Tutorial 7 - Aprendizagem por reforço
A aprendizagem por reforço no Soar permite aos agentes alterar seu comportamento dinamicamente, alterando preferencias numéricas de indiferença na memória procedural em resposta a sinais de recompensa.
Para um exemplo inicial, é criado um agente que pode escolher se mover para esquerda ou direita. Após a decisão, o agente recebe uma recompensa dizendo quão boa foi a decisão tomada, neste caso -1 para esquerda e +1 para a direita. Usando a aprendizagem por reforço o agente perceberá rapidamente que se mover para esquerda é preferível que para a direita.
O código utilizado para a criação deste agente é o seguinte:
Inicialização:
sp {propose*initialize-left-right
(state <s> ^superstate nil
-^name)
-->
(<s> ^operator <o> +)
(<o> ^name initialize-left-right)
}
sp {apply*initialize-left-right
(state <s> ^operator <op>)
(<op> ^name initialize-left-right)
-->
(<s> ^name left-right
^direction <d1> <d2>
^location start)
# Aqui são criados os atributos de recompensa para cada lado escolhido
(<d1> ^name left ^reward -1)
(<d2> ^name right ^reward 1)
}
Proposição e aplicação dos operador move:
sp {left-right*propose*move
(state <s> ^name left-right
^direction.name <dir>
^location start)
-->
(<s> ^operator <op> +)
(<op> ^name move
^dir <dir>)
}
sp {left-right*rl*left
(state <s> ^name left-right
^operator <op> +)
(<op> ^name move
^dir left)
-->
(<s> ^operator <op> = 0)
}
sp {left-right*rl*right
(state <s> ^name left-right
^operator <op> +)
(<op> ^name move
^dir right)
-->
(<s> ^operator <op> = 0)
}
sp {apply*move
(state <s> ^operator <op>
^location start)
(<op> ^name move
^dir <dir>)
-->
(<s> ^location start - <dir>)
(write (crlf) |Moved: | <dir>)
}
Regra de recompensa:
sp {elaborate*reward
(state <s> ^name left-right
^reward-link <r>
^location <d-name>
^direction <dir>)
(<dir> ^name <d-name> ^reward <d-reward>)
-->
# Atribuição de recompensa
(<r> ^reward.value <d-reward>)
}
Regra de conclusão:
sp {elaborate*done
(state <s> ^name left-right
^location {<> start})
-->
(halt)
}
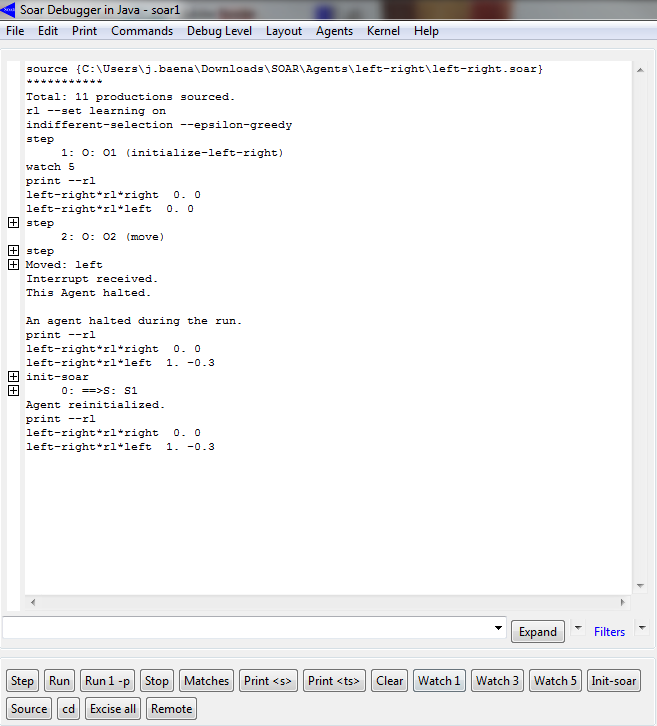
Utilizando essas produções passou-se então a execução no Soar Debugger. Ativou-se o mecanismo de aprendizagem reforçada e configurou-se parâmetros da política de exploração que veremos a seguir.
Após 20 execuções percebemos que os valores de aprendizado reforçado para a direita se aproxima de 1, enquanto para esquerda se mantém em -0.3 para a esquerda, atribuído na única decisão de se mover para esquerda. Com o valor de recompensa favorecendo a mover para a direita, percebe-se que a partir da primeira decisão para a direita, todas as outras serão também.

Regras para a aprendizagem por reforço:
Para uma regra ser atualizada dentro do mecanismo de aprendizagem por reforço ela deve seguir a seguinte sintaxe:
sp {my*proposal*rule
(state <s> ^operator <op> +
^condition <c>)
-->
(<s> ^operator <op> = 2.3)
}
A parte "então" da regra deve seguir (<s> ^operator <op> = 2.3) onde existe a atribuição de um valor numérico junto ao operador de preferência indiferente.
O aprendizado por reforço aplicado ao problema do Water Jug.
O roteiro propõe a alteração das regras empty, fill e pour do agente do Water Jug para poderem utilizar o aprendizado por reforço. As modificações são:
- Modificar as regras de proposição de operadores existentes removendo o (=) da operador de preferência.
- Criar novas regras de aprendizado por reforço.
sp {water-jug*propose*empty
(state <s> ^name water-jug
^jug <j>)
(<j> ^contents > 0)
-->
(<s> ^operator <o> +)
(<o> ^name empty
^empty-jug <j>)}
sp {water-jug*propose*fill
(state <s> ^name water-jug
^jug <j>)
(<j> ^empty > 0)
-->
(<s> ^operator <o> +)
(<o> ^name fill
^fill-jug <j>)}
sp {water-jug*propose*pour
(state <s> ^name water-jug
^jug <i> { <><i><j> })
(<i> ^contents > 0 )
(<j> ^empty > 0)
-->
(<s> ^operator <o> +)
(<o> ^name pour
^empty-jug <i>
^fill-jug <j>)}
Essas regras modificadas propõe seus respectivos operadores com uma preferência aceitavel, e as novas regras de aprendizagem por reforço vão detecta-las e complementa-las com preferências numéricas.
Para a segunda parte, cada estado pode ser representado pelo volume em cada uma das jarras em conjunto com a ação a ser realizada com uma delas. Dessa forma seria inviável escrever regras para cada um desses estados. Como podemos expressar essas regras como o resultado de um padrão combinatorial, nos usamos o comando Soar "gp"para gerar todas as regras que desejamos.
Essas são escritas da seguinte forma, combinando todos os estados possíveis de conteúdos em cada jarra com as 3 operações do problema:
gp {rl*water-jug*empty
(state <s> ^name water-jug
^operator <op> +
^jug <j1> <j2>)
(<op> ^name empty
^empty-jug.volume [3 5])
(<j1> ^volume 3
^contents [0 1 2 3])
(<j2> ^volume 5
^contents [0 1 2 3 4 5])
-->
(<s> ^operator <op> = 0)
}
gp {rl*water-jug*fill
(state <s> ^name water-jug
^operator <op> +
^jug <j1> <j2>)
(<op> ^name fill
^fill-jug.volume [3 5])
(<j1> ^volume 3
^contents [0 1 2 3])
(<j2> ^volume 5
^contents [0 1 2 3 4 5])
-->
(<s> ^operator <op> = 0)
}
gp {rl*water-jug*pour
(state <s> ^name water-jug
^operator <op> +
^jug <j1> <j2>)
(<op> ^name pour
^empty-jug.volume [3 5])
(<j1> ^volume 3
^contents [0 1 2 3])
(<j2> ^volume 5
^contents [0 1 2 3 4 5])
-->
(<s> ^operator <op> = 0)
}
As regras de recompensa como já vimos são regras que modificam o link de recompensa da estrutura do estado para atribuir a recompensa associada ao operador de decisão atual. Os valores devem ser guardados no elemento value do atributo reward.
Para o problema do Water Jug vamos prover recompensa apenas quando o agente chegar no objetivo. Isso requer uma modificação na regra de teste de objetivo:
sp {water-jug*detect*goal*achieved
(state <s> ^name water-jug
^jug <j>
^reward-link <rl>)
(<j> ^volume 3 ^contents 1)
-->
(write (crlf) |The problem has been solved.|)
(<rl> ^reward.value 10)
(halt)}
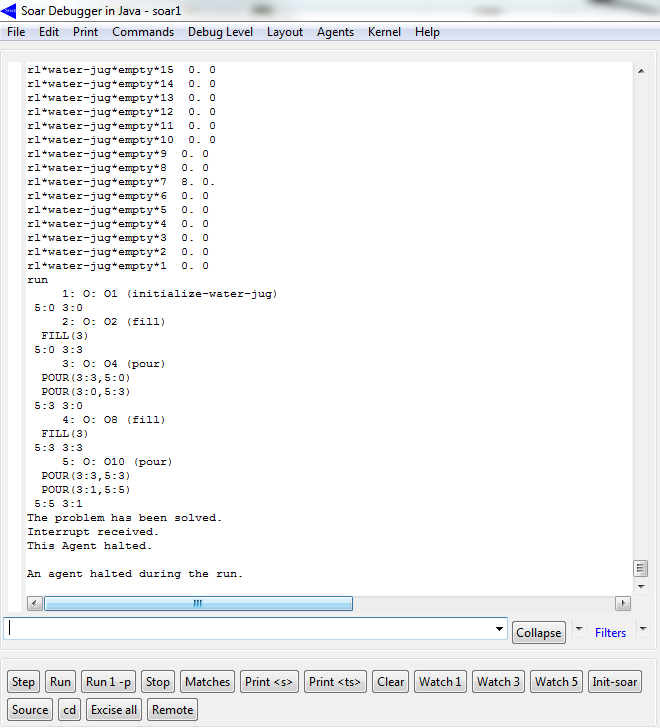
Rodando o programa do Water Jug modificado agora com as regras de aprendizado por reforço observamos os valores para todos os estados zerados.
Após uma primeira execuçao que levou 1703 (!) passos para chegar ao objetivo os valores do aprendizado por reforço são atualizados para alguns estados.
Com a atualização dos valores númericos das preferências o programa passa rapidamente a uma solução mais otimizada do problema:
Tutorial 8 - Memória Semantica