
- Aula 01
- Aula 02: SOAR: Tutorial 1
- Aula 03: SOAR Tutorial 2
- Aula 04: SOAR Tutorial 3
- Aula 05: SOAR Tutorial 4-5
- Aula 06: SOAR Tutorial 7-8-9
- Aula 07 - SOAR: Controlando o WorldServer3D
- Aula 08: Clarion 1
- Aula 09: Clarion 2
- Aula 10 - Clarion 3: Controlando o WorldServer3D
- Aula 11 - Clarion 3: Controlando o WorldServer3D (2 criaturas)
- Aula 12 - LIDA 1: Entendendo a Arquitetura
- Aula 13 - LIDA 2: Exemplos de Implementação Prática
- Aula 14 - 15: Projeto
You are here
Aula 14 - 15: Projeto
Projeto Final
Apresentação do problema
O problema do robô que cuida a casa e apresentado a seguir.
A ideia é que um robô realiza as seguintes tarefas:
- Limpa a sujeira
- Apaga fogo
- Identifica ladrões
- Identifica familiares
- Se movimenta pela casa
O ambiente de simulação é apresentado na seguinte figura

Figura 1 :Ambiente com seus elementos
O robô (chamado Andy) tem sensores que detetam a sujeira, o fogo, o ladrão, a família e as paredes nas 8 células ao redor dele.
O objetivo é que Andy realize as seguintes tarefas:
- Se não tem nada em nenhuma célula adjacente movimente-se em qualquer direção
- Se tem sujeira em alguma célula adjacente então limpá-la
- Se tem fogo em alguma célula adjacente então jogar água nela.
- Se tem uma parede em alguma célula adjacente não pode-se movimentar a essa célula.
- Se foi detetado um ladrão em alguma célula adjacente ativar a alarme.
- Se foi detetado um familiar então se movimente em direção contraria e se a alarme está ligada, então desligá-la.
Foram propostas duas abordagens para explorar a arquitetura Clarion: a primeira é a utilização de regras fixas e a segunda é a utilização de aprendizagem por reforço.
Abordagem usando regras fixas
Na abordagem por regras fixas foram propostas regras tipo SE (condição) ENTÃO (ação). Mas, antes de entrar nos detalhes de implementação do agente, será detalhado melhor o entorno onde o Andy faz seu trabalho.
O Ambiente:
Foi programado um ambiente (ou mundo) que consiste numa grade de 15x15 células. Cada célula pode estar vazia ou conter somente um destes elementos: Andy, sujeira, fogo, parede, um ladrão ou um familiar.
Além de isso o entorno conta com uma janela e uma porta. O familiar entra pela porta e o ladrão entra pela janela.
As paredes no mundo são fixas.
O fogo e a sujeira aparecem em posições aleatórias em intervalos de tempos fixos.
Cada certo tempo é introduzido no mundo uma persona (ladrão ou família), mas só um de cada vez, a escolha de que tipo de pessoa é aleatória. Uma vez dentro, a persona fica caminhando um numero fixo de iterações e depois desaparece.
O Agente:
Nesta abordagem será utilizado o módulo ACS (Action Centered Subsystem). Mais especificamente serão usadas regras fixas (Fixed Rules) para que o agente consiga realizar os objetivos planteados na presentação do problema.
A primeira coisa que deve ser feita quando se quer implementar um agente em Clarion é definir os pares Dimensão-valor. Cada Dimensão-valor representa um possível estado das variáveis do mundo.
A seguinte figura apresenta o agente e como ele percebe o mundo. Andy só tem a informação sensorial da posição que ele ocupa e das oito células ao redor dele. Como cada célula tem possibilidade de conter 6 elementos (vazio, fogo, sujeira, parede, ladrão e familiar) te-se 48 possibilidades (6*8).

Figura 2: Agente com sua informação sensorial
Foi feita uma matriz de seis filhas e oito colunas, as colunas representam cada célula e as linhas cada elemento, assim 1 ena linha 2 e na coluna 1 significa que tem esse elemento nessa célula. Os elementos estão numerados como segui:
- Vazio
- Sujeira
- Fogo
- Parede
- Janela
- Porta
- Família
- Ladrão
- Robô
Assim, por exemplo, a Figura 2 geraria um vetor sensor do tipo vetor_sensor = [0,2,0,0,0,0,0,0] que corresponde a a ter '1' na matriz de dimensão-valor, como é apresentada na seguinte figura:
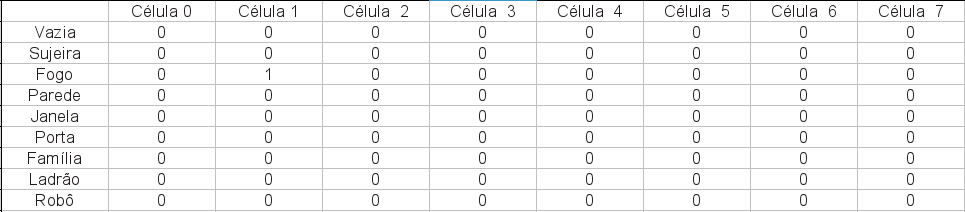
No arquivo do agente foi declarado um enumerador com os possíveis elementos no mundo:
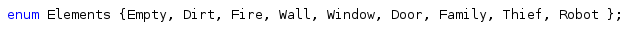
E a matriz de pares dimensão-valor é declarada e inicializada como segui:
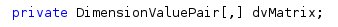

O segundo passo é declarar os ExternalActionChunk, que são as ações que poderá realizar o robô. Neste casso ó robô poderá realizar as seguintes ações:
- Move-se (moveTo)
- Apagar Fogo (pourWater)
- Limpar sujeira (clean)
- Se detecta um ladrão ative a alarme (turnOnAlarm)
- Se detecta um familiar se afastar dele (goAway)
- Se a alarme esta ligada e detecta um familiar então desliga a alarme. (goAway)
Os ExternalActionChunk são declarados com o seguinte código:

Depois foi realizada a configuração do ACS. Primeiro são criados os SupportCalculator para cada uma das regras. Cada SupportCalculator está associado a um delegado, que é que contem a regra. Depois é objeto do tipo FixedRule utilizando o método InitializeActionRule da classe AgentInitializer. A seguinte imagem apresenta como é criada a regra e como é adicionada ao agente.

O processo é repetido para as outras quatro regras. Finalmente é feito o “tunning” dos parâmetros do ACS:
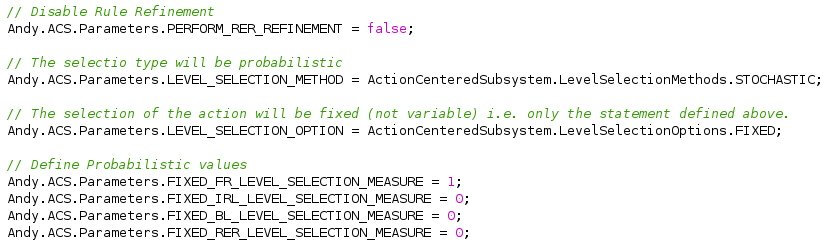
As regras utilizadas serão apresentadas junto com sua implementação em C#:
- Se não tem fogo, sujeira, família, ladrão ou parede, então se movimente
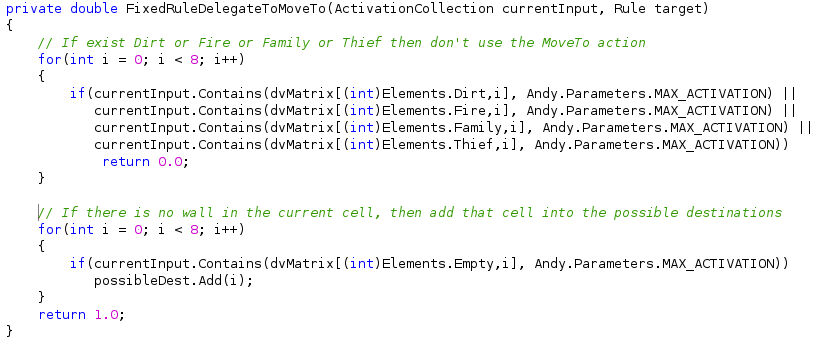
2. Se tem fogo em alguma célula, então apagar o fogo.

3. Se não tem célula com fogo, ladrão ou familiar e ela está com sujeira, então limpa-la
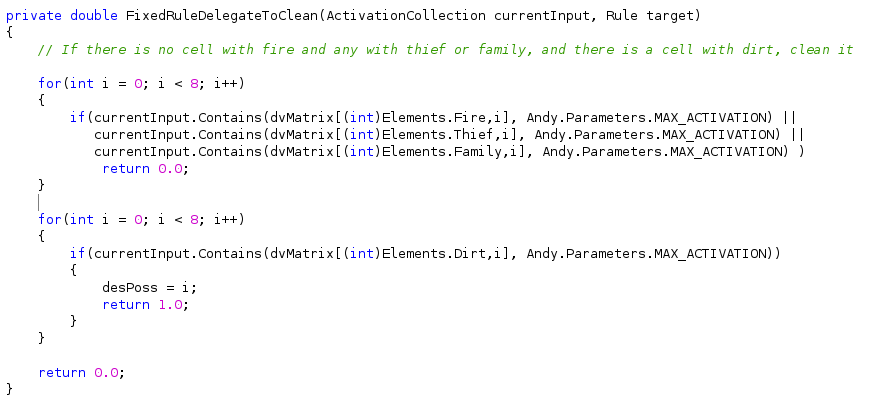
4. Se não tem fogo e tem família, então se-afaste
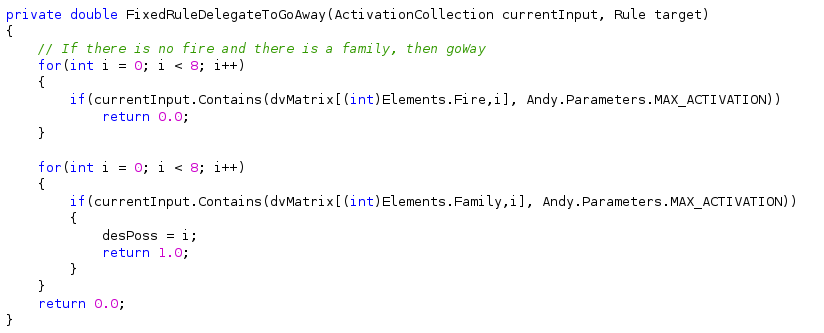
5. Se não tem fogo e tem ladrão, então ligue a alarme
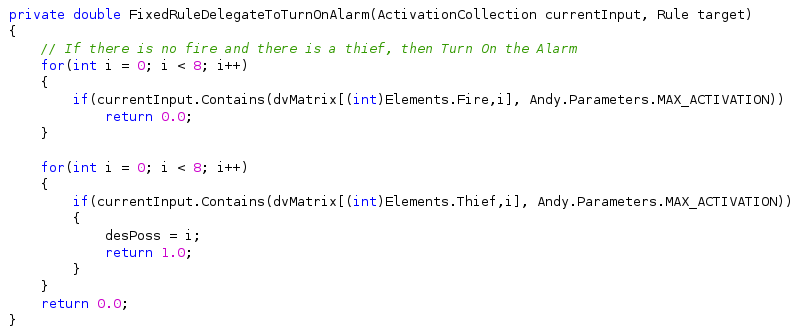
O agente tem um método publico chamado NewCognitiveCicle que recebe como parâmetro um vetor com a informação dos sensores que chega em forma de vetor de 8 posições com o conteúdo de cada célula. Como é apresentada na seguinte figura.
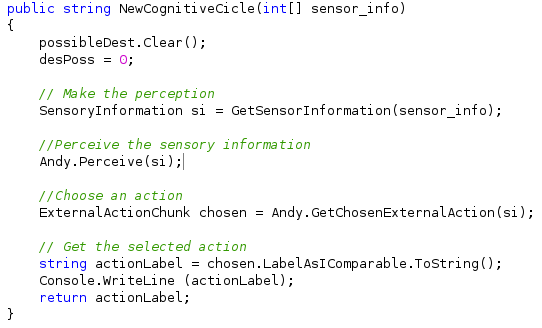
O primeiro a se fazer é traduzir a informação do vetor da forma sensor_info = [0,2,0,0,0,0,0,0] para os correspondentes valores dos pares dimensão-valor. Para isso é utilizada a função GetSensorInformation, ela utiliza um switch() para determinar que células dentro da matriz de dimensão-valor são 1 e quais são 0. Depois Andy percebe a informação do mundo e escolhe uma ação de acordo com as regras acima apresentadas. Finalmente é retornado para o entorno a decisão do agente.
A sexta regra é realizada por código no ambiente: Se a alarme esta ligada e o agente retorno “goAway” então desliga a alarme, porque significa que encontro um familiar.
Os resultados apresentados com esta abordagem foram muito bons. O agente realiza todas as ações pedidas e tem um bom desempeno na tarefa de cuidar da cassa. A seguir são apresentadas as imagens do programa final.
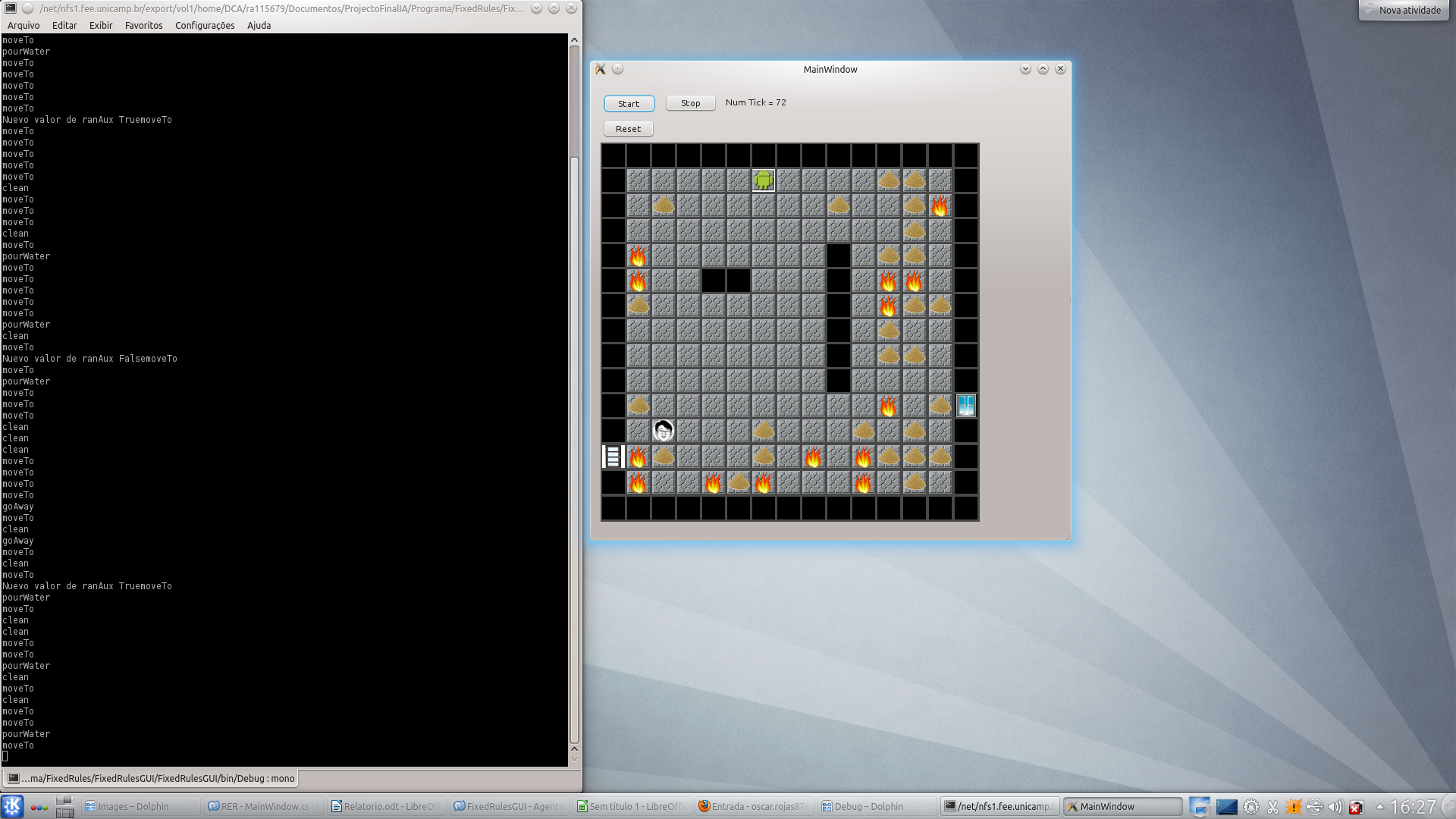
Na seguinte imagem é apresentada a situação onde é detetado um ladrão e é ativada a alarme. A alarme continuará ligada até Andy detetar um familiar.
Abordagem usando aprendizagem por reforço.
Tentou-se resolver o mesmo problema apresentado acima utilizando aprendizagem por reforço mas se notou rapidamente que o numero de possibilidades de estados é muito alto. O agente teria que saber como atuar corretamente em cada um dos possíveis cenários: uma célula com fogo, duas células com fogo, uma com sujeira e uma com fogo, uma com ladão e outra com fogo, etc. Assim o treinamento da rede ia ficar muito pesado e muito demorado. É por isso que o problema foi simplificado em número de componentes e comportamento do agente. Foram eliminadas da simulação o ladrão e o familiar, por tanto foram eliminados a porta, a janela e a alarme. Assim o problema foi simplificado a:
- Se todas as células ao redor estão vazias, então movimente-se em forma aleatória
- Se alguma célula tem fogo, apagar o fogo.
- Se alguma célula tem sujeira, limpar
- Se tem parede em alguma célula, se movimentar em direção contraria à parede.
Foi desenvolvido um programa que permite o treinamento do agente e outro que utiliza o resultados do treinamento (a rede já treinada).
Para realizar esta tarefa utilizando a aprendizagem por reforço foram feitas algumas modificações no programa. A matriz de pares dimensão-valor ficou mais pequena (4x8) e foram definidos 3 vetores do tipo ExternalActionChunk com as três ações, cada posição do vetor significa a posição da célula que deve ser realizada a ação. Na verdade pode-se ver como se fosse uma matriz de células nas linhas e ações nas colunas. Assim são definidos 24 ExternalActionChunk, oito por cada ação.
O seguinte código inicializa os pares dimensão-valor e os ExternalActionChunk:

Treinamento
A seguinte figura apresenta o ambiente de treinamento.
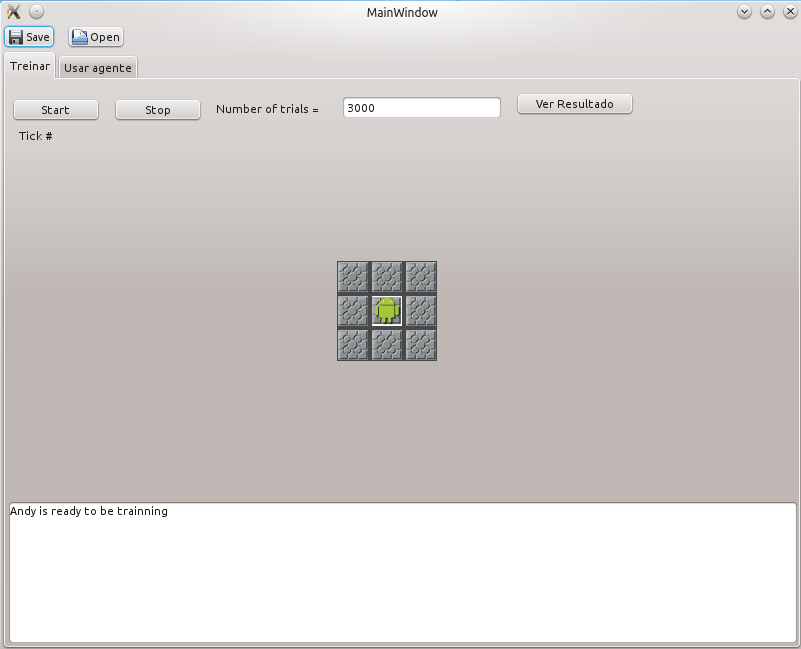
O treinamento é realizado da seguinte forma: é apresentado de forma aleatória um elemento numa célula adjacente a Andy e o agente toma a decisão de que fazer com essa entrada, se a decisão é correta de acordo com os critérios apresentados acima, então Andy recebe um “feedback” positivo, senão, então ele recebe um “feedback” negativo. As possíveis entradas aleatórias são:
- Nada (no caso Andy pode-se movimentar para qualquer célula)
- Fogo (no caso Andy deveria apagar o fogo na célula onde o fogo está)
- Sujeira (no caso Andy deveria limpar a célula onde a sujeira está)
- Parede (no caso Andy deveria se movimentar em direção contraria à célula onde a parede está)
O processo de treinamento é realizado 20 vesses com o número de iterações que o usuário escolha. Por cada set de treinamentos é apresentada a porcentagem de acertos do agente, assim pode-se verificar a aprendizagem dele.
A seguinte figura apresenta o processo de treinamento após 20 sets de 200 iterações cada, com uma porcentagem de acerto de 45% ao finalizar o treinamento.
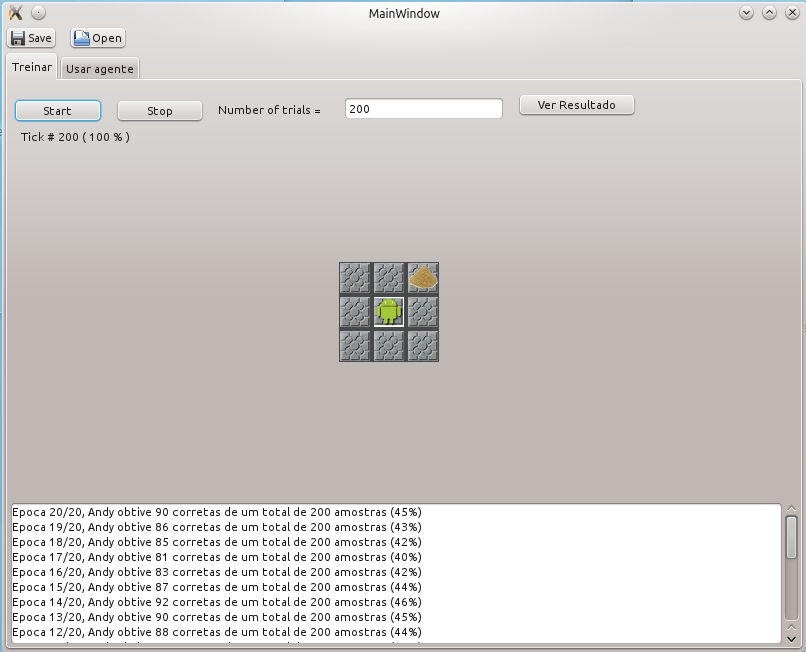
Apos o treinamento é possível ver o resultado do aprendizagem buttom-up, onde a rede sintetiza uma serie de regras do tipo SE (condição) ENTÃO (ação).
Para ver as regras sintetizadas pelo nível superior do ACS após finalizado o treinamento se pode selecionar o botão “Ver Resultado”.
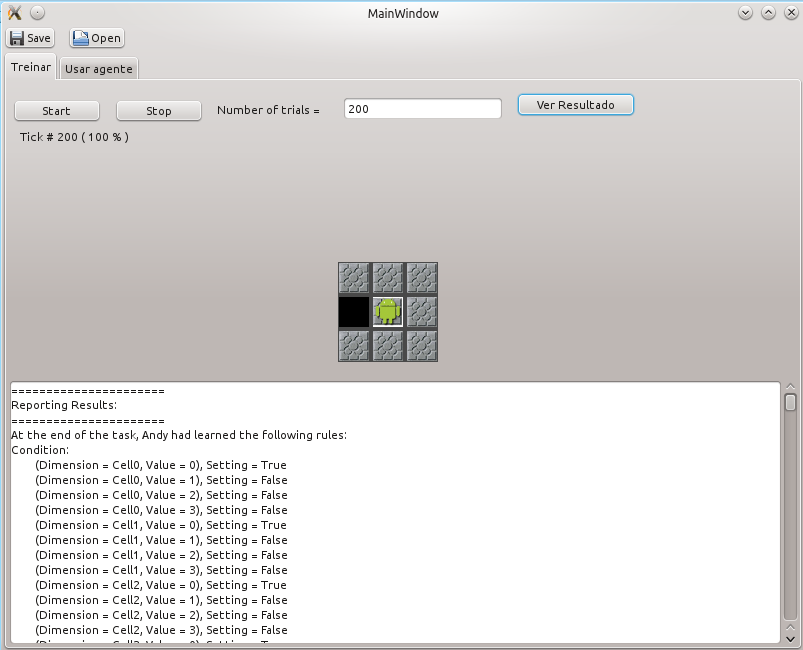
A seguinte é a primeira das regras sintetizadas no nível superior do ACS.
Condition:
(Dimension = Cell0, Value= 0), Setting = True
(Dimension = Cell0, Value = 1), Setting = False
(Dimension = Cell0, Value = 2), Setting = False
(Dimension = Cell0, Value = 3), Setting = False
(Dimension = Cell1, Value = 0), Setting = True
(Dimension = Cell1, Value = 1), Setting = False
(Dimension = Cell1, Value = 2), Setting = False
(Dimension = Cell1, Value = 3), Setting = False
(Dimension = Cell2, Value = 0), Setting = True
(Dimension = Cell2, Value = 1), Setting = False
(Dimension = Cell2, Value = 2), Setting = False
(Dimension = Cell2, Value = 3), Setting = False
(Dimension = Cell3, Value = 0), Setting = True
(Dimension = Cell3, Value = 1), Setting = False
(Dimension = Cell3, Value = 2), Setting = False
(Dimension = Cell3, Value = 3), Setting = False
(Dimension = Cell4, Value = 0), Setting = True
(Dimension = Cell4, Value = 1), Setting = False
(Dimension = Cell4, Value = 2), Setting = False
(Dimension = Cell4, Value = 3), Setting = False
(Dimension = Cell5, Value = 0), Setting = True
(Dimension = Cell5, Value = 1), Setting = False
(Dimension = Cell5, Value = 2), Setting = False
(Dimension = Cell5, Value = 3), Setting = False
(Dimension = Cell6, Value = 0), Setting = True
(Dimension = Cell6, Value = 1), Setting = False
(Dimension = Cell6, Value = 2), Setting = False
(Dimension = Cell6, Value = 3), Setting = False
(Dimension = Cell7, Value = 0), Setting = True
(Dimension = Cell7, Value = 1), Setting = False
(Dimension = Cell7, Value = 2), Setting = False
(Dimension = Cell7, Value = 3), Setting = False
Action:
ExternalActionChunk moveTo_6:
DimensionValuePairs:
(Dimension = SemanticLabel, Value = moveTo_6)
Foi verificado por experiencia que se requer um número alto de ciclos de treinamentos. Em testes realizados o máximo de porcentagem de acerto em 15.000 mostras foi de 89% com um treinamento de 300.000 iterações. É dizer foram 20 sets de 15.000 iterações cada um. O resultado é apresentado na seguinte imagem:
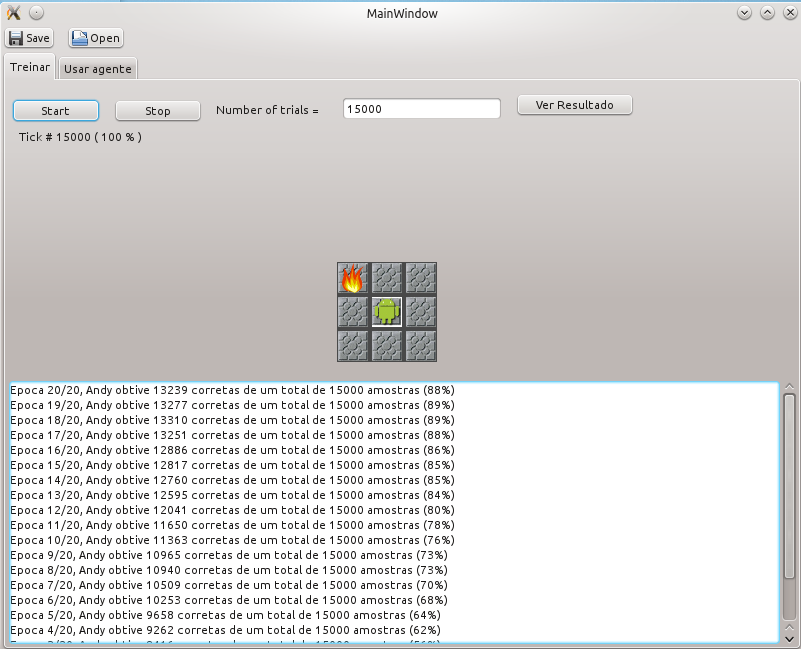
De novo pode-se verificar as regras sintetizadas no nível superior do ACS selecionando o botão “Ver Resultados”
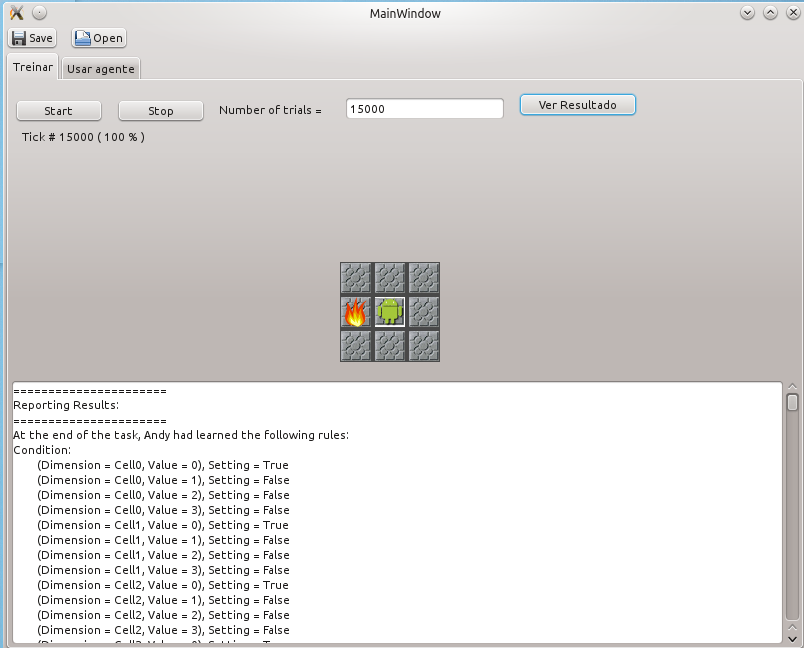
Apos o treinamento pode-se selecionar a aba “usar agente” para verificar o comportamento do agente no ambiente “real”. A seguinte imagem apresenta o entorno do simulação do agente treinado.
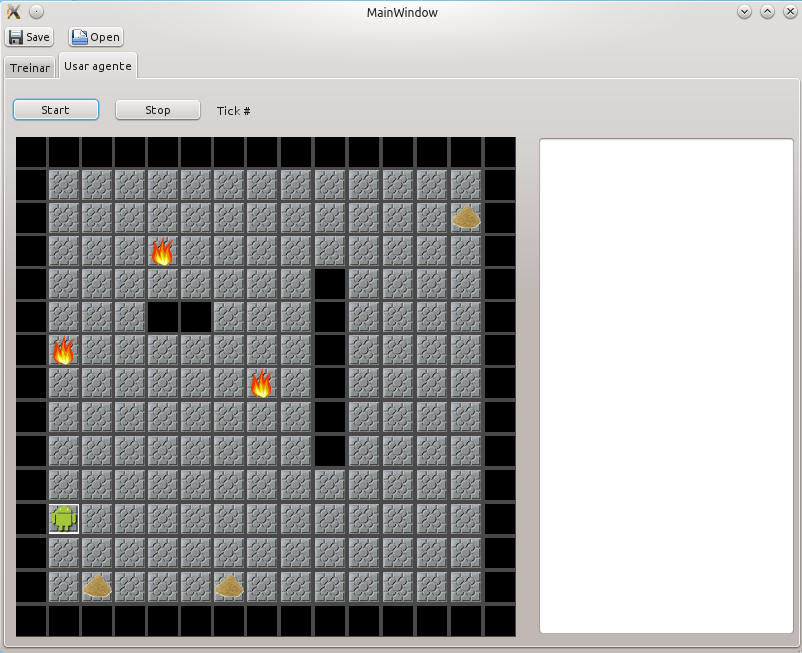
Na segunda coluna em branco aparece a entrada e as decisões de Andy, e se elas foram certas ou não.
Um fenômeno a se-destacar é que as regras geradas no nível superior são muito restritas. Por exemplo se Andy não faz a escolha certa da ação o ambiente não vai executar a ação que Andy escolheu. Se o ambiente não muda, então as entradas de Andy também não mudam e a decisão dele vai ser a mesma escolha e de novo o ambiente não vai realizar a ação de Andy, o ambiente não muda e o agente fica preso nesse estado o não muda mais.
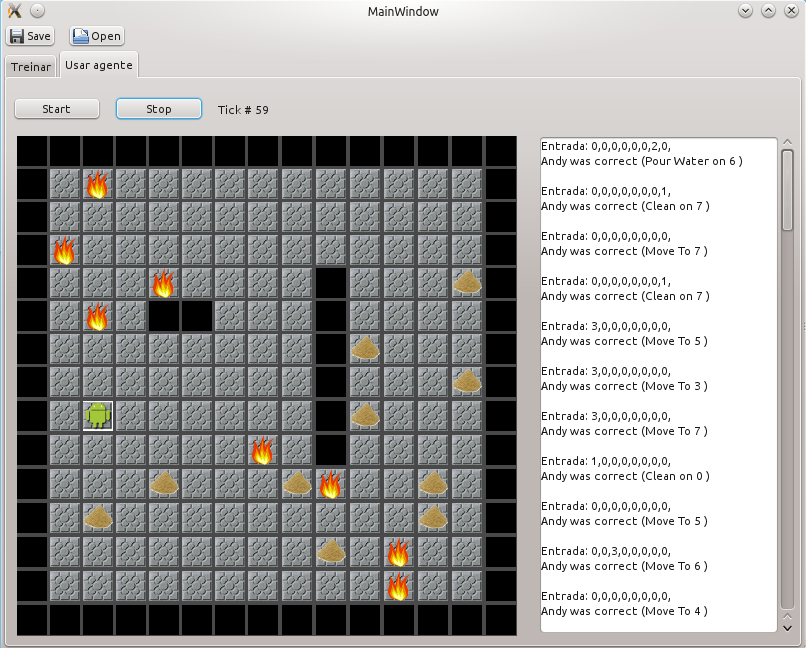
Os resultados com esta abordagem foram bons, mas se apresenta a dificuldade de se precisar treinar por muito tempo ao agente. Somente com porcentagem do 85% para acima o agente ter um bom desempenho no ambiente real. Além de isso, teve se que simplificar um pouco as condições do problema para ser resolvível num tempo razoável.
Arquivos
Para executar os programas:
Descomprimir o arquivo Binaries.zip
Entrar na pasta “bin”
Entrar em “Fixed Rules” para a primeira proposta, ou em “Learning” para a segunda proposta
Executar na terminal “mono FixedRulesGUI.exe” para “Fixed Rules” ou executar “mono RER.exe” para “Learning”
Observações: Para o programa de RER.exe é preciso um numero alto de iterações (10.000 ou mais)
Theme by Danetsoft and Danang Probo Sayekti inspired by Maksimer