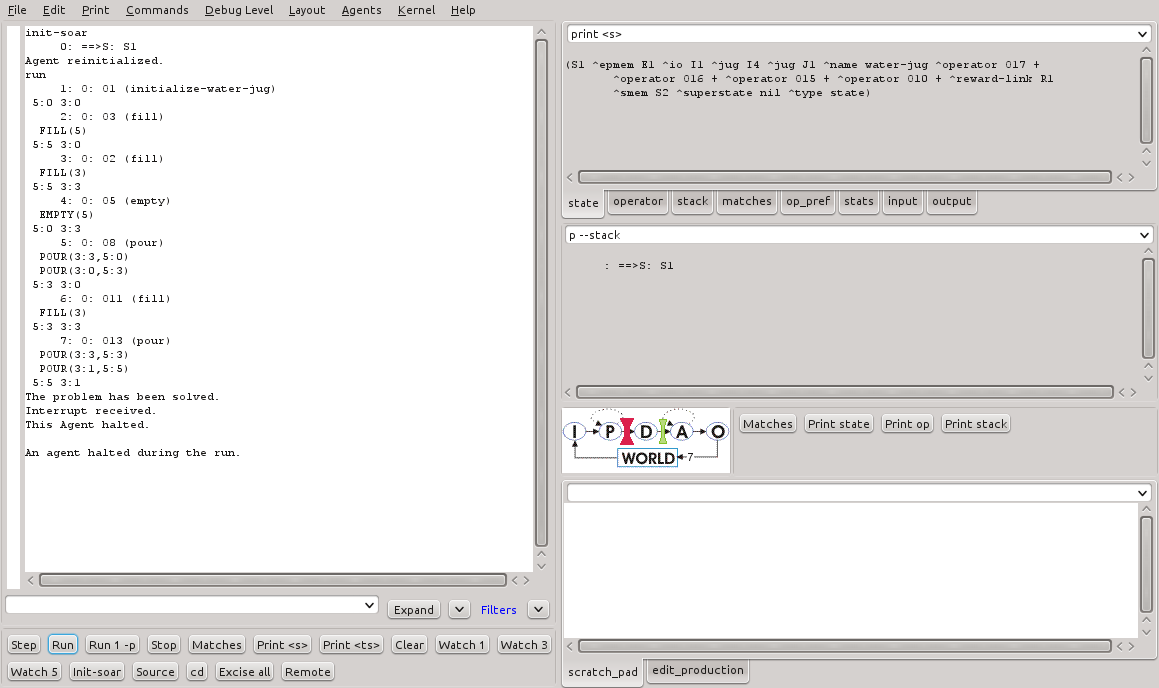
Figura 8 - Resultado da execução do programa water-jug-rl.soar no SoarDebugger.
11 productions excised.
source {/net/nfs1.fee.unicamp.br/export/vol1/home/1sem2013/ra087570/Soar/Agents/water-jug-rl/water-jug-rl.soar}
***************************************************************************************************************
Total: 159 productions sourced.
run
1: O: O1 (initialize-water-jug)
5:0 3:0
2: O: O2 (fill)
FILL(3)
5:0 3:3
3: O: O4 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
4: O: O6 (empty)
EMPTY(5)
5:0 3:0
5: O: O10 (fill)
FILL(5)
5:5 3:0
6: O: O12 (empty)
EMPTY(5)
5:0 3:0
7: O: O8 (fill)
FILL(3)
5:0 3:3
8: O: O14 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
9: O: O17 (fill)
FILL(5)
5:5 3:0
10: O: O18 (fill)
FILL(3)
5:5 3:3
11: O: O22 (empty)
EMPTY(3)
5:5 3:0
12: O: O24 (pour)
POUR(5:5,3:0)
POUR(5:2,3:3)
5:2 3:3
13: O: O29 (pour)
POUR(3:3,5:2)
POUR(3:0,5:5)
5:5 3:0
14: O: O30 (empty)
EMPTY(5)
5:0 3:0
15: O: O33 (fill)
FILL(5)
5:5 3:0
16: O: O31 (fill)
FILL(3)
5:5 3:3
17: O: O35 (empty)
EMPTY(5)
5:0 3:3
18: O: O36 (empty)
EMPTY(3)
5:0 3:0
19: O: O39 (fill)
FILL(3)
5:0 3:3
20: O: O40 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
21: O: O44 (fill)
FILL(3)
5:3 3:3
22: O: O42 (empty)
EMPTY(5)
5:0 3:3
23: O: O49 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
24: O: O51 (fill)
FILL(5)
5:5 3:0
25: O: O52 (fill)
FILL(3)
5:5 3:3
26: O: O55 (empty)
EMPTY(5)
5:0 3:3
27: O: O57 (fill)
FILL(5)
5:5 3:3
28: O: O56 (empty)
EMPTY(3)
5:5 3:0
29: O: O60 (fill)
FILL(3)
5:5 3:3
30: O: O62 (empty)
EMPTY(3)
5:5 3:0
31: O: O59 (empty)
EMPTY(5)
5:0 3:0
32: O: O65 (fill)
FILL(5)
5:5 3:0
33: O: O66 (pour)
POUR(5:5,3:0)
POUR(5:2,3:3)
5:2 3:3
34: O: O70 (empty)
EMPTY(5)
5:0 3:3
35: O: O68 (empty)
EMPTY(3)
5:0 3:0
36: O: O75 (fill)
FILL(3)
5:0 3:3
37: O: O73 (fill)
FILL(5)
5:5 3:3
38: O: O77 (empty)
EMPTY(3)
5:5 3:0
39: O: O78 (empty)
EMPTY(5)
5:0 3:0
40: O: O79 (fill)
FILL(3)
5:0 3:3
41: O: O83 (empty)
EMPTY(3)
5:0 3:0
42: O: O81 (fill)
FILL(5)
5:5 3:0
43: O: O85 (pour)
POUR(5:5,3:0)
POUR(5:2,3:3)
5:2 3:3
44: O: O89 (empty)
EMPTY(5)
5:0 3:3
45: O: O93 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
46: O: O94 (empty)
EMPTY(5)
5:0 3:0
47: O: O96 (fill)
FILL(3)
5:0 3:3
48: O: O98 (fill)
FILL(5)
5:5 3:3
49: O: O101 (empty)
EMPTY(5)
5:0 3:3
50: O: O103 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
51: O: O107 (pour)
POUR(5:3,3:0)
POUR(5:0,3:3)
5:0 3:3
52: O: O111 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
53: O: O113 (fill)
FILL(5)
5:5 3:0
54: O: O116 (pour)
POUR(5:5,3:0)
POUR(5:2,3:3)
5:2 3:3
55: O: O120 (empty)
EMPTY(5)
5:0 3:3
56: O: O124 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
57: O: O128 (pour)
POUR(5:3,3:0)
POUR(5:0,3:3)
5:0 3:3
58: O: O132 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
59: O: O134 (fill)
FILL(5)
5:5 3:0
60: O: O137 (pour)
POUR(5:5,3:0)
POUR(5:2,3:3)
5:2 3:3
61: O: O142 (fill)
FILL(5)
5:5 3:3
62: O: O139 (empty)
EMPTY(3)
5:5 3:0
63: O: O144 (empty)
EMPTY(5)
5:0 3:0
64: O: O145 (fill)
FILL(3)
5:0 3:3
65: O: O147 (fill)
FILL(5)
5:5 3:3
66: O: O150 (empty)
EMPTY(5)
5:0 3:3
67: O: O152 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
68: O: O154 (fill)
FILL(5)
5:5 3:0
69: O: O155 (fill)
FILL(3)
5:5 3:3
70: O: O159 (empty)
EMPTY(3)
5:5 3:0
71: O: O158 (empty)
EMPTY(5)
5:0 3:0
72: O: O160 (fill)
FILL(3)
5:0 3:3
73: O: O163 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
74: O: O167 (fill)
FILL(3)
5:3 3:3
75: O: O165 (empty)
EMPTY(5)
5:0 3:3
76: O: O172 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
77: O: O173 (empty)
EMPTY(5)
5:0 3:0
78: O: O175 (fill)
FILL(3)
5:0 3:3
79: O: O177 (fill)
FILL(5)
5:5 3:3
80: O: O180 (empty)
EMPTY(5)
5:0 3:3
81: O: O181 (fill)
FILL(5)
5:5 3:3
82: O: O183 (empty)
EMPTY(5)
5:0 3:3
83: O: O185 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
84: O: O188 (fill)
FILL(3)
5:3 3:3
85: O: O191 (empty)
EMPTY(3)
5:3 3:0
86: O: O193 (pour)
POUR(5:3,3:0)
POUR(5:0,3:3)
5:0 3:3
87: O: O197 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
88: O: O198 (empty)
EMPTY(5)
5:0 3:0
89: O: O202 (fill)
FILL(5)
5:5 3:0
90: O: O204 (empty)
EMPTY(5)
5:0 3:0
91: O: O200 (fill)
FILL(3)
5:0 3:3
92: O: O206 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
93: O: O211 (pour)
POUR(5:3,3:0)
POUR(5:0,3:3)
5:0 3:3
94: O: O214 (fill)
FILL(5)
5:5 3:3
95: O: O216 (empty)
EMPTY(5)
5:0 3:3
96: O: O218 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
97: O: O222 (pour)
POUR(5:3,3:0)
POUR(5:0,3:3)
5:0 3:3
98: O: O226 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
99: O: O229 (fill)
FILL(3)
5:3 3:3
100: O: O231 (pour)
POUR(3:3,5:3)
POUR(3:1,5:5)
5:5 3:1
The problem has been solved.
Interrupt received.
This Agent halted.
An agent halted during the run.
Listagem 8 - Resultado da primeira execução do programa water-jug-rl.soar.
init-soar
0: ==>S: S1
Agent reinitialized.
run
1: O: O1 (initialize-water-jug)
5:0 3:0
2: O: O3 (fill)
FILL(5)
5:5 3:0
3: O: O2 (fill)
FILL(3)
5:5 3:3
4: O: O5 (empty)
EMPTY(5)
5:0 3:3
5: O: O8 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
6: O: O11 (fill)
FILL(3)
5:3 3:3
7: O: O13 (pour)
POUR(3:3,5:3)
POUR(3:1,5:5)
5:5 3:1
The problem has been solved.
Interrupt received.
This Agent halted.
An agent halted during the run.
Listagem 9 - Resultado da quinta execução subsequente do programa water-jug-rl.soar.
Como pode ser visto nos resultados da simulação, o agente chega à solução do problema muito mais rapidamente quando lança mão do mecanismo de aprendizado. Neste caso em particular, o total de ciclos necessários para obtenção da solução na primeira execução foi de 101. Após 5 execuções sucessivas do programa, o total de ciclos caiu drasticamente para 6.
A execução do programa water-jug-rl.soar cria uma série de regras de aprendizado para suportar o aprendizado por reforço. A Figuras 9 mostra o saída parcial do comando print --rl para as regras criadas na simulação. A Figura 10 mostra três destas regras em detalhes.
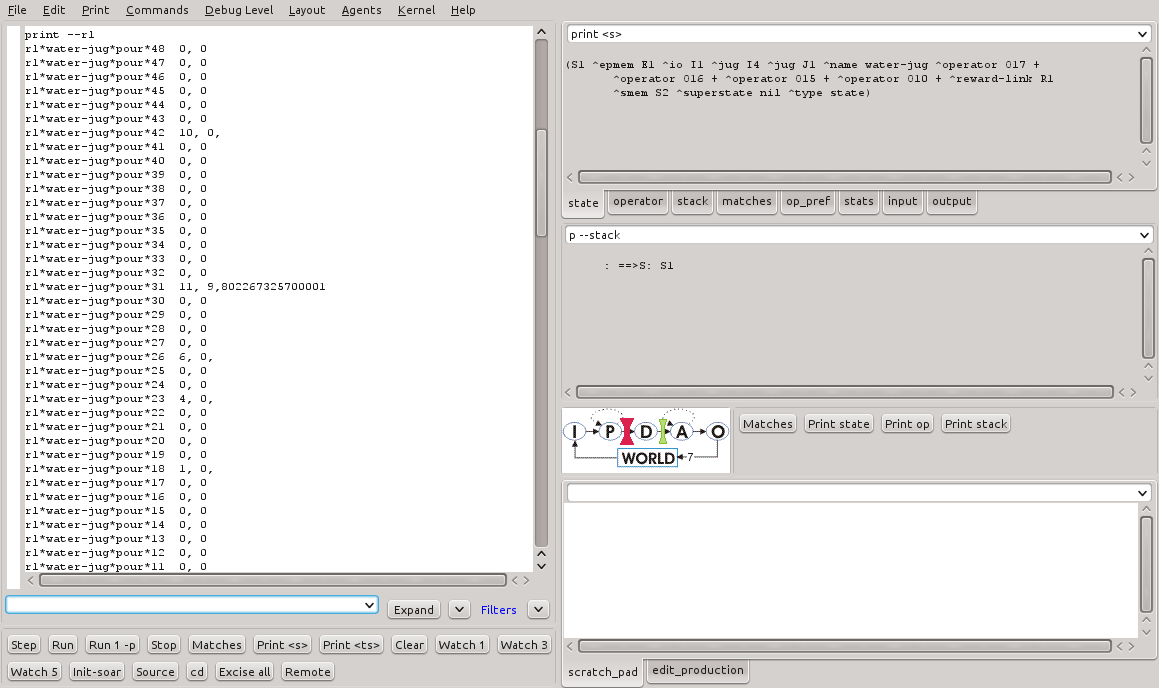
Figura 9 - Regras geradas pelo comando gp para o programa water-jug-rl.soar (1).
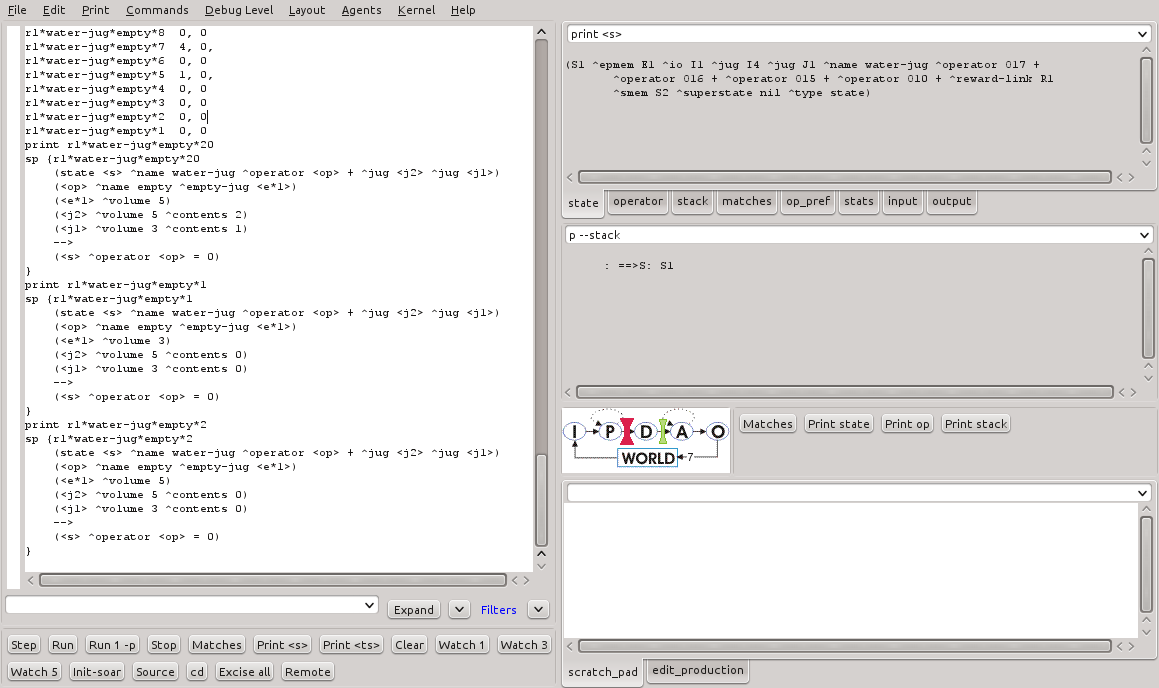
Figura 10 - Regras geradas pelo comando gp para o programa water-jug-rl.soar (2).
Note que as regras criadas possuem um valor numérico de preferência, que representa, como mencionado anterioremente, a preferência pela aplicação do operador quando a regra que verifica o estado é satisfeita.
Políticas de exploração no Aprendizado por Reforço
Nos experimentos com o agente esquerada-direita nas seções anteriores, foi possível constatar que o agente prioriza a escolha pela direção direita, que é aquela que lhe fornece maior recompensa. Ainda sim, é possível que a direção da esquerda seja escolhida em algum momento. Isso ocorre devido à política de exploração em operação. O comando indifferent-selection permite visualizar a política atual e alterá-la conforme a necessidade. A Listagem 10 e a Figura 11 mostram a saída deste comando no SoarDebugger com o parâmetros --stats, que mostra a política atual e os seus parâmetros.
Figura 11 - Saída do comando indifferent-selection --stats.
Exploration Policy: epsilon-greedy Automatic Policy Parameter Reduction: off epsilon: 0.1 epsilon Reduction Policy: exponential epsilon Reduction Rate (exponential/linear): 1/0 temperature: 25 temperature Reduction Policy: exponential temperature Reduction Rate (exponential/linear): 1/0
Listagem 10 - Política de exploração atual no aprendizado por reforço.
Há 5 políticas de exploração disponíveis no Soar:
- Boltzmann;
- Epsilon-greedy;
- Softmax;
- First; e
- Last.
A alteração da política de exploração é feita pelo comando de seleção indiferente conforme a sintaxe: indifferent-selection --policy_name, onde <policy_name> é o nome da política desejada.
Os experimentos conduzidos nesta aula foram realizados com a política epsilon-greedy. De acordo com Laird (2012), Esta política é a mais comum em experimentos de aprendizado por reforço para permitir uma exploração controlada por parâmetros de operadores que não são reconhecidos como os mais preferíveis. O parâmetro desta política é o epsilon.
A política epsilon-greedy pode ser resumida como:
Com probabilidade (1 - epsilon), escolha o operador mais preferido. Com probabilidade epsilon, faça uma seleção aleatória dos operadores indiferentes.
O Soar é iniciado com a política de exploração softmax como padrão. Porém, a primeira vez que o aprendizado por reforço é habilitado, ele altera automaticamente a política para epsilon-greedy. O valor padrão do epsilon é 0.1, estabelecendo que em 90% das vezes o operador com o maior valor de preferência é escolhido, enquando que em 10% das vezes uma seleção aleatória é feita entre os operadores aceitáveis propostos.
A alteração do valor epsilon pode ser feita pelo comando: indifferent-selection --epsilon <value>, onde <value> é um número entre 0 e 1 (inclusive). O valor 0 eliminará a chance de exploração, sendo sempre escolhido o operador mais prefererido. O valor 1 resultará em uma seleção aleatória uniforme.
As Listagens 11, 12 e 13 mostram a execução do programa water-jug-rl.soar com os valores de epsilon iguais a 0, 0,5 e 1, respectivamente.
indifferent-selection --epsilon 0
run
1: O: O1 (initialize-water-jug)
5:0 3:0
2: O: O2 (fill)
FILL(3)
5:0 3:3
3: O: O4 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
4: O: O8 (fill)
FILL(3)
5:3 3:3
5: O: O10 (pour)
POUR(3:3,5:3)
POUR(3:1,5:5)
5:5 3:1
The problem has been solved.
Interrupt received.
This Agent halted.
An agent halted during the run.
Listagem 11 - Resultado da execução do programa water-jug-rl-soar com epsilon = 0.
indifferent-selection --epsilon 0.5
run
1: O: O1 (initialize-water-jug)
5:0 3:0
2: O: O2 (fill)
FILL(3)
5:0 3:3
3: O: O4 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
4: O: O9 (pour)
POUR(5:3,3:0)
POUR(5:0,3:3)
5:0 3:3
5: O: O11 (empty)
EMPTY(3)
5:0 3:0
6: O: O14 (fill)
FILL(3)
5:0 3:3
7: O: O12 (fill)
FILL(5)
5:5 3:3
8: O: O17 (empty)
EMPTY(5)
5:0 3:3
9: O: O19 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
10: O: O22 (fill)
FILL(3)
5:3 3:3
11: O: O25 (empty)
EMPTY(3)
5:3 3:0
12: O: O21 (fill)
FILL(5)
5:5 3:0
13: O: O26 (fill)
FILL(3)
5:5 3:3
14: O: O30 (empty)
EMPTY(3)
5:5 3:0
15: O: O32 (pour)
POUR(5:5,3:0)
POUR(5:2,3:3)
5:2 3:3
16: O: O37 (pour)
POUR(3:3,5:2)
POUR(3:0,5:5)
5:5 3:0
17: O: O38 (empty)
EMPTY(5)
5:0 3:0
18: O: O39 (fill)
FILL(3)
5:0 3:3
19: O: O41 (fill)
FILL(5)
5:5 3:3
20: O: O44 (empty)
EMPTY(5)
5:0 3:3
21: O: O46 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
22: O: O47 (empty)
EMPTY(5)
5:0 3:0
23: O: O49 (fill)
FILL(3)
5:0 3:3
24: O: O53 (empty)
EMPTY(3)
5:0 3:0
25: O: O54 (fill)
FILL(3)
5:0 3:3
26: O: O51 (fill)
FILL(5)
5:5 3:3
27: O: O57 (empty)
EMPTY(5)
5:0 3:3
28: O: O59 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
29: O: O60 (empty)
EMPTY(5)
5:0 3:0
30: O: O62 (fill)
FILL(3)
5:0 3:3
31: O: O66 (empty)
EMPTY(3)
5:0 3:0
32: O: O67 (fill)
FILL(3)
5:0 3:3
33: O: O68 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
34: O: O70 (empty)
EMPTY(5)
5:0 3:0
35: O: O72 (fill)
FILL(3)
5:0 3:3
36: O: O75 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
37: O: O79 (fill)
FILL(3)
5:3 3:3
38: O: O81 (pour)
POUR(3:3,5:3)
POUR(3:1,5:5)
5:5 3:1
The problem has been solved.
Interrupt received.
This Agent halted.
An agent halted during the run.
Listagem 12 - Resultado da execução do programa water-jug-rl-soar com epsilon = 0,5.
indifferent-selection --epsilon 1
run
1: O: O1 (initialize-water-jug)
5:0 3:0
2: O: O2 (fill)
FILL(3)
5:0 3:3
3: O: O4 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
4: O: O8 (fill)
FILL(3)
5:3 3:3
5: O: O6 (empty)
EMPTY(5)
5:0 3:3
6: O: O12 (fill)
FILL(5)
5:5 3:3
7: O: O11 (empty)
EMPTY(3)
5:5 3:0
8: O: O15 (fill)
FILL(3)
5:5 3:3
9: O: O17 (empty)
EMPTY(3)
5:5 3:0
10: O: O18 (fill)
FILL(3)
5:5 3:3
11: O: O14 (empty)
EMPTY(5)
5:0 3:3
12: O: O22 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
13: O: O25 (fill)
FILL(3)
5:3 3:3
14: O: O23 (empty)
EMPTY(5)
5:0 3:3
15: O: O30 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
16: O: O31 (empty)
EMPTY(5)
5:0 3:0
17: O: O33 (fill)
FILL(3)
5:0 3:3
18: O: O37 (empty)
EMPTY(3)
5:0 3:0
19: O: O35 (fill)
FILL(5)
5:5 3:0
20: O: O38 (fill)
FILL(3)
5:5 3:3
21: O: O40 (empty)
EMPTY(5)
5:0 3:3
22: O: O41 (empty)
EMPTY(3)
5:0 3:0
23: O: O44 (fill)
FILL(3)
5:0 3:3
24: O: O46 (empty)
EMPTY(3)
5:0 3:0
25: O: O42 (fill)
FILL(5)
5:5 3:0
26: O: O48 (pour)
POUR(5:5,3:0)
POUR(5:2,3:3)
5:2 3:3
27: O: O50 (empty)
EMPTY(3)
5:2 3:0
28: O: O52 (empty)
EMPTY(5)
5:0 3:0
29: O: O55 (fill)
FILL(3)
5:0 3:3
30: O: O57 (fill)
FILL(5)
5:5 3:3
31: O: O60 (empty)
EMPTY(5)
5:0 3:3
32: O: O62 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
33: O: O63 (empty)
EMPTY(5)
5:0 3:0
34: O: O67 (fill)
FILL(5)
5:5 3:0
35: O: O68 (pour)
POUR(5:5,3:0)
POUR(5:2,3:3)
5:2 3:3
36: O: O73 (fill)
FILL(5)
5:5 3:3
37: O: O75 (empty)
EMPTY(5)
5:0 3:3
38: O: O70 (empty)
EMPTY(3)
5:0 3:0
39: O: O78 (fill)
FILL(3)
5:0 3:3
40: O: O79 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
41: O: O83 (fill)
FILL(3)
5:3 3:3
42: O: O82 (fill)
FILL(5)
5:5 3:3
43: O: O86 (empty)
EMPTY(3)
5:5 3:0
44: O: O87 (empty)
EMPTY(5)
5:0 3:0
45: O: O90 (fill)
FILL(5)
5:5 3:0
46: O: O92 (empty)
EMPTY(5)
5:0 3:0
47: O: O93 (fill)
FILL(5)
5:5 3:0
48: O: O94 (pour)
POUR(5:5,3:0)
POUR(5:2,3:3)
5:2 3:3
49: O: O100 (pour)
POUR(3:3,5:2)
POUR(3:0,5:5)
5:5 3:0
50: O: O101 (empty)
EMPTY(5)
5:0 3:0
51: O: O102 (fill)
FILL(3)
5:0 3:3
52: O: O104 (fill)
FILL(5)
5:5 3:3
53: O: O106 (empty)
EMPTY(3)
5:5 3:0
54: O: O109 (pour)
POUR(5:5,3:0)
POUR(5:2,3:3)
5:2 3:3
55: O: O113 (fill)
FILL(5)
5:5 3:3
56: O: O110 (empty)
EMPTY(3)
5:5 3:0
57: O: O117 (pour)
POUR(5:5,3:0)
POUR(5:2,3:3)
5:2 3:3
58: O: O122 (pour)
POUR(3:3,5:2)
POUR(3:0,5:5)
5:5 3:0
59: O: O123 (empty)
EMPTY(5)
5:0 3:0
60: O: O124 (fill)
FILL(3)
5:0 3:3
61: O: O126 (fill)
FILL(5)
5:5 3:3
62: O: O128 (empty)
EMPTY(3)
5:5 3:0
63: O: O131 (pour)
POUR(5:5,3:0)
POUR(5:2,3:3)
5:2 3:3
64: O: O135 (fill)
FILL(5)
5:5 3:3
65: O: O137 (empty)
EMPTY(5)
5:0 3:3
66: O: O139 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
67: O: O142 (fill)
FILL(3)
5:3 3:3
68: O: O141 (fill)
FILL(5)
5:5 3:3
69: O: O146 (empty)
EMPTY(5)
5:0 3:3
70: O: O148 (pour)
POUR(3:3,5:0)
POUR(3:0,5:3)
5:3 3:0
71: O: O151 (fill)
FILL(3)
5:3 3:3
72: O: O153 (pour)
POUR(3:3,5:3)
POUR(3:1,5:5)
5:5 3:1
The problem has been solved.
Interrupt received.
This Agent halted.
An agent halted during the run.
Listagem 13 - Resultado da execução do programa water-jug-rl-soar com epsilon = 1.
Resumo:
Epsilon | Ciclos
--------+--------
0,0 | 4
0,5 | 38
1,0 | 243
-----------------
3.1.3. Resultados
Nesta atividade foram alguns realizados experimentos que exploraram um mecanismo de aprendizado adicional disponível no Soar: o aprendizado por reforço. Este tipo de aprendizado implementa um mecanismo de seleção probabilística de operadores aceitáveis. Este aprendizado é persistente e incremental na medida em que o valor de recompensa é computado. Os valores de recompensa são armazenados na memória de trabalho e regras de aprendizado devem ser criadas para indicar os valores de preferência de modo a influenciar na escolha do operador conforme a política de exploração.
Os estudos e experimentos realizados nesta aula permitiram:
- o entendimento do mecanismo de aprendizado por reforço;
- o entendimento de como o uso deste mecanismo deve ser implementado em um programa Soar;
- o entendimento sobre as estruturas, estados, regras de aprendizado e valores de preferência;
- o entendimento da política de exploração de operadores conhecido como epsilon-greedy.
Os resultados obtidos durante as simulações envolvendo aprendizado por reforço permitiram, da mesma forma que as simulações realizadas com o chunking, comprovar o ganho de eficiência na busca pela solução do problema. Os operadores são aplicados baseando-se nos seus respectivos valor de preferência. O processo de ajuste destes valores é interativo e estes são persistidos na memória do agente de modo que execuções subsequentes do agente garantem que o aprendizado seja utilizado.
Os resultados obtidos nas simulações variando-se o parâmetro epsilon na política de exploração epsilon-greedy permitiram entender como o ajuste deste valor deve ser balanceado. Um valor adequado de epsilon garante a escolha de operador que conduzem a solução do problema. Em alguns casos, é importante considerar uma certa aleatoriedade no processo de modo a garantir um caráter gerativo no comportamento do agente.
3.2. Atividade 2
3.2.1 Objetivos específicos
- Realizar as atividades propostas no Tutorial 8 do Soar;
- Realizar simulações de programas Soar que façam uso de memória semântica.
3.2.2. Desenvolvimento
O mecanismo de memória semântica no Soar é aquele que permite que o agente deliberadamente armazene e recupere objetos que são persistentes (Laird, 2012). Esta informação acrescenta o conhecimento contido na memória de trabalho de curto prazo e outras memórias de longo prazo, tais como as regras da memória procedural.
O experimento começa com a adição de alguns objetos na memória semântica, como pode ser visto na Listagem 14. O comando responsável pela adição de conteúdo na memória semântica é o smem --add.
smem --add {
(<a> ^name alice ^friend <b>)
(<b> ^name bob ^friend <a>)
(<c> ^name charley)}
Listagem 14 - Adição de objetos na memória semântica.
Para visualizar o conteúdo da memória semântica, o comando smem --print deve ser utilizado. A Figura 12 mostra a saída deste comando no SoarDebugger.
Figura 12 - Visualização do conteúdo da memória semântica.
É possível notar que os identificadores persistidos na memória semântica são prefixados com o símbolo '@'. Ele são chamados de identificadores de longo prazo (long-term identifiers - LTI's). O valor entre colchetes é o valor de bias do objeto, usado durante o retorno do objeto (a ser detalhado mais adiante). Os LTI's não precisam estar, direta ou indiretamente, conectados a um estado.
É possível exportar o conteúdo da memória semântica para visualização com o Graphviz (http://www.graphviz.org). O comando a ser executado é o: command-to-file smem.gv smem --viz. A Listagem 15 mostra a saída deste comando gerada pelo SoarDebugger. A Figura 13 mostra o grafo correspondente dos objetos adicionados na memória semântica.

Figura 13 - Grafo da memória semântica gerado pelo Graphviz.
digraph smem {
node [ shape = doublecircle ];
A1 [ label="A1\n[+1.000]" ];
B1 [ label="B1\n[+2.000]" ];
C3 [ label="C3\n[+3.000]" ];
node [ shape = plaintext ];
A1_0 [ label = "alice" ];
B1_0 [ label = "bob" ];
C3_0 [ label = "charley" ];
A1 -> A1_0 [ label="name" ];
B1 -> B1_0 [ label="name" ];
C3 -> C3_0 [ label="name" ];
A1 -> B1 [ label ="friend" ];
B1 -> A1 [ label ="friend" ];
}
Listagem 15 - Conteúdo do arquivo smem.gv.
A memória semântica mantém objetos persistidos mesmo após o término da execução do programa. Para inicializar a memória semântica, assim que necessário, basta executar o comando smem-init. A Figura 14 mostra a saída da execução deste comando no SoarDebugger.
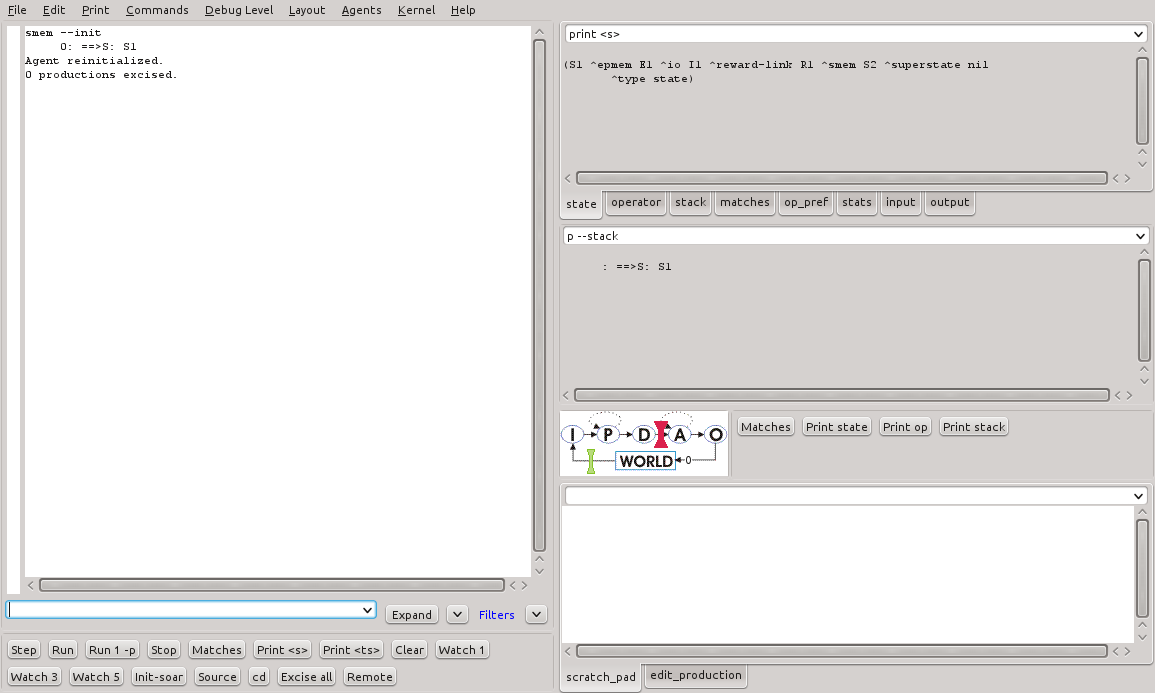
Figura 14 - Resultado da execução do comando smem-init no SoarDebugger.
Após este comando, a memória semântica é reinicializada.
A interação por parte do Agente
Os agentes podem interagir com a memória semântica utilizando uma estrutura específica na memória de trabalho disponibilizada pelo Soar. A Figura 15 mostra a estrutura da memória de trabalho.
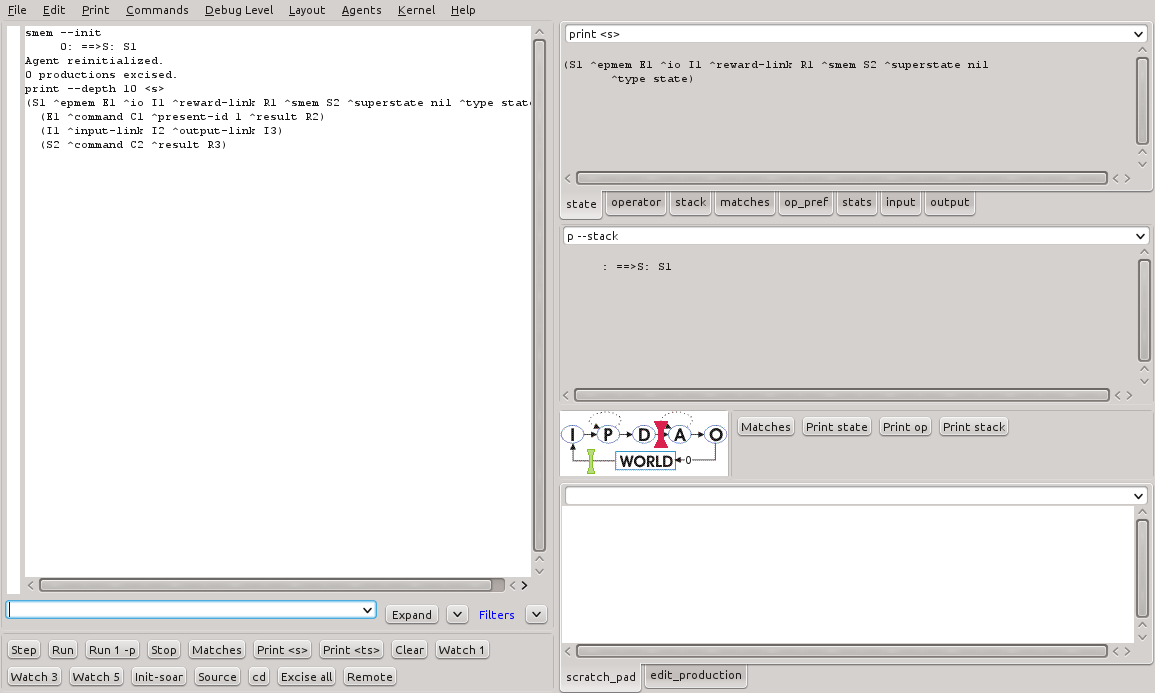
Figura 15 - Estrutura da memória de trabalho no SoarDebugger.
Há WMEs específicos para a memória de trabalho. O principal deles é o (<state> ^smem <smem>). Dois aumentos deste objeto estão presentes: (<smem> ^command <cmd>) e (<smem> ^result <r>). Através destes WMEs, o agente pode popular e manter os objetos na memória tendo o resultado de cada operação informado no objeto de resultado.
Por padrão, todos os mecanismos de aprendizado no Soar estão desabilitados. Para que o agente possa interagir com a memória semântica, é preciso habilitá-la. Isso pode ser feito através do comando: smem --set learning on.
Armazenamento e modificação de objetos na memória semântica pelo agente
Um agente pode armazenar um objeto na memória de trabalho através do comando store. A sintaxe deste comando é: (<cmd> ^store <id>) onde <cmd> é o link command de um estado e <id> é um identificador. O elemento da memória de trabalho que indica o sucesso da operação é o (<r> ^success <id>) onde <r> é atributo de resultado do estado e <id> é o valor indicado no comando store.
O comando store armazena o identificador que é o resultado da execução do comando, bem como quaisquer aumentos deste identificador. Se o identificador não está armazenado na memória de longo prazo, ele será adicionado. Se ele já existir, os aumentos do identificador são sobrescritos.
A Listagem 16 mostra as regras envolvendo um agente que manipula objetos na memória semântica.
sp {propose*init
(state <s> ^superstate nil
-^name)
-->
(<s> ^operator <op> +)
(<op> ^name init)}
sp {apply*init
(state <s> ^operator.name init
^smem.command <cmd>)
-->
(<s> ^name friends)
(<cmd> ^store <a> <b> <c>)
(<a> ^name alice ^friend <b>)
(<b> ^name bob ^friend <a>)
(<c> ^name charley)}
sp {propose*mod
(state <s> ^name friends
^smem.command <cmd>)
(<cmd> ^store <a> <b> <c>)
(<a> ^name alice)
(<b> ^name bob)
(<c> ^name charley)
-->
(<s> ^operator <op> +)
(<op> ^name mod)}
sp {apply*mod
(state <s> ^operator.name mod
^smem.command <cmd>)
(<cmd> ^store <a> <b> <c>)
(<a> ^name alice)
(<b> ^name bob)
(<c> ^name charley)
-->
(<a> ^name alice -)
(<a> ^name anna
^friend <c>)
(<cmd> ^store <b> -)
(<cmd> ^store <c> -)}
Listagem 16 - Regras envolvendo a memória semântica do programa smem-tutorial.soar.
A Figura 16 mostra a execução do programa da Listagem 16 com o nível máximo de depuração (Watch 5). A Listagem 17 mostra o resultado completo da execução.
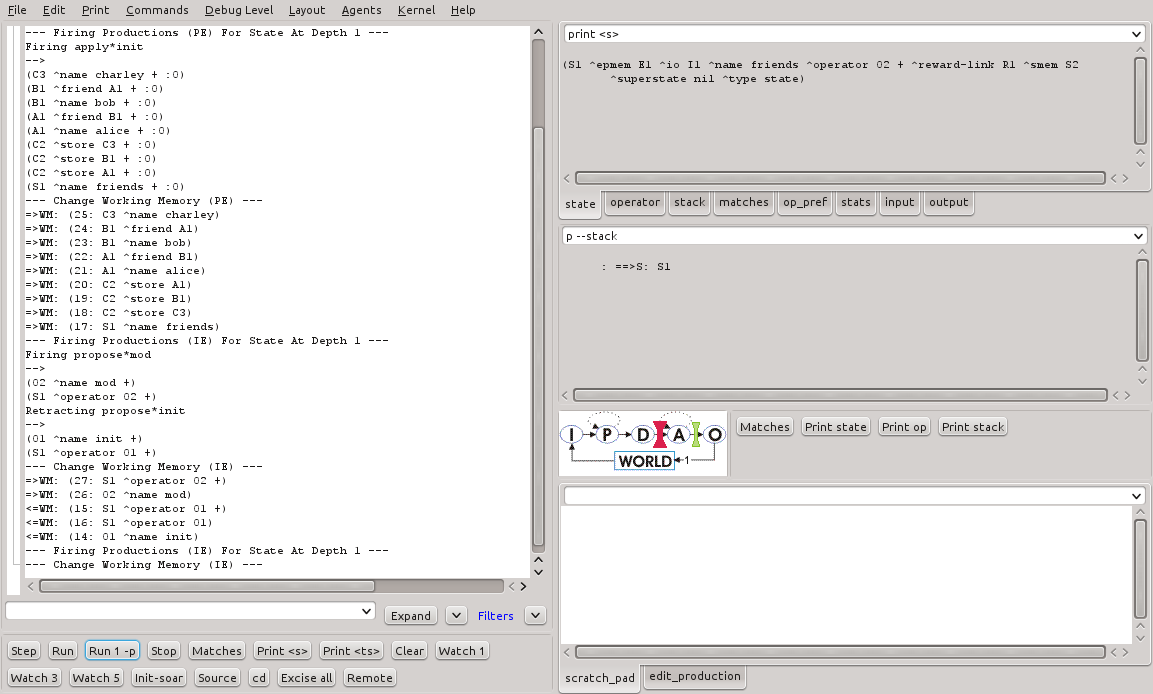
Figura 16 - Resultado da execução do programa smem-tutorial.soar no SoarDebugger.
source {/net/nfs1.fee.unicamp.br/export/vol1/home/1sem2013/ra087570/Documentos/agent-smem-add.soar}
****
Total: 4 productions sourced.
step
1: O: O1 (init)
watch 5
run 1 --phase
--- apply phase ---
--- Firing Productions (PE) For State At Depth 1 ---
Firing apply*init
-->
(C3 ^name charley + :O)
(B1 ^friend A1 + :O)
(B1 ^name bob + :O)
(A1 ^friend B1 + :O)
(A1 ^name alice + :O)
(C2 ^store C3 + :O)
(C2 ^store B1 + :O)
(C2 ^store A1 + :O)
(S1 ^name friends + :O)
--- Change Working Memory (PE) ---
=>WM: (25: C3 ^name charley)
=>WM: (24: B1 ^friend A1)
=>WM: (23: B1 ^name bob)
=>WM: (22: A1 ^friend B1)
=>WM: (21: A1 ^name alice)
=>WM: (20: C2 ^store A1)
=>WM: (19: C2 ^store B1)
=>WM: (18: C2 ^store C3)
=>WM: (17: S1 ^name friends)
--- Firing Productions (IE) For State At Depth 1 ---
Firing propose*mod
-->
(O2 ^name mod +)
(S1 ^operator O2 +)
Retracting propose*init
-->
(O1 ^name init +)
(S1 ^operator O1 +)
--- Change Working Memory (IE) ---
=>WM: (27: S1 ^operator O2 +)
=>WM: (26: O2 ^name mod)
<=WM: (15: S1 ^operator O1 +)
<=WM: (16: S1 ^operator O1)
<=WM: (14: O1 ^name init)
--- Firing Productions (IE) For State At Depth 1 ---
--- Change Working Memory (IE) ---
Listagem 17 - Resultado da execução do programa smem-tutorial.soar.
A regra apply-init, quando disparada, adiciona objetos na memória de trabalho. Ao fim da fase de elaboração, a memória semântica processa o comando, converte os identificadores para a memória de longo prazo e então adiciona-os na memória. A Figura 17 e a Listagem 18 mostram a inclusão dos objetos na memória semântica.
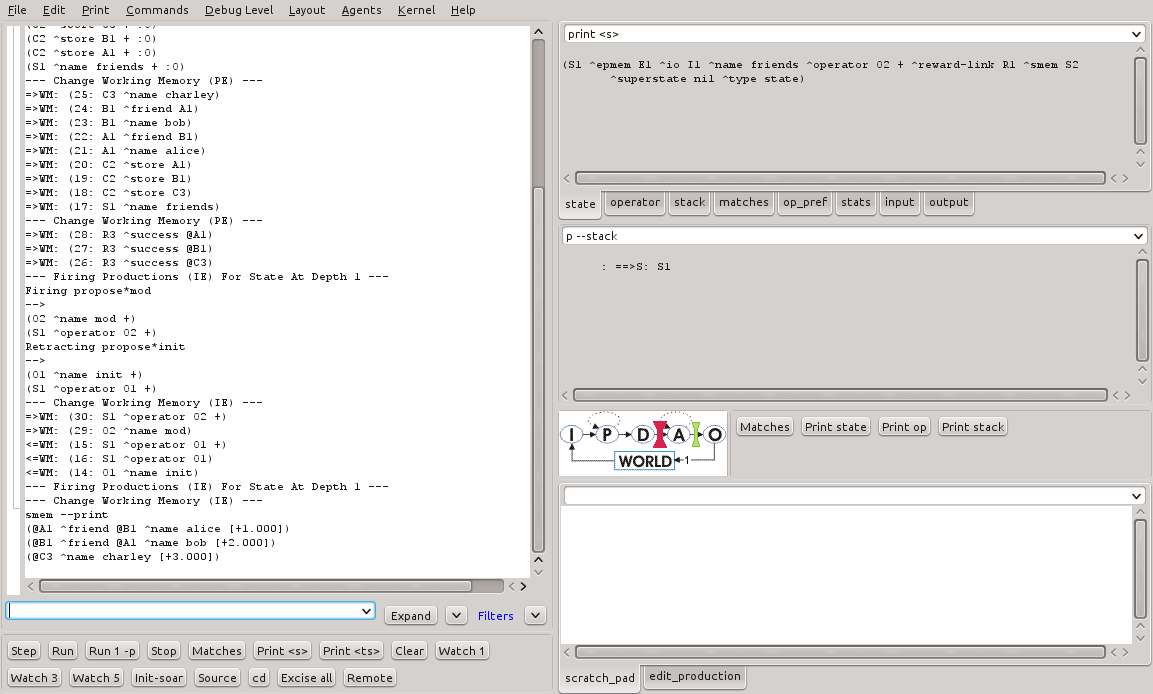
Figura 17 - Visualização da memória semântica do programa smem-tutorial.soar no SoarDebugger.
source {/home/1sem2013/ra087570/Soar/Agents/smem-tutorial/smem-tutorial.soar}
**********
Total: 10 productions sourced.
step
1: O: O1 (init)
run 1 --phase
--- apply phase ---
--- Firing Productions (PE) For State At Depth 1 ---
Firing apply*init
-->
(C3 ^name charley + :O)
(B1 ^friend A1 + :O)
(B1 ^name bob + :O)
(A1 ^friend B1 + :O)
(A1 ^name alice + :O)
(C2 ^store C3 + :O)
(C2 ^store B1 + :O)
(C2 ^store A1 + :O)
(S1 ^name friends + :O)
--- Change Working Memory (PE) ---
=>WM: (25: C3 ^name charley)
=>WM: (24: B1 ^friend A1)
=>WM: (23: B1 ^name bob)
=>WM: (22: A1 ^friend B1)
=>WM: (21: A1 ^name alice)
=>WM: (20: C2 ^store A1)
=>WM: (19: C2 ^store B1)
=>WM: (18: C2 ^store C3)
=>WM: (17: S1 ^name friends)
--- Change Working Memory (PE) ---
=>WM: (28: R3 ^success @A1)
=>WM: (27: R3 ^success @B1)
=>WM: (26: R3 ^success @C3)
--- Firing Productions (IE) For State At Depth 1 ---
Firing propose*mod
-->
(O2 ^name mod +)
(S1 ^operator O2 +)
Retracting propose*init
-->
(O1 ^name init +)
(S1 ^operator O1 +)
--- Change Working Memory (IE) ---
=>WM: (30: S1 ^operator O2 +)
=>WM: (29: O2 ^name mod)
<=WM: (15: S1 ^operator O1 +)
<=WM: (16: S1 ^operator O1)
<=WM: (14: O1 ^name init)
--- Firing Productions (IE) For State At Depth 1 ---
--- Change Working Memory (IE) ---
smem --print
(@A1 ^friend @B1 ^name alice [+1.000])
(@B1 ^friend @A1 ^name bob [+2.000])
(@C3 ^name charley [+3.000])
Listagem 18 - Visualização dos objetos na memória semântica no smem-tutorial.soar.
É possível notar que três objetos foram adicionados na memória semântica, identificados como @A1, @B1 e @C3.
Esta seção apresentou alguns experimentos sobre o armazenamento e manipulação de objetos na memória semântica. A seção a seguir explorará a recuperação destes conhecimentos armazenados, mais especificamente os dois tipos de recuperação disponíveis no Soar.
Recuperação não baseada em exemplo (Non-Cue-Based Retrieval)
A primeira forma de recuperação de conhecimento da memória semântica é a recuperação não baseada em exemplo. Nesta forma de recuperação, o agente conhece a priori o identificador de longo prazo a ser recuperado juntamente com todos os seus aumentos. A sintaxe deste comando é (<cmd> ^retrieve <lti>), onde <lti> é o identificador de longo prazo.
As regras mostradas na Listagem 19 propõem e aplicam operadores cuja finalidade é recuperar objetos previamente armazenados na memória de longo prazo.
sp {propose*ncb-retrieval
(state <s> ^name friends
^smem.command <cmd>)
(<cmd> ^store <a>)
(<a> ^name anna
^friend <f>)
-->
(<s> ^operator <op> + =)
(<op> ^name ncb-retrieval
^friend <f>)}
sp {apply*ncb-retrieval*retrieve
(state <s> ^operator <op>
^smem.command <cmd>)
(<op> ^name ncb-retrieval
^friend <f>)
(<cmd> ^store <a>)
-->
(<cmd> ^store <a> -
^retrieve <f>)}
sp {apply*ncb-retrieval*clean
(state <s> ^operator <op>
^smem.command <cmd>)
(<op> ^name ncb-retrieval
^friend <f>)
(<f> ^<attr> <val>)
-->
(<f> ^<attr> <val> -)}
Listagem 19 - Regras para recuperação não baseada em exemplo.
Diferentemente dos comandos de armazenamento, os comandos de recuperação são processados durante a fase de saída. Somente um comando de recuperação pode ser executado por estado e ciclo de decisão.
A Figura 18 mostra a execução do programa smem-ncb.soar que contém as regras de recuperação não baseadas em exemplo. A Listagem 20 traz o resultado completo da execução juntamente com a saída do comando print, para visualização da estrutura smem na memória de trabalho.
Figura 18 - Execução do programa smem-ncb.soar no SoarDebugger.
source {C:\dev\Soar\Agents\smem-tutorial\smem-ncb.soar}
********
Total: 8 productions sourced.
step
run 1 --phase
1: O: O1 (init)
run 1 --phase
--- apply phase ---
--- Firing Productions (PE) For State At Depth 1 ---
Firing apply*init
-->
(C3 ^name charley + :O)
(B1 ^friend A1 + :O)
(B1 ^name bob + :O)
(A1 ^friend B1 + :O)
(A1 ^name alice + :O)
(C2 ^store C3 + :O)
(C2 ^store B1 + :O)
(C2 ^store A1 + :O)
(S1 ^name friends + :O)
--- Change Working Memory (PE) ---
=>WM: (25: C3 ^name charley)
=>WM: (24: B1 ^friend A1)
=>WM: (23: B1 ^name bob)
=>WM: (22: A1 ^friend B1)
=>WM: (21: A1 ^name alice)
=>WM: (20: C2 ^store A1)
=>WM: (19: C2 ^store B1)
=>WM: (18: C2 ^store C3)
=>WM: (17: S1 ^name friends)
--- Change Working Memory (PE) ---
=>WM: (28: R3 ^success @A1)
=>WM: (27: R3 ^success @B1)
=>WM: (26: R3 ^success @C3)
--- Firing Productions (IE) For State At Depth 1 ---
Firing propose*mod
-->
(O2 ^name mod +)
(S1 ^operator O2 +)
Retracting propose*init
-->
(O1 ^name init +)
(S1 ^operator O1 +)
--- Change Working Memory (IE) ---
=>WM: (30: S1 ^operator O2 +)
=>WM: (29: O2 ^name mod)
<=WM: (15: S1 ^operator O1 +)
<=WM: (16: S1 ^operator O1)
<=WM: (14: O1 ^name init)
--- Firing Productions (IE) For State At Depth 1 ---
--- Change Working Memory (IE) ---
print --depth 10 s2
(S2 ^command C2 ^result R3)
(C2 ^store @B1 ^store @C3 ^store @A1)
(@B1 ^friend @A1 ^name bob)
(@C3 ^name charley)
(@A1 ^friend @B1 ^name alice)
(R3 ^success @B1 ^success @C3 ^success @A1)
run 1 --phase
print --depth 10 s2
(S2 ^command C2 ^result R3)
(C2 ^retrieve @B1)
(@B1 ^friend @A1 ^name bob)
(R3 ^retrieved @B1 ^success @B1)
Listagem 20 - Resultado da execução do programa smem-ncb.soar.
É possível notar que o objeto cujo LTI é @B1 foi recuperado da memória semântica a partir da proposição e aplicação do operador ncb-retrieval. A estrutura do objeto S2 na memória de trabalho indica ainda que a recuperação foi realizada com sucesso.
Interpreta-se, neste caso, que o agente é capaz de recuperar conhecimentos a partir da memória semântica utilizando um identificador de longo prazo exclusivo, que o referencia unicamente nesta memória.
Recuperação baseada em exemplo (Cue-Based Retrieval)
A segunda forma de recuperação de conhecimento da memória semântica é a recuperação baseada em exemplo. Nesta forma de recuperação, o agente não conhece o identificador de longo prazo a ser recuperado. Ele passa, como exemplo, um grafo que representa a estrutura do objeto (conhecimento) a ser recuperado. A sintaxe deste comando é (<cmd> ^query <cue>), onde todos os aumentos desejados tem <cue> como seu identificador.
As regras mostradas na Listagem 21 propõem e aplicam operadores cuja finalidade é recuperar objetos previamente armazenados na memória de longo prazo baseando-se na exemplo informada.
sp {propose*cb-retrieval
(state <s> ^name friends
^smem.command <cmd>)
(<cmd> ^retrieve)
-->
(<s> ^operator <op> + =)
(<op> ^name cb-retrieval)}
sp {apply*cb-retrieval
(state <s> ^operator <op>
^smem.command <cmd>)
(<op> ^name cb-retrieval)
(<cmd> ^retrieve <lti>)
-->
(<cmd> ^retrieve <lti> -
^query <cue>)
(<cue> ^name <any-name>
^friend <lti>)}
Listagem 21 - Regras para recuperação baseada em exemplo.
Estas regras retornam um identificador que atende à duas restrições especificadas: (1) o identificador tem um atributo chamado name (^name) podendo ser o valor qualquer símbolo, e (2) o identificador tem um atributo chamado friend (^friend) cujo valor é o identificador de longo prazo retornado como resultado da aplicação do operador especificado.
A Figura 19 mostra a execução do programa smem-cb.soar que contém as regras de recuperação não baseada em exemplo. A Listagem 22 traz o resultado completo da execução juntamente com a saída do comando print, para visualização da estrutura smem na memória de trabalho.
Figura 19 - Execução do programa smem-cb.soar no SoarDebugger.
source {C:\dev\Soar\Agents\smem-tutorial\smem-cb.soar}
**********
Total: 10 productions sourced.
step
run 1 --phase
1: O: O1 (init)
run 1 --phase
--- apply phase ---
--- Firing Productions (PE) For State At Depth 1 ---
Firing apply*init
-->
(C6 ^name charley + :O)
(B2 ^friend A2 + :O)
(B2 ^name bob + :O)
(A2 ^friend B2 + :O)
(A2 ^name alice + :O)
(C5 ^store C6 + :O)
(C5 ^store B2 + :O)
(C5 ^store A2 + :O)
(S1 ^name friends + :O)
--- Change Working Memory (PE) ---
=>WM: (25: C6 ^name charley)
=>WM: (24: B2 ^friend A2)
=>WM: (23: B2 ^name bob)
=>WM: (22: A2 ^friend B2)
=>WM: (21: A2 ^name alice)
=>WM: (20: C5 ^store A2)
=>WM: (19: C5 ^store B2)
=>WM: (18: C5 ^store C6)
=>WM: (17: S1 ^name friends)
--- Change Working Memory (PE) ---
=>WM: (28: R3 ^success @A2)
=>WM: (27: R3 ^success @B2)
=>WM: (26: R3 ^success @C6)
--- Firing Productions (IE) For State At Depth 1 ---
Firing propose*mod
-->
(O2 ^name mod +)
(S1 ^operator O2 +)
Retracting propose*init
-->
(O1 ^name init +)
(S1 ^operator O1 +)
--- Change Working Memory (IE) ---
=>WM: (30: S1 ^operator O2 +)
=>WM: (29: O2 ^name mod)
<=WM: (15: S1 ^operator O1 +)
<=WM: (16: S1 ^operator O1)
<=WM: (14: O1 ^name init)
--- Firing Productions (IE) For State At Depth 1 ---
--- Change Working Memory (IE) ---
print --depth 10 s2
(S2 ^command C5 ^result R3)
(C5 ^store @B2 ^store @C6 ^store @A2)
(@B2 ^friend @A2 ^name bob)
(@C6 ^name charley)
(@A2 ^friend @B2 ^name alice)
(R3 ^success @B2 ^success @C6 ^success @A2)
run 1 --phase
2: O: O2 (mod)
run 1 --phase
3: O: O3 (ncb-retrieval)
run 1 --phase
4: O: O5 (cb-retrieval)
run 1 --phase
print --depth 10 s2
(S2 ^command C5 ^result R3)
(C5 ^query C7)
(C7 ^friend @C6 ^name A3)
(R3 ^retrieved @C6 ^success @C6)
(@C6 ^name charley)
Listagem 22 - Resultado da execução do programa smem-cb.soar.
É possível notar que o objeto cujo LTI é @C6 foi recuperado da memória semântica a partir da proposição e aplicação do operador cb-retrieval. A estrutura do objeto S2 na memória de trabalho indica ainda que a recuperação foi realizada com sucesso. Um detalhe importante é que o LTI @C6 não é conhecido. Ele foi recuperado porque satisfaz as restrições especificadas na regra de aplicação do operador cb-retrieval.
Interpreta-se, neste caso, que o agente é capaz de recuperar conhecimentos a partir da memória semântica utilizando apenas informações parciais que se dispõe no momento. Esta característica tem uma relevância crucial para o uso mais abrangente de conhecimentos armazenados nesta memória.
3.2.3. Resultados
Nesta atividade foram alguns realizados experimentos que exploraram um tipo adicional de memória disponível no Soar: a memória semântica. Este tipo de memória implementa um mecanismo para armazenamento e recuperação de conhecimentos que complementam aqueles disponíveis na memória de trabalho. Os resultados obtidos nas simulações permitiram testar as várias operações envolvidas na manipulação deste mecanismo.
Os estudos e experimentos realizados nesta aula permitiram:
- o entendimento sobre a ativação e inicialização da memória semântica;
- o entendimento sobre a manutenção de conhecimentos nesta memória (inclusão, alteração e exclusão);
- o entendimento sobre as formas de recuperação de conhecimentos disponíveis.
O agente pode dispor deste tipo de memória para armazenamento e recuperação de conhecimentos declarativos (ontologias). Para o Soar, este tipo de conhecimento deve ser representado utilizando um grafo. Este grafo, que representa um conhecimento adqurido, pode ser persistido nesta memória. Quando necessário, o agente pode recuperar este conhecimento a partir do seu conceito ou de características parciais que se tem conhecimento.
3.3. Atividade 3
3.3.1 Objetivos específicos
- Realizar as atividades propostas no Tutorial 8 do Soar;
- Realizar simulações de programas Soar que façam uso de memória epsódica.
3.3.2. Desenvolvimento
A memória episódica no Soar é um mecanismo que automaticamente captura, armazena e temporiamente indexa estados internos do agente com o suporte a uma interface de conteúdo endereçavel para recuperação de experiências autobiográficas anteriores (Laird, 2012). Da mesma forma que a memória semântica, os conhecimentos contidos na memória episódica complementam aqueles disponíveis na memória de trabalho e outras memórias de longo prazo, tais como as regras na memória procedural.
Os experimentos desta atividade explorarão a manipulação da memória episódica através da implementação de programas Soar com esta finalidade. Serão explorados todos os comandos envolvidos nas operações básicas envolvendo memória episódica.
Para ativar a captura de episódios no Soar, alguns comandos devem ser executados conforme mostrado na Listagem 23.
epmem --set trigger dc
epmem --set learning on
watch --epmem
Listagem 23 - Ativação da memória epsódica no Soar.
A Figura 20 mostra o resultado da execução destes comandos no SoarDebugger.
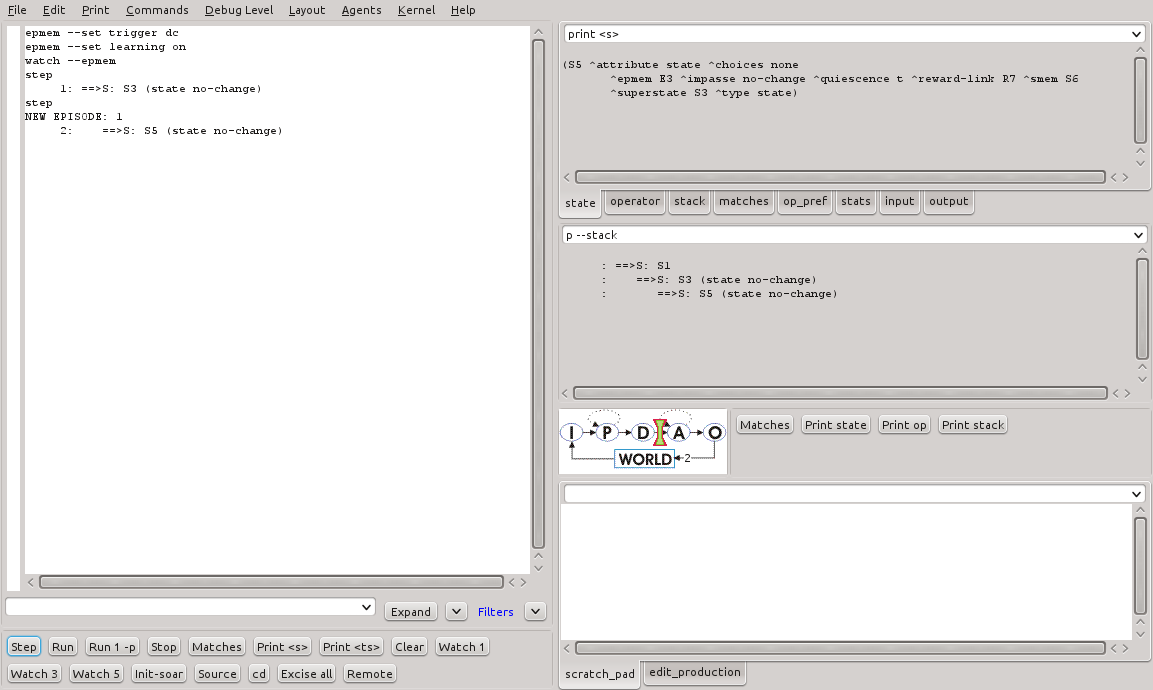
Figura 20 - Execução de comandos de ativação da memória episódica no SoarDebugger.
Ao executar o programa, é possível ver que o Soar automaticamente informa sobre a criação de um episódio: NEW EPISODE: 1. Esta é uma indicação de que o episódio, com id 1, foi salvo na memória episódica.
A visualização do conteúdo da memória episódica pode ser feita utilizando o comando epmem --print <id>, onde <id> é o identificador do episódio salvo. A Figura 21 e a Listagem 24 mostram o resultado deste comando no SoarDebugger.
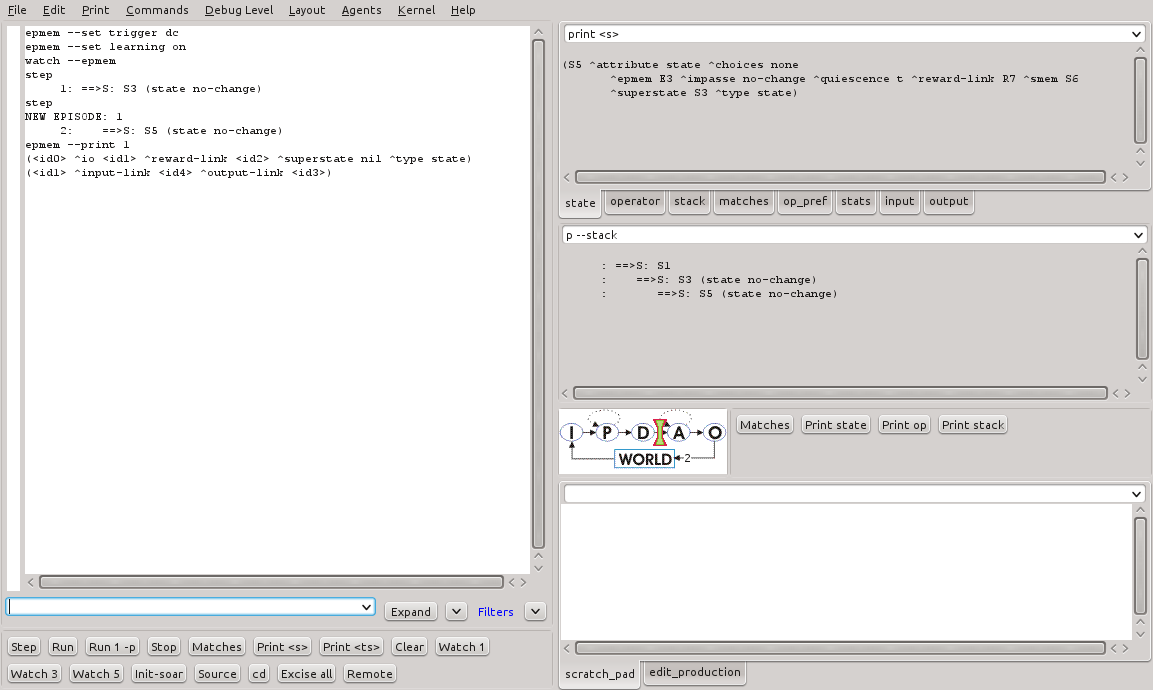
Figura 21 - Resultado da execução do comando epmem --print no SoarDebugger.
epmem --set trigger dc
epmem --set learning on
watch --epmem
step
1: ==>S: S3 (state no-change)
step
NEW EPISODE: 1
2: ==>S: S5 (state no-change)
epmem --print 1
(<id0> ^io <id1> ^reward-link <id2> ^superstate nil ^type state)
(<id1> ^input-link <id4> ^output-link <id3>)
Listagem 24 - Resultado da execução do comando epmem --print.
A visualização da estrutura armazenada como sendo o episódio pode ser visto na Figura 22 (gerada utilizando o programa Graphviz).
Figura 22 - Grafo representando a estrutura do episódio 1.
Armazenamento de episódios
O Soar dispõe de uma série de parâmetros que controlam o modo como as operações envolvendo a memória episódica é realizada. Estes comandos são descritos a seguir:
- epmem --set learning on: ativa a captura de episódios e habilita o uso de operações envolvendo a memória episódica;
- epmem --set trigger dc: indica para o Soar o instante de disparo para captura de episódios. Por padrão, o Soar armazena novos episódios assim que um novo elemento é adicionado na memória de trabalho. Neste caso, o disparo é alterado para que ocorra a cada ciclo de decisão (dc) apenas.
- epmem --set phase selection: indica para o Soar a fase em que o processamento das operações com a memória episódica deve ocorrer. Por padrão, ocorrerá no final da fase de saída. Neste caso, estamos indicando para que ocorra no final da fase de decisão.
- epmem --get exclusions <attribute>: indica para o Soar quais elementos na memória de trabalho serão excluídos. Em certos casos não é necessário o armazenamento de certas estruturas da memória de trabalho. Neste caso, ao ser informado o atributo a ser excluído, todos os aumentos deste atributo não são considerados na captura do episódio.
Para visualização das mensagens emitidas pelo Soar de todas as operações envolvendo a memória episódica, basta utilizar o comando watch --epmem.
A Figura 23 mostra a saída do comando epmem --get exclusions em relação ao atributo test, utilizado neste experimento.
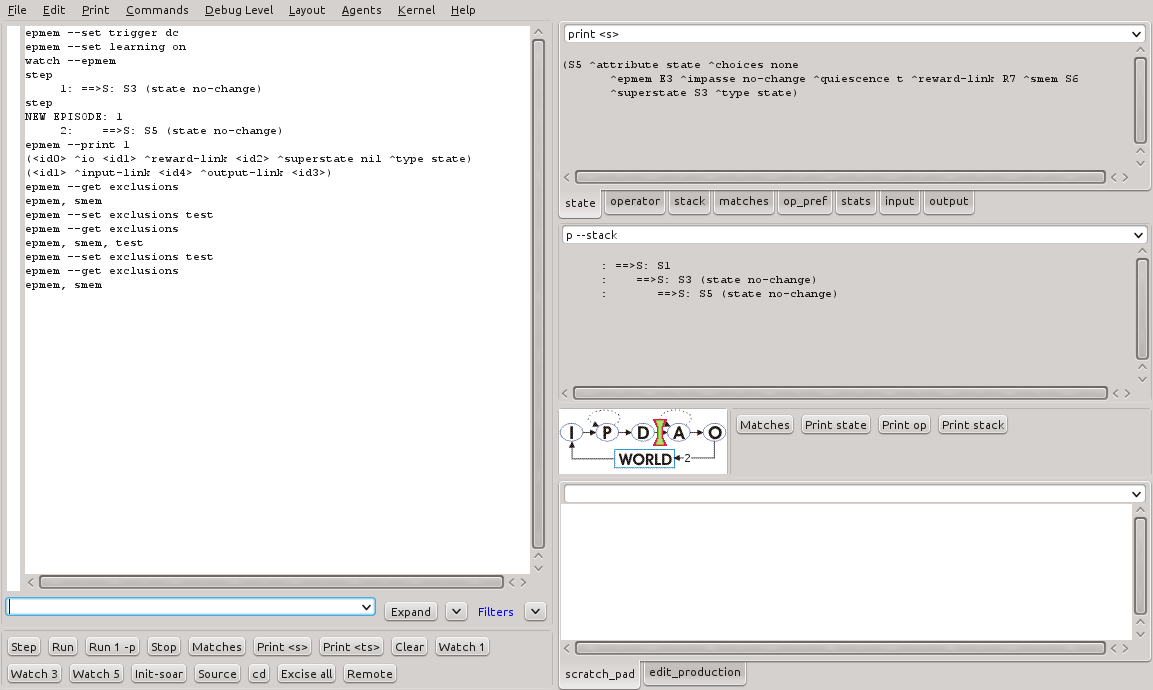
Figura 23 - Resultado da execução do comando epmem --get exclusions no SoarDebugger.
Como pode ser visto, o atributo test é adicionado na lista de atributos a serem desprezados durante a captura de epsódios. Em seguida, com a execução do mesmo comando, ele é retirado desta lista.
Interação do agente com a memória episódica
O agente interage com a memória episódica por meio de estruturas específicas na memória de trabalho. O Soar cria automaticamente um link para esta memória chamado epmem. A Figura 24 e a Listagem 25 trazem o resultado do comando print --depth 10 que mostra a estrutura deste objeto na memória de trabalho.
Figura 24 - Visualização da estrutura epmem no SoarDebugger.
print --depth 10 <s> (S5 ^attribute state ^choices none ^epmem E3 ^impasse no-change ^quiescence t ^reward-link R7 ^smem S6 ^superstate S3 ^type state) (E3 ^command C5 ^present-id 2 ^result R8) (S6 ^command C6 ^result R9) (S3 ^attribute state ^choices none ^epmem E2 ^impasse no-change ^quiescence t ^reward-link R4 ^smem S4 ^superstate S1 ^type state) (E2 ^command C3 ^present-id 2 ^result R5) (S4 ^command C4 ^result R6) (S1 ^epmem E1 ^io I1 ^reward-link R1 ^smem S2 ^superstate nil ^type state) (E1 ^command C1 ^present-id 2 ^result R2) (I1 ^input-link I2 ^output-link I3) (S2 ^command C2 ^result R3)
Listagem 25 - Visualização da estrutura epmem.
O agente, usando as regras, popula e mantém o link command e a arquitetura popula e mantém o link result. Quando episódios são armazenados, o atributo present-id tem seu valor atualizado para indicar o identificador do episódio atual. Este é sempre um valor interior positivo.
Recuperação baseada em exemplo (Cue-Based Retrieval)
Este método de recuperação de conhecimentos da memória episódica baseia-se na solicitação por parte do agente de conteúdos da memória episódica que melhor satisfaçam o exemplo da memória de trabalho passado como referência. A sintaxe deste comando é (<cmd> ^query <cue>), onde <cue> é a raiz do grafo que representa o exemplo a ser consultado.
Conceitualmente, a memória episódica compara o exemplo informando com todos os episódios armazenados na memória episódica, atribui pontos para cada um deles, e retorna o episódio mais recente com a maior pontuação.
Os episódios são pontuados a partir de elementos da memória de trabalho terminais, ou WMEs-folha (vértices-folha), considerando o modelo de representação baseado em grafos. Um WME-folha tem um valor, que é uma constante, um identificador de longo prazo ou um identificador de curto prazo sem aumentos. Um WME folha é satisfeito, em relação a um episódio particular, se existir um caminho, ou uma sequência de WMEs, a partir do vértice raiz daquele WME-folha, em que todos os atributos de todos os WMEs intermediários coincidem exatamente com o exemplo e com os identificadores de curto prazo do exemplo.
Este método opera de modo similar a forma como as variáveis nas condições das regras são ligadas à identificadores específicos na memória de trabalho. Entretanto, a pontuação de episódios é disjuntiva em relação aos WMEs-folha, ao passo que o casamento de regras é conjuntivo em relação às condições das produções. Por padrão, a pontuação de um episódio é simplesmente o número de WMEs-folha que foram satisfeitos.
Para demonstrar este mecanismo um o experimentos será conduzido. Este experimento realiza a recuperação de um episódio da memória episódica a partir de um exemplo informado. A Listagem 26 mostra as regras envolvidas no programa deste experimento.
sp {propose*init
(state <s> ^superstate nil
-^name)
-->
(<s> ^operator <op> + =)
(<op> ^name init)}
sp {apply*init
(state <s> ^operator <op>)
(<op> ^name init)
-->
(<s> ^name epmem
^feature2 value
^feature value3
^id <e2>
^id <e3>
^other-id <e4>)
(<e2> ^sub-feature value2)
(<e3> ^sub-id <e5>)
(<e4> ^sub-id <e6>
^sub-feature value2)}
sp {epmem*propose*cbr
(state <s> ^name epmem
-^epmem.command.<cmd>)
-->
(<s> ^operator <op> + =)
(<op> ^name cbr)}
sp {epmem*apply*cbr-clean
(state <s> ^operator <op>
^feature2 <f2>
^feature <f>
^id <e2>
^id <e3>
^other-id <e4>)
(<e2> ^sub-feature value2)
(<e3> ^sub-id)
(<op> ^name cbr)
-->
(<s> ^feature2 <f2> -
^feature <f> -
^id <e2> -
^id <e3> -
^other-id <e4> -)}
sp {epmem*apply*cbr-query
(state <s> ^operator <op>
^epmem.command <cmd>)
(<op> ^name cbr)
-->
(<cmd> ^query <n1>)
(<n1> ^feature value
^id <n2>)
(<n2> ^sub-feature value2
^sub-id <n3>)}
Listagem 26 - Regras para manipulação da memória episódica do programa epmem-tutorial.soar.
A execução passo-a-passo deste programa no SoarDebugger é mostrada na Figura 25 e na Listagem 27.

Figura 25 - Resultado da execução parcial do programa epmem-tutoral.soar no SoarDebugger.
source {/net/nfs1.fee.unicamp.br/export/vol1/home/1sem2013/ra087570/Soar/Agents/epmem-tutorial/epmem-tutorial.soar}
********
Total: 8 productions sourced.
epmem --set trigger dc
epmem --set learning on
watch --epmem
step
1: O: O1 (init)
run 1 --phase
print --depth 10 s1
(S1 ^epmem E1 ^feature value3 ^feature2 value ^id E2 ^id E3 ^io I1 ^name epmem
^operator O2 + ^other-id E4 ^reward-link R1 ^smem S2 ^superstate nil
^type state)
(E1 ^command C1 ^present-id 1 ^result R2)
(E2 ^sub-feature value2)
(E3 ^sub-id E5)
(I1 ^input-link I2 ^output-link I3)
(O2 ^name cbr)
(E4 ^sub-feature value2 ^sub-id E6)
(S2 ^command C2 ^result R3)
step
NEW EPISODE: 1
2: O: O2 (cbr)
run 1 --phase
print --depth 10 s1
(S1 ^epmem E1 ^io I1 ^name epmem ^operator O3 + ^reward-link R1 ^smem S2
^superstate nil ^type state)
(E1 ^command C1 ^present-id 2 ^result R2)
(C1 ^query N1)
(N1 ^feature value ^id N2)
(N2 ^sub-feature value2 ^sub-id N3)
(I1 ^input-link I2 ^output-link I3)
(O3 ^name next)
(S2 ^command C2 ^result R3)
Listagem 27 - Resultado da execução parcial do programa epmem-tutorial.soar.
É possível notar que o episódio #1 foi armazenado e, após a aplicação do operador cbr, a estrutura do episódio exemplo foi adicionado à estrutura command do link epmem.
A execução de mais um ciclo de decisão deve ser feito de modo a criar um novo episódio e então realizar a recuperação a partir do exemplo. A Figura 26 e a Listagem 28 mostram o resultado obtido nesta execução.
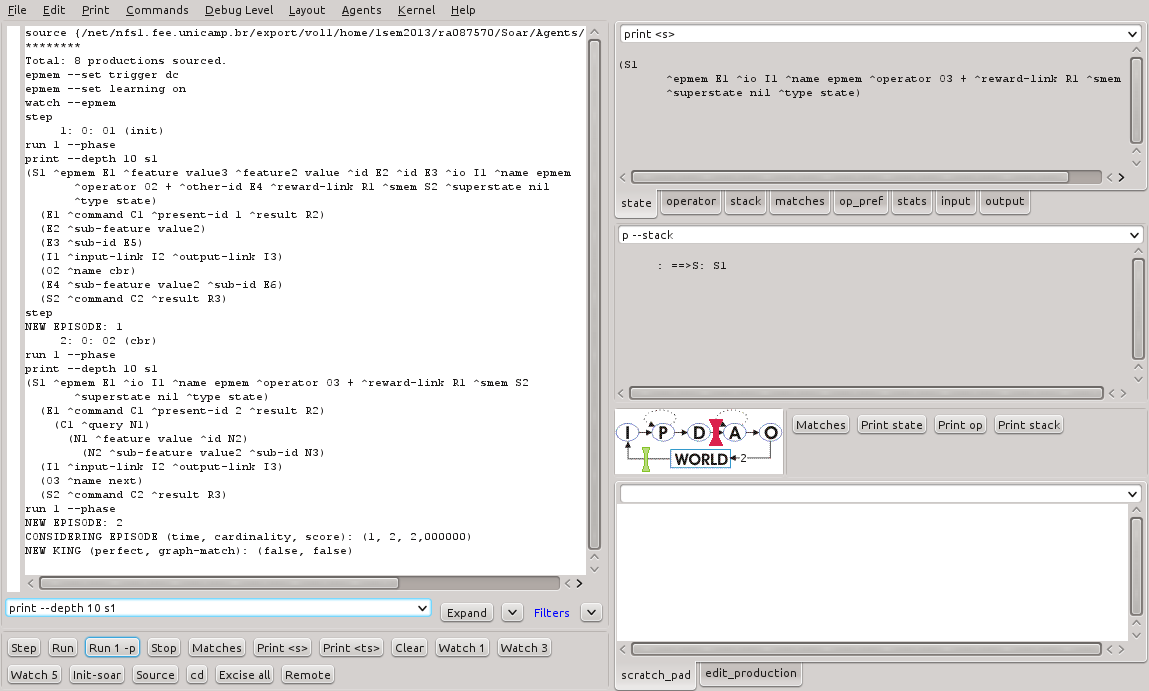
Figura 26 - Resultado da continuação da execução do programa epmem-tutoral.soar no SoarDebugger.
source {/net/nfs1.fee.unicamp.br/export/vol1/home/1sem2013/ra087570/Soar/Agents/epmem-tutorial/epmem-tutorial.soar} ******** Total: 8 productions sourced. epmem --set trigger dc epmem --set learning on watch --epmem step 1: O: O1 (init) run 1 --phase print --depth 10 s1 (S1 ^epmem E1 ^feature value3 ^feature2 value ^id E2 ^id E3 ^io I1 ^name epmem ^operator O2 + ^other-id E4 ^reward-link R1 ^smem S2 ^superstate nil ^type state) (E1 ^command C1 ^present-id 1 ^result R2) (E2 ^sub-feature value2) (E3 ^sub-id E5) (I1 ^input-link I2 ^output-link I3) (O2 ^name cbr) (E4 ^sub-feature value2 ^sub-id E6) (S2 ^command C2 ^result R3) step NEW EPISODE: 1 2: O: O2 (cbr) run 1 --phase print --depth 10 s1 (S1 ^epmem E1 ^io I1 ^name epmem ^operator O3 + ^reward-link R1 ^smem S2 ^superstate nil ^type state) (E1 ^command C1 ^present-id 2 ^result R2) (C1 ^query N1) (N1 ^feature value ^id N2) (N2 ^sub-feature value2 ^sub-id N3) (I1 ^input-link I2 ^output-link I3) (O3 ^name next) (S2 ^command C2 ^result R3) run 1 --phase NEW EPISODE: 2 CONSIDERING EPISODE (time, cardinality, score): (1, 2, 2,000000) NEW KING (perfect, graph-match): (false, false)
Listagem 28 - Resultado da continuação da execução do programa epmem-tutoral.soar.
Como era esperado, após a conclusão do ciclo de decisão, um novo episódio (#2) foi armazenado na memória episódica e então processado o comando de recuperação. A primeira linha em azul da Listagem 28 indica que a memória episódica comparou o exemplo para o episódio #1, foi encontrado que a cardinalidade do conjunto de WMEs-folha satisfeitos foi 2 e que a pontuação para o episódio foi 2. Uma vez que este foi considerado o primeiro episódio, ele foi indicado como "Rei" (da montanha). No entanto, como pode ser visto, o episódio #1 não teve a pontuação perfeita (2 pontos, em um total de 3). O casamento dos grafos não foi avaliado e não foi, então, obtido sucesso. Além disso, o episódio #2 não tem quaisquer atributos em comum com o exemplo informado. Desta forma, a memória episódica não considera este fato como uma otimização de performance.
Ao ser impresso o conteúdo completo da memória episódica, podemos ver o resultado bem sucedido da recuperação. A Figura

Figura 27 - Resultado da recuperação de episódio no programa epmem-tutoral.soar no SoarDebugger.
... print --depth 10 e1 (E1 ^command C1 ^present-id 3 ^result R2) (C1 ^query N1) (N1 ^feature value ^id N2) (N2 ^sub-feature value2 ^sub-id N3) (R2 ^cue-size 3 ^graph-match 0 ^match-cardinality 2 ^match-score 2, ^memory-id 1 ^normalized-match-score 0,6666666666666666 ^present-id 3 ^retrieved R4 ^success N1) (R4 ^feature value3 ^feature2 value ^id I5 ^id I6 ^io I4 ^name epmem ^operator* O5 ^other-id O4 ^reward-link R5 ^superstate nil ^type state) (I5 ^sub-feature value2) (I6 ^sub-id S3) (I4 ^input-link I7 ^output-link O6) (O5 ^name cbr) (O4 ^sub-feature value2 ^sub-id S4)
Listagem 29 - Resultado da recuperação de episódio no programa epmem-tutoral.soar.
As linhas em vermelho na Listagem 29 contém o exemplo utilizado para recuperação. As linhas em azul mostram o conteúdo da estrutura que contém o resultado da recuperação. Após um casamento completo entre o exemplo e o episódio armazenado, o episódio #1 é retornado, conforme indicado por ^memory-id 1. Como pode ser visto, o objeto R4 representa a estrutura deste episódio, com todas subestruturas recuperadas da memória episódica para a memória de trabalho.
Progressão temporal e recuperação de episódios
Um outro método pelo qual o agente pode ter acesso aos episódios armazenados é através da recuperação do episódio que está temporalmente antes ou depois do último episódio que foi retornado. A sintaxe deste comandos são, respectivamente, (<cmd> ^previous <id>) e (<cmd> ^next <id>) onde <id> é qualquer identificador.
Um outro experimento proposto propõe o teste deste mecanismo. Para tal, é necessário acrescentar as regras descritas na Listagem 30 no programa da seção anterior.
sp {epmem*propose*next
(state <s> ^name epmem
^epmem.command.query)
-->
(<s> ^operator <op> + =)
(<op> ^name next)}
sp {epmem*apply*next
(state <s> ^operator <op>
^epmem.command <cmd>)
(<op> ^name next)
(<cmd> ^query <q>)
-->
(<cmd> ^query <q> -
^next <next>)}
Listagem 29 - Resultado da recuperação de episódio no programa epmem-tutoral.soar.
Estas regras retornarão o episódio que temporariamente é sucede o episódio retornado na seção anterior. A Figura 28 e Listagem 30 mostram o resultado da execução destas regras.

Figura 28 - Resultado da recuperação baseada em progressão temporal no SoarDebugger.
source {C:\dev\Soar\Agents\epmem-tutorial\epmem-tutorial-progression.soar}
********
Total: 8 productions sourced.
run
1: O: O1 (init)
NEW EPISODE: 1
2: O: O2 (cbr)
NEW EPISODE: 2
CONSIDERING EPISODE (time, cardinality, score): (1, 2, 2.000000)
NEW KING (perfect, graph-match): (false, false)
3: O: O3 (next)
NEW EPISODE: 3
Interrupt received.
This Agent halted.
An agent halted during the run.
print --depth 10 e1
(E1 ^command C1 ^present-id 4 ^result R2)
(C1 ^next N4)
(R2 ^memory-id 2 ^present-id 4 ^retrieved R6 ^success N4)
(R6 ^io I8 ^name epmem ^operator* O7 ^reward-link R7 ^superstate nil
^type state)
(I8 ^input-link I9 ^output-link O8)
(O7 ^name next)
Listagem 30 - Resultado da recuperação baseada em progressão temporal.
Como esperado, o episódio retornado foi o episódio #2, que é temporalmente subsequente ao episódio #1.
3.3.3. Resultados
Nesta atividade foram alguns realizados experimentos que exploraram um tipo adicional de memória disponível no Soar: a memória episódica. Este tipo de memória implementa um mecanismo para armazenamento e recuperação de conhecimentos baseados que complementam aqueles disponíveis na memória de trabalho. Os resultados obtidos nas simulações, da mesma forma que na memória semântica, permitiram testar as várias operações envolvidas na manipulação deste mecanismo.
Os estudos e experimentos realizados nesta aula permitiram:
- o entendimento sobre a ativação e inicialização da memória episódica;
- o entendimento sobre a manutenção de conhecimentos nesta memória (inclusão, alteração e exclusão de episódios);
- o entendimento sobre as formas de recuperação de conhecimentos disponíveis (recuperação baseada em exemplo e recuperação baseada em progressão temporal).
O agente pode dispor deste tipo de memória para armazenamento e recuperação de experiências vivenciadas ao longo tempo. Para o Soar, este tipo de conhecimento deve ser representado utilizando um grafo. Este grafo, que representa um episódio específico vivido pelo agente, pode ser persistido nesta memória. Um episódio pode ser entendido no Soar como a captura sucessiva de estados e seus atributos no transcorrer da execução do agente. Esta captura é uma espécie de "fotografia" da mente do agente em um determinado instante. Episódios são armazenados na memória episódica para que, quando desejado, o agente possa consultá-la a fim de lembrar-se de uma situação vivenciada anteriormente.
4. Conclusão
Nesta aula foram contemplados importantes aspectos da arquitetura Soar: o aprendizado por reforço e as memórias semântica e episódica. Estes aspectos são implementados por meio de mecanismos e operações providos pela arquitetura para fins específicos.
O aprendizado por reforço é um importante método de aprendizado para sistemas inteligentes. Ele possibilita que o agente altere o seu comportamento dinamicamente ao longo do tempo a partir de uma sinalização de recompensas. Esta alteração gera novos comportamentos mais adequados à busca pela solução do problema em questão. Mais especificamente, o agente pode optar (estatisticamente) pela seleção de operadores cuja aplicação aumentam a probabilidade de obtenção da solução. Este recurso é importante porque permite um ganho de performance na busca pelo espaço de problemas.
As memórias semânticas e episódicas disponibilizam, juntas, conhecimentos adicionais que podem ser utilizados pelo agente conforme a sua necessidade e a natureza do problema a ser resolvido. A memória semântica permite o armazenamento e recuperação de conceitos (ontologias) para a memória de trabalho. Estes conceitos podem representar conhecimentos úteis na solução de problemas, como por exemplo, a descrição de características dos objetos percebidos no ambiente. A memória episódica, por sua vez, permite o armazenamento e recuperação de episódios (experiências vivenciadas) para a memória de trabalho. Da mesma forma, estes episódios podem ser úteis na solução de problemas, especialmente nas situações em que o agente precisa recordar-se de um fato no passado. Um exemplo seria o armazenamento de informações sobre locais já visitados em um problema de navegação no ambiente.
.Por fim, estes mecanismos adicionais permitem que os agentes apresentem um comportamento ainda mais sofisticado que aqueles possíveis até aqui. Isto porque, agora, é possível dispor da memória de longo prazo para armazenamento e recuperação de ontologias e experiências vivenciadas previamente. Estes mecanismos estendem a capacidade de aprendizado do agente e reforça o seu aracabouço de recursos para manipulação de conhecimentos.
5. Referências Bibliográficas
Laird, John E. (2012). The Soar 9 Tutorial. Universidade de Michigan, Michigan. Disponível em: <http://web.eecs.umich.edu/~soar/downloads/Documentation/SoarTutorial/Soar%20Tutorial%20Part%201.pdf>. Acesso em: 16 abril 2013.
Laird, John E. e Congdon, Clare B. (2012). The Soar User's Manual Version 9.3.2. Universidade de Michigan, Michigan. Disponível em: <http://web.eecs.umich.edu/~soar/downloads/Documentation/SoarManual.pdf>. Acesso em: 16 abril 2013.
Theme by Danetsoft and Danang Probo Sayekti inspired by Maksimer