
- Aula 01
- Aula 02: SOAR: Tutorial 1
- Aula 03: SOAR Tutorial 2
- Aula 04: SOAR Tutorial 3
- Aula 05: SOAR Tutorial 4-5
- Aula 06: SOAR Tutorial 7-8-9
- Aula 07 - SOAR: Controlando o WorldServer3D
- Aula 08: Clarion 1
- Aula 09: Clarion 2
- Aula 10 - Clarion 3: Controlando o WorldServer3D
- Aula 11 - Clarion 3: Controlando o WorldServer3D (2 criaturas)
- Aula 12 - LIDA 1: Entendendo a Arquitetura
- Aula 13 - LIDA 2: Exemplos de Implementação Prática
- Aula 14 - 15: Projeto
You are here
SOAR Tutorial 7
Part VII: Reinforcement Learning
Reinforcement Learning (RL) no SOAR permite agentes alterar o seu comportamento durante el tempo, mudando dinamicamente valores numéricos de preferência. Este mecanismo de aprendizado é uma forma incremental de aprendizado que altera probabilisticamente o comportamento do agente.
1. Reinforcement Learning in Action
Antes que ver como é que o mecanismo funciona vai-se apresentar um exemplo chamado de agente Left-Right. O agente Left-Right é um agente simples que pode escolher entre se mover para a direita ou para a esquerda, sem embargo uma das direções será preferencial. Apos o agente decidir para que lado se vai movimentar ele vai receber recompensa. Usando RL o agente vai aprender rapidamente que se mover para a direita é preferível do que mover para a esquerda.
1.1 The Left-Right Agent
Este agente vai ter um operador de movimento o qual vai selecionar entre se mover para a direita ou para a esquerda. O agente terá preferências indiferentes entre as duas ações.
Inicialização:
O agente salva direções e a recompensa associada ao estado.
sp {propose*initialize-left-right
(state <s> ^superstate nil
-^name)
-->
(<s> ^operator <o> +)
(<o> ^name initialize-left-right)
}
sp {apply*initialize-left-right
(state <s> ^operator <op>)
(<op> ^name initialize-left-right)
-->
(<s> ^name left-right
^direction <d1> <d2>
^location start)
(<d1> ^name left ^reward -1)
(<d2> ^name right ^reward 1)}
Operador de movimento:
O agente pode-se mover em qualquer das duas direções. A direção escolhida é armazenada no estado.
sp { left-right*propose*move
(state <s> ^name left-right
^direction.name <dir>
^location start)
-->
(<s> ^operator <op> +)
(<op> ^name move
^dir <dir>)}
sp {left-right*rl*left
(state <s> ^name left-right
^operator <op> +)
(<op> ^name move
^dir left)
-->
(<s> ^operator <op> = 0)}
sp {left-right*rl*right
(state <s> ^name left-right
^operator <op> +)
(<op> ^name move
^dir right)
-->
(<s> ^operator <op> = 0)}
Recompensa:
Quando o agente escolhe uma direção, é proporcionada a respectiva recompensa.
sp {elaborate*reward
(state <s> ^name left-right
^reward-link <r>
^location <d-name>
^direction <dir>)
(<dir> ^name <d-name> ^reward <d-reward>)
-->
(<r> ^reward.value <d-reward>)}
Conclusão:
Quando o agente escolhe uma direção a tarefa terminou e o agente se suspende.
sp {elaborate*done
(state <s> ^name left-right
^location {<> start})
-->
(halt)}
1.2 Running the Left-Right Agent
De padrão o RL está desativado, para ativá-lo é necessário colocar as seguintes linhas no inicio do arquivo:
rl --set learning onindifferent-selection --epsilon-greedy
O primeiro comando ativa o RL, o segundo estabelece a política de pesquisa de exploração.
Apos fazer o primeiro Passo no SoarDebuger e executar o comando print --rl a saída é apresentada na seguinte imagem
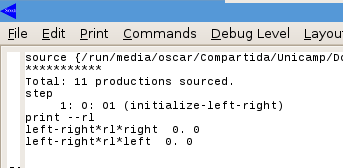
O comando print --rl apresenta a preferência de inferência numérica em cada atualização do RL.
A saída apresenta que as duas instâncias do operador após 0 iterações é 0. Apos mas dois passos a saída do comando print --rl é

Apos aplicar o operador de movimentação o valor numérico de inferência para a regra associada a o movimento para a direita a sido atualizada a 0.3.
Depois é necessário “reiniciar” o Soar fazendo click no botão de “Init-Soar”, esto reiniciará o agente. O método como o RL aprende, é lembrando os valores de inferência entre cada execução, assim mostrando de nodo os valores de inferência eles não vão mudar desde a última execução.
2. Building a Learning Agent
Para fazer que um agente tenha as vantagens do RL geralmente são precisos três passos: 1) uso das regras RL, 2) implementar uma ou mais regras de recompensa e 3) habilitar o mecanismo de aprendizado reforçado (RL).
2.1 RL Rules
As regras que podem ser atualizadas pelo mecanismo de RL devem ter uma estrutura padrão como é apresentado a seguir:
sp {my*proposal*rule
(state <s> ^operator <op> +
^condition <c>)
-->
(<s> ^operator <op> = 2.3)}
O nome da regra pode ser qualquer, e as condições no lado esquerdo (LHS ou Left-Hand Side) podem ter qualquer forma. Sem embargo o lado direito (RHS ou Right-Hand Side) deve ter a seguinte forma:
(<s> ^operator <op> = number)
Mais exatamente o lado direito só pode ter uma ação, e number deve ser um valor numérico constante, como 2.3 no exemplo. Qualquer outra ação deve ser colocada em uma regra separada.
Voltando ao problema do Water Jug o objetivo é que o agente aprenda a melhor forma de utilizar as ações de empty, fill, pour. Assim devem-se modificar os operadores dessas regras para habilitar a utilização do RL.
O processo de modificar as regras será dividido em dois, (1) modificar as regras de proposição existentes e (2) criar novas regras de RL.
A primeira parte é fácil, é só eliminar o símbolo de “=” na proposição da regra. Assim as três propostas ficam:
sp {water-jug*propose*empty
(state <s> ^name water-jug
^jug <j>)
(<j> ^contents > 0)
-->
(<s> ^operator <o> +)
(<o> ^name empty
^empty-jug <j>)}
sp {water-jug*propose*fill
(state <s> ^name water-jug
^jug <j>)
(<j> ^empty > 0)
-->
(<s> ^operator <o> +)
(<o> ^name fill
^fill-jug <j>)}
sp {water-jug*propose*pour
(state <s> ^name water-jug
^jug <i> { <> <i> <j> })
(<i> ^contents > 0 )
(<j> ^empty > 0)
-->
(<s> ^operator <o> +)
(<o> ^name pour
^empty-jug <i>
^fill-jug <j>)}
Agora serão escritas as novas regras que detetarão as preferências aceitáveis e calcularão suas preferências numéricas.
Para o caso do Water Jug são requeridas (3*2*4*6) = 144 RL regras para representar completamente o problema, para gerar todas as posivel posibilidades é utilizado o comando de gp para gerar todas as regras que são necessarias.
gp {rl*water-jug*empty
(state <s> ^name water-jug
^operator <op> +
^jug <j1> <j2>)
(<op> ^name empty
^empty-jug.volume [3 5])
(<j1> ^volume 3
^contents [0 1 2 3])
(<j2> ^volume 5
^contents [0 1 2 3 4 5])
-->
(<s> ^operator <op> = 0)
}
gp {rl*water-jug*fill
(state <s> ^name water-jug
^operator <op> +
^jug <j1> <j2>)
(<op> ^name fill
^fill-jug.volume [3 5])
(<j1> ^volume 3
^contents [0 1 2 3])
(<j2> ^volume 5
^contents [0 1 2 3 4 5])
-->
(<s> ^operator <op> = 0)
}
gp {rl*water-jug*pour
(state <s> ^name water-jug
^operator <op> +
^jug <j1> <j2>)
(<op> ^name pour
^empty-jug.volume [3 5])
(<j1> ^volume 3
^contents [0 1 2 3])
(<j2> ^volume 5
^contents [0 1 2 3 4 5])
-->
(<s> ^operator <op> = 0)
}
2.2 Reward Rules
A regra de recompensa é igual a qualquer outra regra no SOAR, só que ela modifica a estrutura de reward-link do estado para refletir a recompensa associada ao operador atual do agente. Os valores de recompensa devem ser armazenados no elemento value do atributo reward do identificador reward-link ou seja, em (estate.reward-link.reward.value).
No casso do agente Water-Jug, será dada a recompensa somente quando o agente atinga o estado desejado. Assim deve-se modificar a regra de detecção de estado desejado.
sp {water-jug*detect*goal*achieved
(state <s> ^name water-jug
^jug <j>
^reward-link <rl>)
(<j> ^volume 3 ^contents 1)
-->
(write (crlf) |The problem has been solved.|)
(<rl> ^reward.value 10)
(halt)}
O programa encontro o algoritmo ótimo em quatro iterações.
A saída do Soar é:

Os valores de preferência de inferência numérica RL são:

3. Further Exploration
As explicações adicionais tem que ver com a chamada política de exploração. Se é executado o comando de “indifferent-selection --stats” a saída será:

Neste casso apresenta uma política de exploração chamada epsilon-greedy. SOAR tem implementado cinco políticas de exploração: boltzmann, epsilon-greedy , softmax, first e last. Pode-se modificar a política usando o seguinte comando.
indifferent-selection --policy_name
Onde policy_name é o nome da política.
A política mais adequada para o RL é a de epsilon-greedy.
Theme by Danetsoft and Danang Probo Sayekti inspired by Maksimer