
You are here
Aula 06 - Soar
Reinforcement Learning, Semantic Memory e Episodic Memory no SOAR
Soar is a general cognitive architecture for developing systems that exhibit intelligent behavior.
Apresentação
Na Aula 5 vimos um pouco sobre o aprendizado via chunking, trata-se de um mecanismo projetado para resolver impasses (considera-se que a ocorrência de um impasse é um indicativo de que o Soar não possui conhecimento, da forma como está posto, suficiente para resolver o problema). O Soar possui outros mecanismos que podem aprimorar essa forma de aprendizado, por exemplo, por reforço (baseado em recompensa: no Soar isso pode ser feito incorporando ajustes de valores (numéricos) sobre as preferências).
Nesta atividade apresentamos três mecanismos do Soar associados ao processo de aprendizado: de reforço (reinforcement learning), de memória semântica (semantic memory - SMem) e de memória episódica (episodic memory - EpMem). O mecanismo de reforçoa cuida da atribuição de reforço (positivo ou negativo) às ações resultantes de um operador. Esse reforço, nos próximos ciclos de decisão, serve para que este operador tenha preferência maior ou menor de execução quando comparado a outros operadores. É um sistema que regula preferências de operadores de acordo com um determinado reforço. Outros dois mecanismos ligados ao processo de aprendizado são os que tratam da memória semântica e episódica. São módulos independentes cuja finalidade é armazenar um WME ou um conjunto de WMEs da memória de trabalho para a memória semântica (semantic memory - SMem) ou episódica (episodic memory - EpMem).
A memória episódica armazena conjuntos de episódios, cada episódio é como uma foto da WM: corresponde à situação exata da memória de trabalho num dado instante contendo todos os respectivos WME's. A idéia dessa forma de armazenamento é a de guardar o contexto da ocorrência de uma dado espisódio. O armazenamento é feito automaticamente sem requerer nenhuma ação deliberada pelo agente. Por outro lado, a memória semântica está associada à indepedência de contexto, armazena formas de conhecimento mais gerais. Outro aspecto relevante associado a esses dois mecanismos é a forma como se processa a recuperação do conhecimento. A estratégia nos dois casos é baseada em descrições parciais (pistas - cues). Na memória semântica a busca baseda em descrições parciais é feita de maneira exata: todos os dados da cue devem corresponder exatamente aos dados retornados pela busca. No caso da memória episódica, a busca é feita baseada num cálculo sobre a proximidade da descrições parciais (na vizinhança da cue), são duas etapas: a primeira calcula quais episódios têm pelo menos uma WME em comum com a cue. A segunda, para os episódios previamente selecionados, ocorre a ativação do episódio de acordo com a cardinalidade do episódio (número de WMEs que satisfazem o episódio e a cue). Isto é, são recuperados os episódios que obtiverem as melhores notas.
Reinforcement Learning no SOAR
Nesta seção exploramos o conceito de Reinforcement Learning (o link leva para o livro do Sutton e Barto) no Soar, referente ao conteúdo do Tutorial 7, do Capitulo 5 do Manual do Soar (há também um resumo dos comando associados ao Reinforcement Learning (RL) em: rl command documentation (vide página 169, Seção 8.4, do Manual do Soar).
Agentes Soar munidos do mecanismo de aprendizado por reforço, em tese, são capazes de aprender "qual a melhor ação a ser executada" em diferentes situações. As escolhas das ações são sustentadas por um mecanismo que determina "qual o melhor operador a ser executado" em diferentes situações; para isso o Soar possui operadores específicos denominados operadores RL. São operadores como os demais (inclusive sujeitos a impasses), exceto por uma característica: possuem uma preferência de indiferença numérica. Por exemplo:
sp {rl*3*12*left
(state <s> ^name task-name ^x 3 ^y 12 ^operator <o> +)
(<o> ^name move ^direction left)
-->
(<s> ^operator <o> = 1.5) # Preferência de indiferença numérica
}
Note-se que a escolha do operador que irá de fato ser executado fica a cargo do mecanismo de decisão (visto nas atividades anteriores), porém é o módulo de aprendizagem por reforço que determina quais as preferências dos operadores RL. O reforço associado a cada operador fica armazenado em um estrutura na memória de trabalho (uma WME). O SOAR irá checar essa estrutura em busca de um número que represente o reforço associado ao último operador executado no começo de cada ciclo de decisão. Esse número é utilizado para atualizar as preferências dos operadores RL, assim operadores com um reforço positivo acabam tendo maior preferência. A atualização de preferências pode ser realizada, por exemplo, pelo algoritmo Q-Learning que toma Q-valores para pares operadores-estado, os Q-valores são criados especificamente para a formulação de regras RL (inicialmente esses valores são armazenados como preferências numéricas indiferentes). Vejamos um passo-a-passo de como acontece.
Elementos Básicos do Aprendizado por Reforço: o agente Soar Left-Right
Iniciamos nosso estudo com um exemplo, para isso utilizamos o agente Soar Left-Right, que escolhe qual direção tomar (esquerda ou direita). Não é de conhecimento do agente, mas uma direção tem maior preferência que outra. Após a escolha o agente recebe uma recompensa (um feedback indicando quão boa foia sua decisão: -1 se a escolha foi "à esquerda" e +1 se a escolha foi "à direita"). O agente irá aprender, via aprendizado por reforço, que a escolha preferível é "à direita". Seguimos essa descrição do agente Left-Right para implementar o agente Soar (o código completo está [ aqui ]).
- Inicialização: O agente tem duas escolhas e a recompensa associada a cada escolha.
# --------------------------------------------------------------
sp {propose*initialize-left-right
(state <s> ^superstate nil
-^name)
-->
(<s> ^operator <o> +)
(<o> ^name initialize-left-right)
}
# --------------------------------------------------------------
sp {apply*initialize-left-right
(state <s> ^operator <op>)
(<op> ^name initialize-left-right)
-->
(<s> ^name left-right ^direction <d1> <d2> ^location start)
(<d1> ^name left ^reward -1)
(<d2> ^name right ^reward 1)
}
- Movimentação: Como o agente não sabe que há uma escolha melhor que outra, ele pode escolher qualquer direção. A escolha feita é armazenada no estado.
# ------------------------------------------------------------------------
sp {left-right*propose*move
(state <s> ^name left-right ^direction.name <dir> ^location start)
-->
(<s> ^operator <op> +)
(<op> ^name move ^dir <dir>)
}
# ------------------------------------------------------------------------
sp {left-right*rl*left
(state <s> ^name left-right ^operator <op> +)
(<op> ^name move ^dir left)
-->
(<s> ^operator <op> = 0) # Inicialmente, o agente não sabe que há
} # diferença entre escolhas
# ------------------------------------------------------------------------
sp {left-right*rl*right
(state <s> ^name left-right ^operator <op> +)
(<op> ^name move ^dir right)
-->
(<s> ^operator <op> = 0) # Inicialmente, o agente não sabe que há
} # diferença entre escolhas
# ------------------------------------------------------------------------
sp {apply*move
(state <s> ^operator <op> ^location start)
(<op> ^name move ^dir <dir>)
-->
(<s> ^location start - <dir>)
(write (crlf) |Moved: | <dir>)
}
- Recompensa pela escolha: cada escolha do agente está vinculada à uma recompensa.
# ----------------------------------------------------------------------------------------
sp {elaborate*reward
(state <s> ^name left-right ^reward-link <r> ^location <d-name> ^direction <dir>)
(<dir> ^name <d-name> ^reward <d-reward>)
-->
(<r> ^reward.value <d-reward>)
}
- Finalização: após a escolha da direção a tarefa termina.
# --------------------------------------------------------------
sp {elaborate*done
(state <s> ^name left-right ^location {<> start})
-->
(halt)
}
- Ativando o agente Left-Right: carregamos o código do agente no SJD e ativamos o mecanismo de reinforcement learning (utilizamos os comandos abaixo):
rl --set learning on indifferent-selection --epsilon-greedy
O primeiro comando ativa o mecanismo RL e o segundo estabelece o critério para a política de escolhas (indifferent-selection). Como nas atividades anteriores os comandos acima podem ser adicionados no arquivo _firstload na pasta left-right project.
O epsilon greedy é uma política que evita mínimos locais e pode ser resumida como:
With ( 1 - epsilon ) probability, the most preferred operator is to be chosen. With epsilon probability, a random selection of all indifferent operators is made.
è comum o uso do epsilon greedy em experimentos envolvendo aprendizado por reforço, no Soar, o valor do padrão do epsilon é 0.1, isto é, 90% das vezes a escolha recai sobre o operador de maior preferência numérica. Os outros 10% são disputados por operadores de preferência aceitável. O valor do epsilon pode ser alterado, basta usar o comando abaixo:
indifferent-selection --epsilon <value> # valores entre 0.0 e 1.0
Note que se epsilon = 0.0, então não há chance de escolha. Se epsilon = 1.0, a seleção é uniformemente randômica. Para alterar a política de exploração utilizamos o comando abaixo:
indifferent-selection --policy_name
No lugar de "policy_name" coloque uma das cinco políticas disponíveis: boltzmann, epsilon-greedy, softmax, first, e last. As polítcas associadas ao indifferent-selection geram diferentes comportamentos de aprendizado. Nada impede, por exemplo, que o agente Left-Right tenha o seguinte comportamento:
run Moved: right This Agent halted. An agent halted during the run. init-soar Agent reinitialized. run Moved: right This Agent halted. An agent halted during the run. init-soar Agent reinitialized. run Moved: left This Agent halted. An agent halted during the run.
Após duas escolhas pela direita, na terceira, o agente pode faze a escolha pela esquerda. Para visualizar a política corrente e os parâmetros de ajustes aplicados utilizamos o comando: indifferent-selection --stats. Maiores detalhes na Seção 5.3.3.1 (pág.: 88; 157-159) do Manual do Soar.
Após carregar o programa, ativar o RL e estabelecer o critério para a política de escolhas: acionamos o "Step" para executar o primeiro ciclo (inicialização) e usamos o comando de impressão (print --rl) para visualizar o estado de aprendizado do agente:
left-right*rl*right 0. 0 # Nenhum movimento - preferência indiferente: 0 left-right*rl*left 0. 0 # Nenhum movimento - preferência indiferente: 0
A inicialização coloca as preferência de indiferença na memória procedural. Porém, se acionarmos o "Step" mais duas vezes, teremos a seguinte alteração nas preferências (novamente, print --rl):
left-right*rl*right 1. 0.3 # Um movimento - preferência 0.3 left-right*rl*left 0. 0 # Nenhum movimento - preferência indiferente: 0
Após a aplicação do operador move, o valor da preferência associado à escolha pela direita, depois de um movimento para a direita, é alterado para 0.3. A escolha inicial é randômica, portanto o agente poderia ter escolhido outra direção. Nesse caso, o estado seria:
left-right*rl*right 0. 0 # Nenhum movimento - preferência indiferente: 0 left-right*rl*left 1. -0.3 # Um movimento - preferência -0.3
O armazenamento da aprendizagem permanece no agente, para verificar isso basta acionar o "Init-soar" (esse comando reinicializa o agente) e imprimir o estado do agente (print --rl). A cada execução do agente o aprendizado é reforçado:
Após uma execução: left-right*rl*right 0. 0 # Nenhum movimento - preferência indiferente: 0 left-right*rl*left 1. -0.3 # Um movimento - preferência -0.3 Após mais cinco execuções: left-right*rl*right 5. 0.8319300000000001 left-right*rl*left 1. -0.3 Após mais três execuções: left-right*rl*right 8. 0.94235199 left-right*rl*left 1. -0.3
Reforço de Aprendizado em Agentes Water-Jug
Para avaliar alguns aspectos do mecanismo de aprendizado por reforço, vamos agregar o mecanismo de aprendizado por reforço na estrutura do agente water-jug (simple agent). Faremos essa avaliação em três etapas: (1) uso das regras RL, (2) implementar uma ou mais regras que tratam das recompensas e (3) ativar o mecanismo de reforço de aprendizado.
- Regras RL: regras que são tratadas pelo mecanismo de reforço de aprendizado. O nome da regra e as condições podem ser quaisquer (lado esquerdo do
-->), porém a ação (lado direito do-->) deve ter a forma:<s> ^operator <op> = number(somente uma única ação atribuindo uma constante numérica à preferência de indiferença). Veja exemplo abaixo:
# --------------------------------------------------------------
sp {my*proposal*rule
(state <s> ^operator <op> +
^condition <c>)
-->
(<s> ^operator <op> = 2.3)
}
As modificações do agente water-jug serão feitas nas regras que tratam dos operadores empty, fill e pour (vide regras aqui). Fazemos isso em dois passos: (A) modificando as regras de proposição e (B) criando regras RL. O primeiro passo é relativamente simples, basta remover o sinal de "=" (preferência de aceitação):
# --------------------------------------------------------------
sp {water-jug*propose*empty
(state <s> ^name water-jug ^jug <j>)
(<j> ^contents > 0)
-->
(<s> ^operator <o> +)
(<o> ^name empty ^empty-jug <j>)
}
# --------------------------------------------------------------
sp {water-jug*propose*fill
(state <s> ^name water-jug ^jug <j>)
(<j> ^empty > 0)
-->
(<s> ^operator <o> +)
(<o> ^name fill ^fill-jug <j>) # Compare com a regra original [ aqui ]
}
# --------------------------------------------------------------
sp {water-jug*propose*pour
(state <s> ^name water-jug ^jug <i> { <><i><j> })
(<i> ^contents > 0 )
(<j> ^empty > 0)
-->
(<s> ^operator <o> +)
(<o> ^name pour ^empty-jug <i> ^fill-jug <j>)
}
O passo seguinte não é tão simples, devemos escrever regras RL que fornecem um feedback para cada par estado-ação: um estado pode ser representado pelo volume de cada jarro e a ação por empty, fill, ou pour. Por exemplo, uma regra RL rule para esvaziar o jarro de três litros (dado que o jarro de três contém dois litros e o jarro de cinco contém quatro litros):
# --------------------------------------------------------------
sp {water-jug*empty*3*2*4
(state <s> ^name water-jug ^operator <op> +
^jug <j1> <j2>)
(<op> ^name empty ^empty-jug.volume 3)
(<j1> ^volume 3 ^contents 2)
(<j2> ^volume 5 ^contents 4)
-->
(<s> ^operator <op> = 0)
}
Evidentemente, não é o caso de escrever uma regra para cada par estado-ação (são 3 x 2 x 4 x 6 = 144 regras RL). Um modo econômico é utilizar um recurso do Soar para gerar essas regras (já que podem ser obtidas como simples processo combinatório). Para maiore detalhes veja a seção 5.4.1 - págs: 89; 112-114 - do Manual do Soar. A codificação abaixo mostra como fazer isso para cada uma das ações (empty, fill e pour):
# ------------------------------------------------------------------
gp {rl*water-jug*empty
(state <s> ^name water-jug ^operator <op> + ^jug <j1> <j2>)
(<op> ^name empty ^empty-jug.volume [3 5])
(<j1> ^volume 3 ^contents [0 1 2 3])
(<j2> ^volume 5 ^contents [0 1 2 3 4 5])
-->
(<s> ^operator <op> = 0)
}
# ------------------------------------------------------------------
gp {rl*water-jug*fill
(state <s> ^name water-jug ^operator <op> + ^jug <j1> <j2>)
(<op> ^name fill ^fill-jug.volume [3 5])
(<j1> ^volume 3 ^contents [0 1 2 3])
(<j2> ^volume 5 ^contents [0 1 2 3 4 5])
-->
(<s> ^operator <op> = 0)
}
# ------------------------------------------------------------------
gp {rl*water-jug*pour
(state <s> ^name water-jug ^operator <op> + ^jug <j1> <j2>)
(<op> ^name pour ^empty-jug.volume [3 5])
(<j1> ^volume 3 ^contents [0 1 2 3])
(<j2> ^volume 5 ^contents [0 1 2 3 4 5])
-->
(<s> ^operator <op> = 0)
}
- Regras de recompensa: são regras similares às outras, porém atuam na modificação da estrutura
reward-linkdo estado associando a recompensa ao operador corrente. Os valores das recompensas são armazenados como atributos (state.reward-link.reward.value). No caso do agente water-jug, a recompensa está associada à meta, isto é, o agente é recompensado se atingir a meta. Para isso, basta uma pequena modificação na regra que detecta se a meta foi atingida:
# --------------------------------------------------------------
sp {water-jug*detect*goal*achieved
(state <s> ^name water-jug ^jug <j> ^reward-link <rl>)
(<j> ^volume 3 ^contents 1)
-->
(write (crlf) |The problem has been solved.|)
(<rl> ^reward.value 10)
(halt)
}
OBS.: o Soar não remove ou modifica estruturas reward-link, cabe ao agente manter a estrutura reward-link em condições adequadas (feedback) para o correto funcionamento do mecanismo de aprendizado por reforço. Se um atributo permanece na estrutura reward-link (similar a uma regra o-supported), então a recompensa será computada diversas vezes reforçando o aprendizado (como vimos inicialmente: o agente Left-Right). Por outro lado, na maioria dos casos, as regras de recompensa devem ser i-supported (criar valores não persistentes para as recompensas).
Semantic Memory no SOAR
Nesta seção exploramos o mecanismo associado à memória semântica (Semantic Memory - SMem) no Soar, conteúdo do Tutorial 8.
Comandos Básicos Associados a SMem
Apresentamos alguns comandos básicos associados ao SMem, veja detalhes em smem command documentation. Como primeiro experimento, vamos carregar (usando o comando smem --add) a SMem e visualizar o conteúdo da memória. Abra o SJD e execute o comando abaixo:
smem --add {(<a> ^name alice ^friend <b>)
(<b> ^name bob ^friend <a>)
(<c> ^name charley)
}
O camando adiciona três objetos na SMem. O comando smem --add é útil para précarregar a base de conhecimento de um agente Soar. O contéudo da SMem pode ser visto usando o comando abaixo:
smem --print
O código abaixo é a saída da impressão:
(@A1 ^friend @B1 ^name alice [+1.000]) (@B1 ^friend @A1 ^name bob [+2.000]) (@C3 ^name charley [+3.000])
As variáveis (<a>, <b> e <c>) usadas no comando smem --add foram instanciadas com os identificadores @A1, @B1 e @C3, respectivamente (cada identificador é prefixado por @). Todos os identificadores da SMem são chamados de Long-Term Identifiers (LTI), isto é, todos os identificadores são persistentes. O comando abaixo serve para visualizar o conteúdo da SMem em forma de diagrama (grafo direcionado , de fato, uma árvore):
command-to-file smem.gv smem --viz
O comando gera o arquivo smem.gv que pode ser visualizado usando o GraphViz [ http://graphviz.org ]. Basta fazer o download, executar o GVEdit e abrir o arquivo smem.gv. A figura abaixo mostra o GVEdit com o conteúdo do arquivo smem.gv (quadro à esquerda) e o respectivo grafo (quadro à direita):
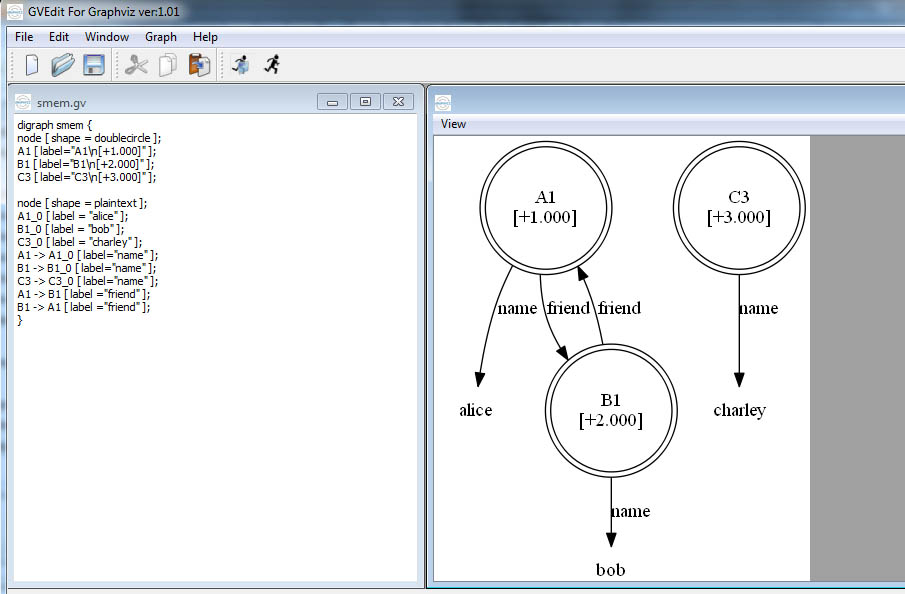
Os LTIs são prefixados por @ quando impressos e são representados por um círculo com margem dupla. Note que a estrutura na SMem (o conhecimento representado) não é necessariamente conexa (como é na WM, ligados direta ou indiretamente a um estado). O conteúdo da SMem independe do conteúdo das outras memórias (WM e memória procedural), o comando abaixo mostra o contéudo das memórias (veja que o conteúdo da SMem não é listado):
print --depth 100 <s> print
Agentes Soar com Memória Semântica
O Soar cria automaticamente um smem link para cada estado e cada smem link possui uma sub-estrutura especializada: um command link para as ações e um result link para feedback da SMem. O comando abaixo imprime a estrutura da SMem:
print --depth 10 <s>
O resultado da impressão segue abaixo:
(S1 ^epmem E1 ^io I1 ^reward-link R1 ^smem S2 ^superstate nil ^type state) (E1 ^command C1 ^present-id 1 ^result R2) (I1 ^input-link I2 ^output-link I3) (S2 ^command C2 ^result R3)
O código acima contém WMEs da forma: <state> ^smem <smem> , <smem> ^command <cmd> e <smem> ^result <r>. Como visto anteriormente, a criação e manutenção dos command links ocorre via regras, a criação e remoção dos result links é feito pelo Soar. Para ativar o mecanismo do SMem num agente Soar basta utlizar o comando abaixo:
smem --set learning on
Para remover os LTIs (objetos persistentes) da SMem basta utilizar o comando abaixo (útil para reinicializar os agentes):
smem --init
Armazenamento de LTIs
A sintaxe do comando para armazenamento na SMem é: <cmd> ^store <id>, tal que <cmd> é o command link de um estado e <id> um identificador. Um agente pode executar múltiplos comandos de armazenamento simultaneamente, os comandos são processados no final da fase em que são executados. Vejamos um exemplo (o código abaixo é parte do conteúdo do arquivo smem-tutorial.soar, disponível [ aqui ] ou [ aqui - repositório local]):
# ---------------------------------------------------------------- # Uso da Memória Semântica # Parte 1 # ---------------------------------------------------------------- sp {propose*init (state <s> ^superstate nil -^name) --> (<s> ^operator <op> +) (<op> ^name init) } # ---------------------------------------------------------------- sp {apply*init (state <s> ^operator.name init ^smem.command <cmd>) --> (<s> ^name friends) (<cmd> ^store <a> <b> <c>) (<a> ^name alice ^friend <b>) (<b> ^name bob ^friend <a>) (<c> ^name charley) } # ---------------------------------------------------------------- sp {propose*mod (state <s> ^name friends ^smem.command <cmd>) (<cmd> ^store <a> <b> <c>) (<a> ^name alice) (<b> ^name bob) (<c> ^name charley) --> (<s> ^operator <op> +) (<op> ^name mod) } # ---------------------------------------------------------------- sp {apply*mod (state <s> ^operator.name mod ^smem.command <cmd>) (<cmd> ^store <a> <b> <c>) (<a> ^name alice) (<b> ^name bob) (<c> ^name charley) --> (<a> ^name alice -) (<a> ^name anna ^friend <c>) (<cmd> ^store <b> -) (<cmd> ^store <c> -) }
Para visualizar o processo de armazenagem na SMem, carregue o código e acione "Step" para executar a primeira fase. Em seguida, ative o "Watch 5" e acione o "Run 1 -p". A figura abaixo mostra parte do trace:
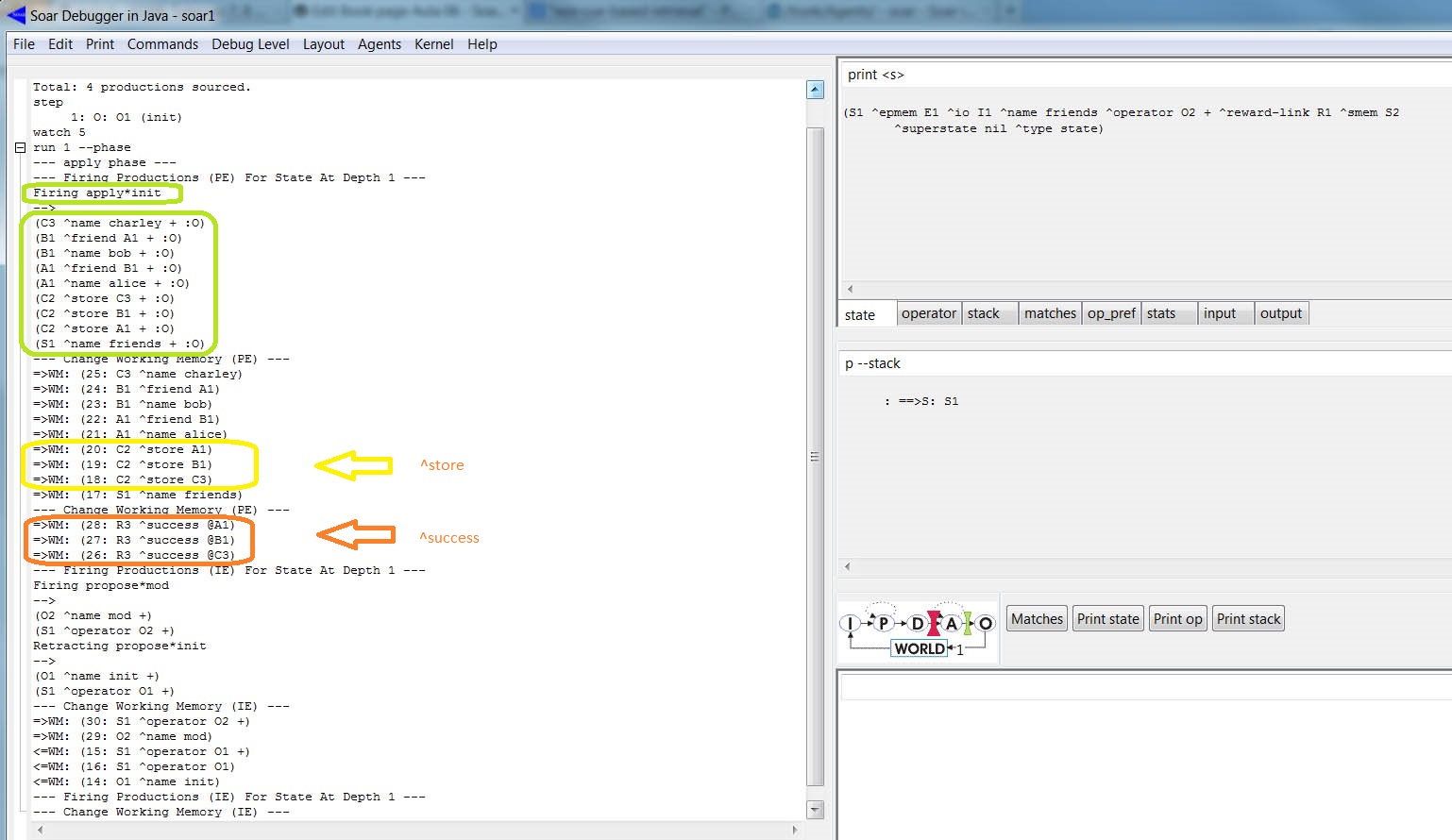
Note que a regra apply*init disparou e adicionou três comandos na WM. A WME referente ao atributo ^success indica o sucesso da armazenagem: ( <r> ^success <id>), onde <r> é o result link do estado sobre o qual o comando de armazenagem foi executado e <id> o valor do comando do comando. Para imprimir o conteúdo da SMem usamos o comando: smem --print. A codificação abaixo exibe o conteúdo da SMem do programa carregado:
(@A1 ^friend @B1 @C3 ^name anna [+1.000])
(@B1 ^friend @A1 ^name bob [+2.000])
(@C3 ^name charley [+3.000])
A aplicação do próximo operador (mod) modifica o conteúdo da SMem (observe a LTI identificada por @A1). Para visualizar esse processo, acionamos o "Step" e o "Run 1 -p". A figura abaixo mostra o trace parcial da aplicação do operador mod (detalhes em laranja):
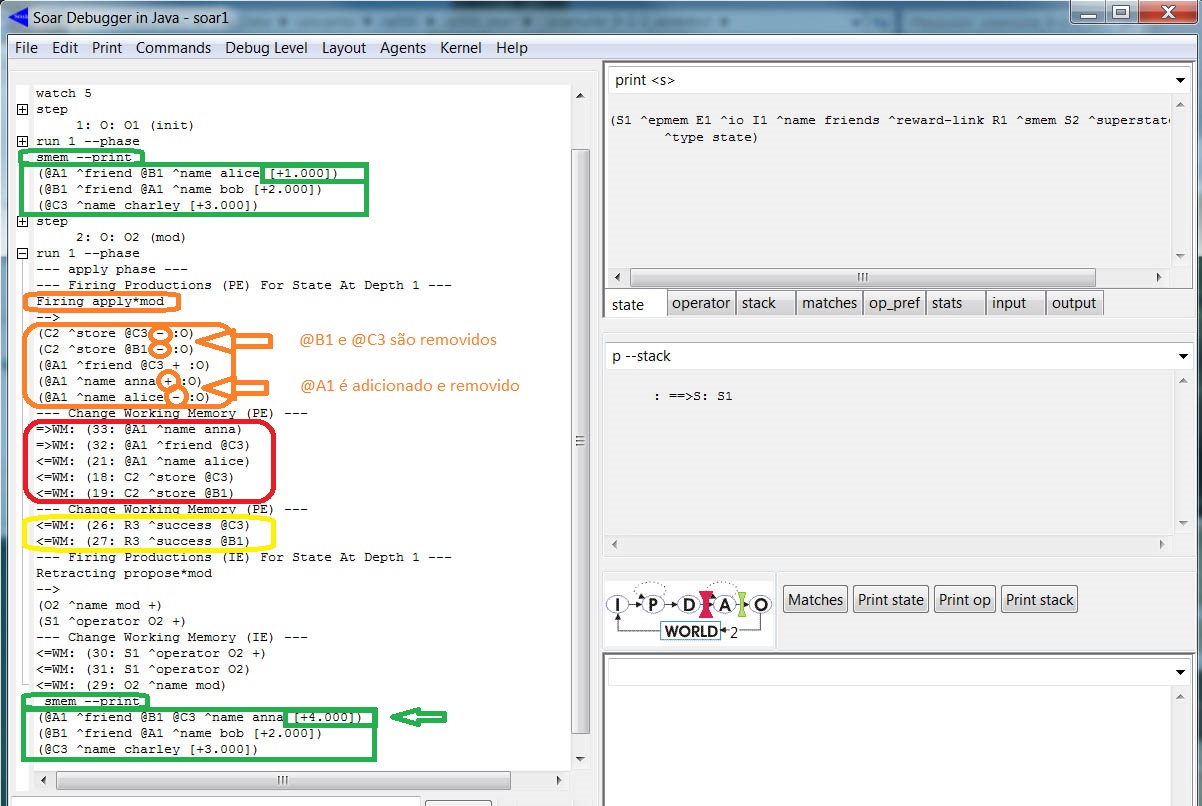
Veja os destaques no trace: os comandos de armazenagem para @B1 e @C3 são removidos pela aplicação da regra e as augmentations de @A1 são adicionadas e removidas. Ao final da fase de elaboração, o mecanismo da memória semântica limpa as informações referentes aos comandos antigos. Vejamos qual o conteúdo da SMem:
(@A1 ^friend @B1 @C3 ^name anna [+4.000])
(@B1 ^friend @A1 ^name bob [+2.000])
(@C3 ^name charley [+3.000])
As augmentations de @A1 foram alteradas na memória semântica, no entanto @B1 e @C3 permanecem inalterados. Vimos como aramazenar elemento na SMem, a seguir veremos como recuperar elementos da SMem.
Non-Cue-Based Retrieval
A primeira forma de recuperar informação (conhecimento) armazenado na memória semântica é a non-cue-based retrieval. A sintaxe desse comando é <cmd> ^retrieve <lti>, onde <lti> é instanciada por uma LTI. Para exemplificar, adicionamos ao código acima (que chamamos de Parte 1) a codificação abaixo (o código abaixo é parte do smem-tutorial.soar - disponível [ aqui ] ou [ aqui - repositório local]):
# ----------------------------------------------------------------
# Uso da Memória Semântica
# Parte 2
# ----------------------------------------------------------------
sp {propose*ncb-retrieval
(state <s> ^name friends ^smem.command <cmd>)
(<cmd> ^store <a>)
(<a> ^name anna ^friend <f>)
-->
(<s> ^operator <op> + =)
(<op> ^name ncb-retrieval ^friend <f>)
}
# ----------------------------------------------------------------
sp {apply*ncb-retrieval*retrieve
(state <s> ^operator <op> ^smem.command <cmd>)
(<op> ^name ncb-retrieval ^friend <f>)
(<cmd> ^store <a>)
-->
(<cmd> ^store <a> -
^retrieve <f>)
}
# ----------------------------------------------------------------
sp {apply*ncb-retrieval*clean
(state <s> ^operator <op> ^smem.command <cmd>)
(<op> ^name ncb-retrieval ^friend <f>)
(<f> ^<attr> <val>)
-->
(<f> ^<attr> <val> -)
}
A estratégia é requisitar da memória semântica TODAS (não há nenhuma pista sobre a informação desejada) as informações de um dado LTI. Por exemplo, as regras acima recuperam todo conhecimento sobre um dos amigos (selecionado randomicamente) de @A1. e remove as augmentations relacionados aos amigos (tais como nome e/ou amigo) da WM. Para visualizar esse processo, carregamos o código e executamos o carregamento das WMEs na SMem. Em seguida, acionamos o "Step" (um dos operadores ncb é selecionado - destaque em laranja na figura abaixo) e, logo depois, o "Run 1 -p" (a regra de aplicação cria um comando de recuperação solicitando informação sobre um dos amigos (destaque em amarelo) e remove (destaque em verde) as augmentations dos amigos). Um segundo "Run 1 -p" gera a fase de saída: todas as recuperações são processadas durante a fase de saída e apenas um comando de recuperação é executado por estado por decisão. A figura abaixo mostra o trace parcial do processo:
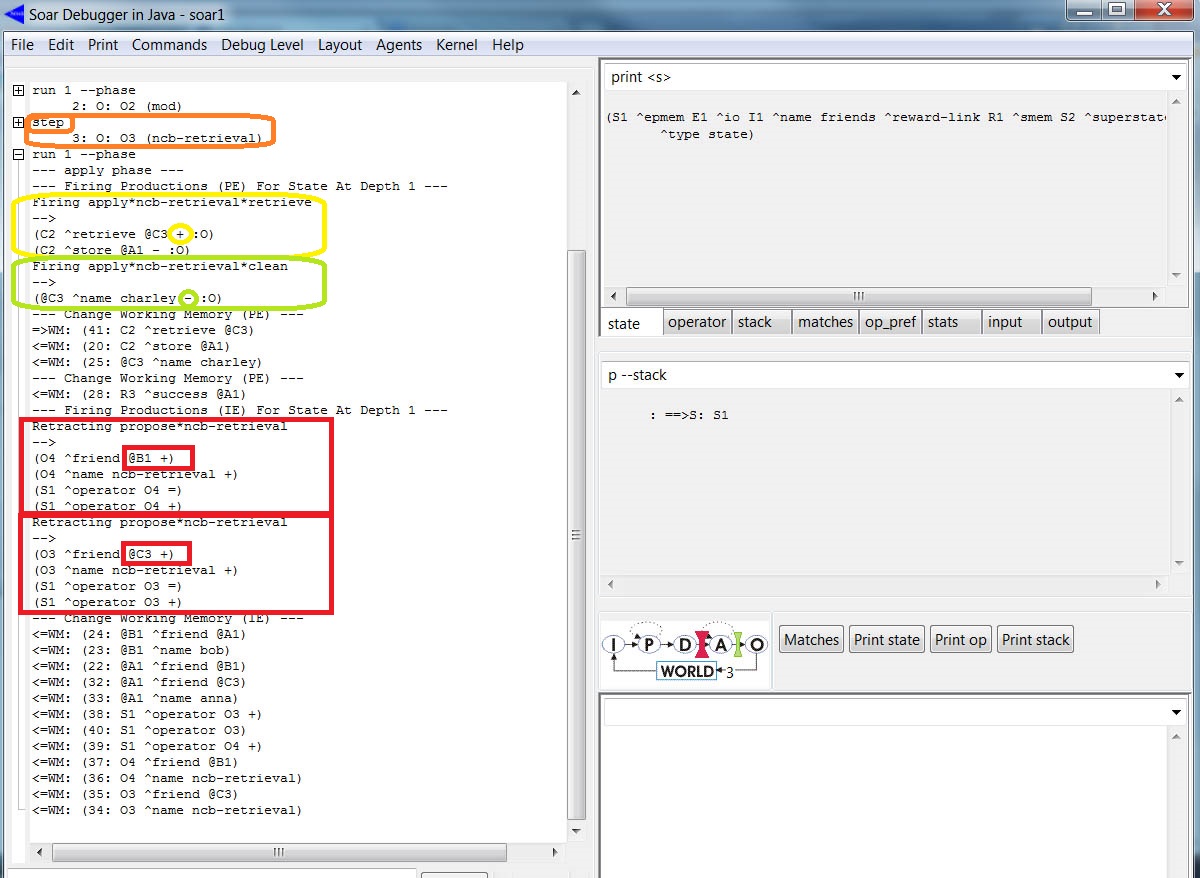
Novamente, usamos o comando print --depth 10 S2 para ver o conteúdo da smem link (destaque em verde na figura abaixo). A figura abaixo mostra o trace desse processo: o elemento (nome do amigo) foi recuperado e adicionado na WM (conforme status indicado pelo ^suscess):
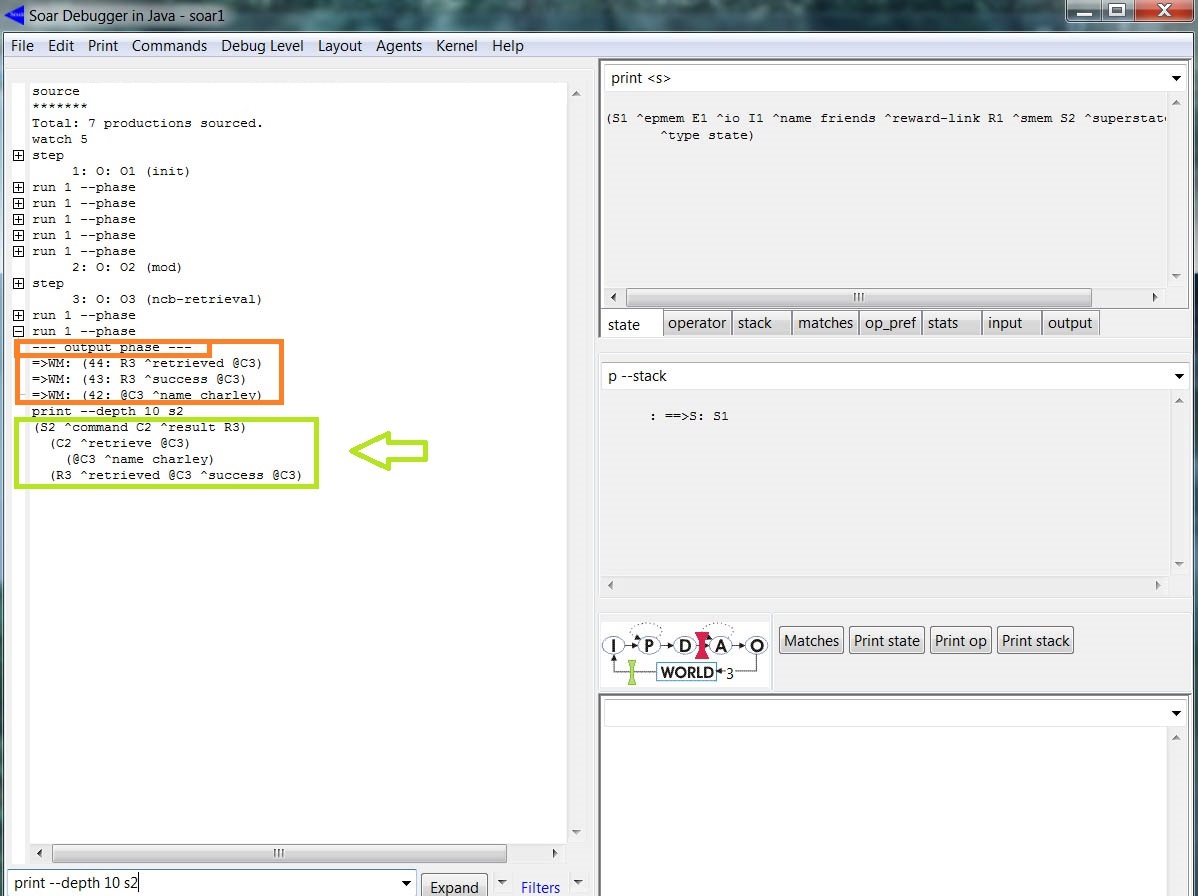
A escolha do elemento a ser recuperado é randômico, logo poderia ser outro amigo (em @B1 ), neste caso a saída seria (análogo ao trace da figura acima):
(S2 ^command C2 ^result R3)
(C2 ^retrieve @B1)
(@B1 ^friend @A1 ^name bob)
(R3 ^retrieved @B1 ^success @B1)
Evidentemente, o conhecimento recuperado é limitado a augmentations da LTI (conforme estabelece a sintaxe do operador ncb).
Recuperação Baseado em Pistas (Cue-Based Retrieval)
Um outro modo do agente resgatar o conhecimento da SMEm é utilizando pistas (cue-based retrieval): o agente solicita da SMEM todas as augmentations de uma LTI que são descritas por um subconjunto dessas augmentations (às descrições parciais chamamos de pistas). A sintaxe do comando é: <cmd> ^query <cue>, onde as augmentations desejadas são identificadas pela <cue> (não mais pela LTI). A codificação abaixo dá exemplo de como escrever regras baseadas em pistas (cb), veja a codificação completa em smem-tutorial.soar [disponível aqui ] ou [ aqui - repositório local]:
# ----------------------------------------------------------------
# Uso da Memória Semântica
# Parte 3
# ----------------------------------------------------------------
sp {propose*cb-retrieval
(state <s> ^name friends ^smem.command <cmd>)
(<cmd> ^retrieve)
-->
(<s> ^operator <op> + =)
(<op> ^name cb-retrieval)
}
# ----------------------------------------------------------------
sp {apply*cb-retrieval
(state <s> ^operator <op> ^smem.command <cmd>)
(<op> ^name cb-retrieval)
(<cmd> ^retrieve <lti>) # Recupera pelo identificador do objeto
-->
(<cmd> ^retrieve <lti> -
^query <cue>)
(<cue> ^name <any-name> ^friend <lti>) # Cue com duas restrições
}
As regras recuperam um objeto cujo identificador atenda duas restrições (constraints): (1) que tenha uma augmentation cujo atributo é name (o valor pode ser qualquer símbolo) e (2) que tenha uma augmentation cujo atributo é friend e o valor é um LTI referente a um objeto recuperado como resultado de um operador aplicado na Parte 1. As augmentations da cue formam um conjunto de restrições (descrições parciais) baseadas no valor de cada WME. Se o valor for uma constante (string, inteiro, ou float) ou uma LTI, então qualquer solicitação feita tem exatamente o par atributo/valor especificado. Porém, se o valor da WME é um identificador short-term (STI), então qualquer solicitação feita tem uma augmentation que tem o mesmo atributo sem restrições para o valor. Para visualizar esse processo, carregamos o código executamos até a aplicação do operador cb-retrieval (vide indicações das setas amarelas na figura abaixo). Um outro "Run 1 -p" irá aplicar a regra que cria uma query command e remove as recuperações anteriores da WM (detalhe em verde na figura abaixo). Novamente, um novo "Run 1 -p" para a fase de saída (output phase).
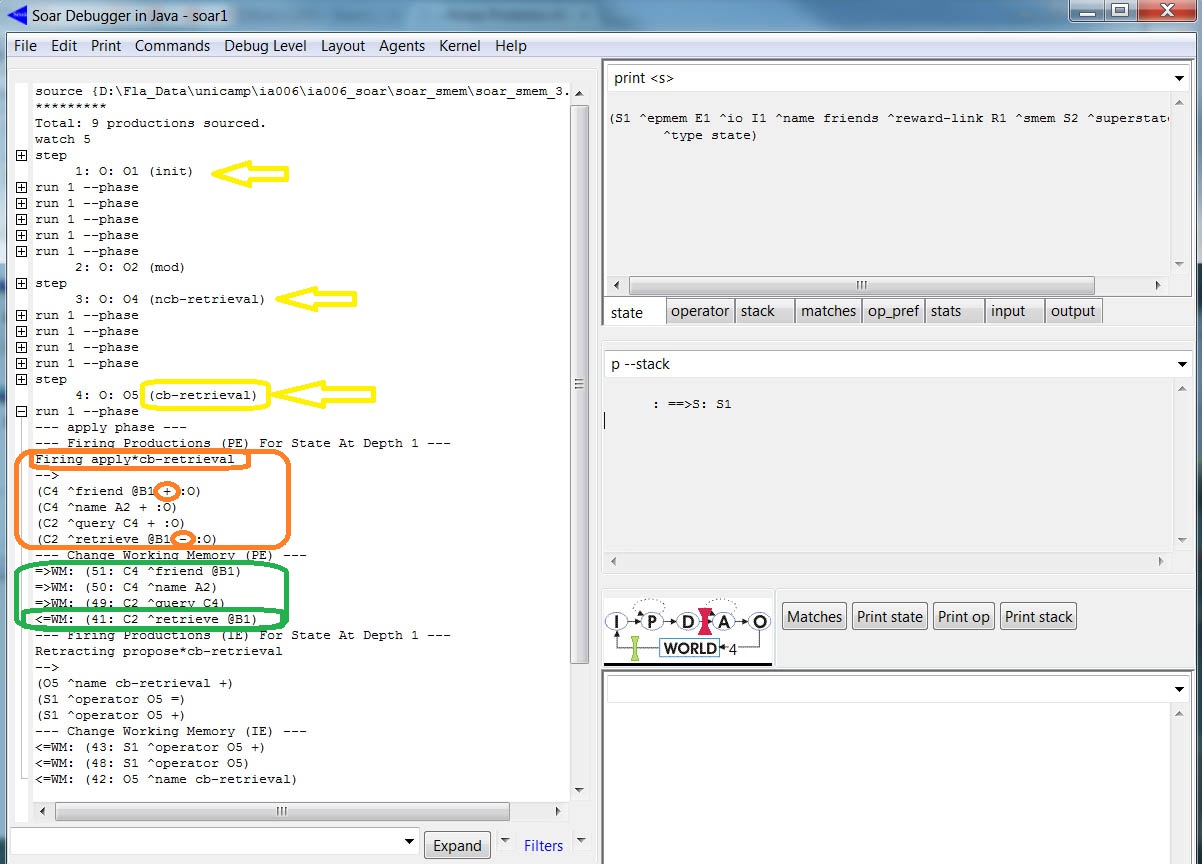
Para ver o status usamos o print --depth 10 S2:
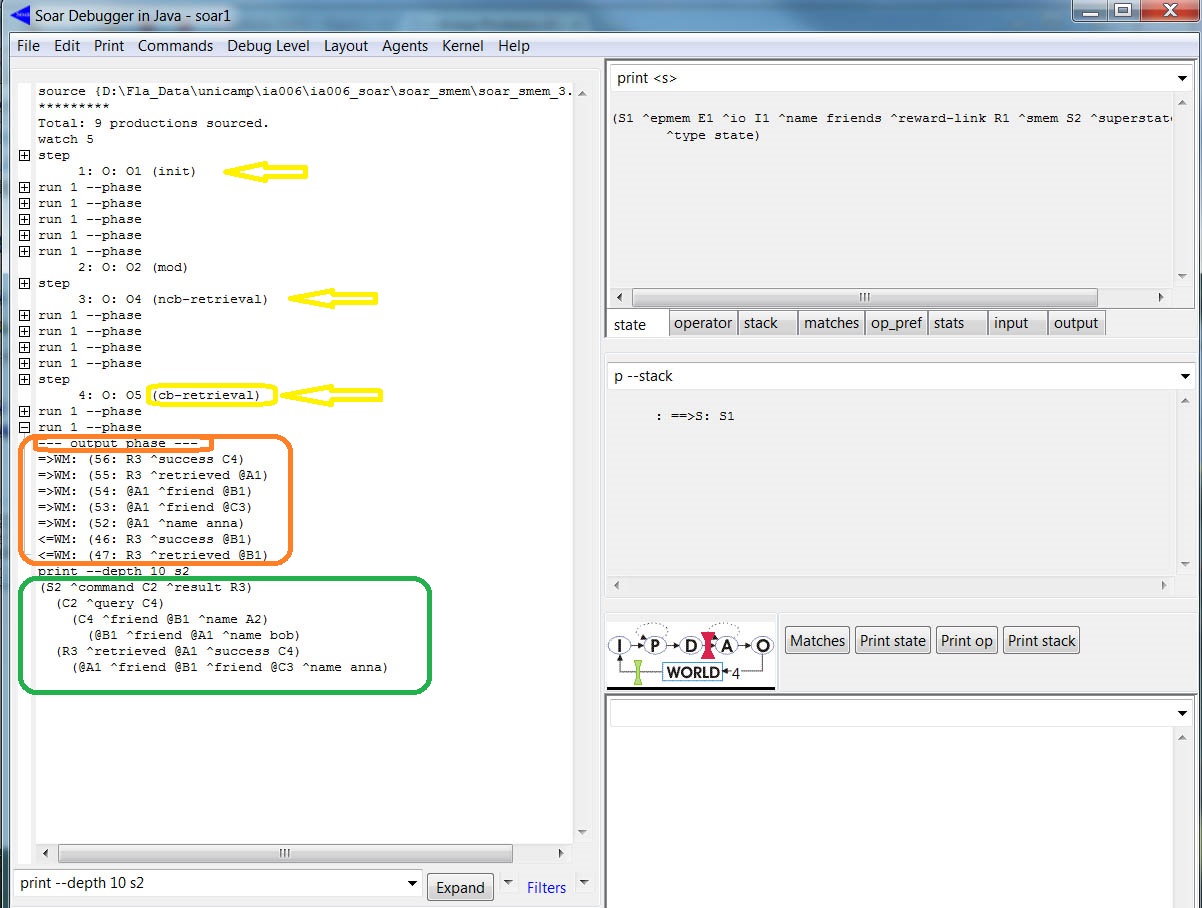
Analogamente ao caso da estratégia anterior, se o objeto recuperado fosse @C3, a saída da impressão seria:
(S2 ^command C2 ^result R3)
(C2 ^query C4)
(C4 ^friend @C3 ^name A2)
(@C3 ^name charley)
(R3 ^retrieved @A1 ^success C4)
(@A1 ^friend @B1 ^friend @C3 ^name anna)
Novamente, sugerimos uma consutla à Seção 6.4.2 (pág.: 95-96) do Manual do Soar para obter maiores detalhes sobre o cue-based retrievals.
Episodic Memory no SOAR
Nesta seção exploramos o conteúdo do Tutorial 9 sobre memória episódica (Episodic Memory - EpMem). A memória episódica mantém as experiências do agente. Tecnicamente, o conteúdo da EpMem é formado pelo estado corrente da WM, isto é, todo o conjunto de WME's (com atributos constantes) na forma de um episódio. Cada conjunto de WME's, associado a um episódio da vida do agente, é capturado automaticamente pela EpMem, armazenado e indexado ao estado do agente (que é um evento temporário) fornecendo um modo de recuperar essa experiência autobiográfica.
Comandos Básicos Associados a EpMem
Vejamos como capturar um episódio e visualizar seu conteúdo na memória, há uma breve descrição em epmem command documentation. Na linha de comando do SJD, execute os comandos abaixo (assim como o qualquer comando essas linhas podem ser carregadas no arquivo que contém as produções):
epmem --set trigger dc # To store episodes each Decision Cycle ("dc"). epmem --set learning on # To enable episodic memory (to enable storage). watch --epmem # To enabled trace
Ao acioner o botão "Step" duas vezes a mensagem abaixo deve aparecer no quadro maior:
NEW EPISODE: 1
A mensagem é um aviso de que um novo episódio rotulado por "1" foi armazenado na EpMem. Para visualizar o contéudo utilize o comando abaixo:
epmem --print 1
A saída é algo como:
(<id0> ^io <id1> ^reward-link <id2> ^superstate nil ^type state) (<id1> ^input-link <id4> ^output-link <id3>)
Também é possível visualizar a codificação acima em forma de grafo. Para isso utilize o comando abaixo:
command-to-file epmem.gv epmem --viz 1
O comando gera o arquivo epmem.gv que pode ser visualizado usando o GraphViz [ http://graphviz.org ]. Basta fazer o download, executar o GVEdit e abrir o arquivo epmem.gv. A figura abaixo mostra o GVEdit com o conteúdo do arquivo empem.gv (quadro à esquerda) e o respectivo grafo (quadro à direita).
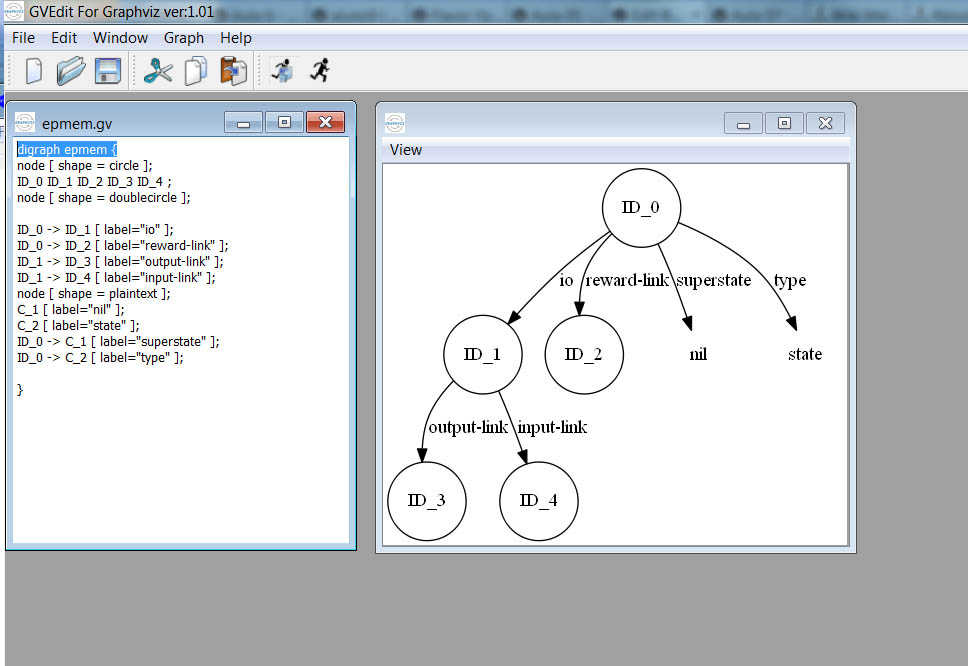
Como mostra o grafo da figura acima, o episódio é armazenado no top-state da WM do agente. A seguir examinamos o processo de armazenamento na EpMem e a forma como o conhecimento episódico é resgatado pelo agente.
Armazenando um Episódio
Na seção anterior vimos os comandos básicos que acionam a EpMem (epmem --set trigger dc e epmem --set learning on) e um comando para ativar o trace (watch --epmem). Também podemos tornar disponível o processamento que ocorre ao final da fase de decisão durante o armazenamento de um episódio:
epmem --set phase selection # Decision cycle phase to encode new episodes # and process epmem link commands
Como alguns WMEs são descartados automaticamente da WM, a EpMem possui um mecanismo que, na fase de armazenamento automática (durante o percurso Breadth-First da WM) cuida para que nenhum WME (ou subestrutura) associado a atributos descartados sejam guardados. Para ativar esse mecanismo basta utilizar o comando abaixo:
epmem --get exclusions # Toggle the exclusion of an attribute string
# constant
Agentes com Memória Episódica
O Soar automaticamente cria um epmem link para cada estado, cada epmem link possui uma subestrutura: com um command link para as ações e um result link para o feedback da EpMem. A figura abaixo mostra a WME com os elementos mencionados (para imprimir os dados utilize o comando: print --depth 10 <s>)
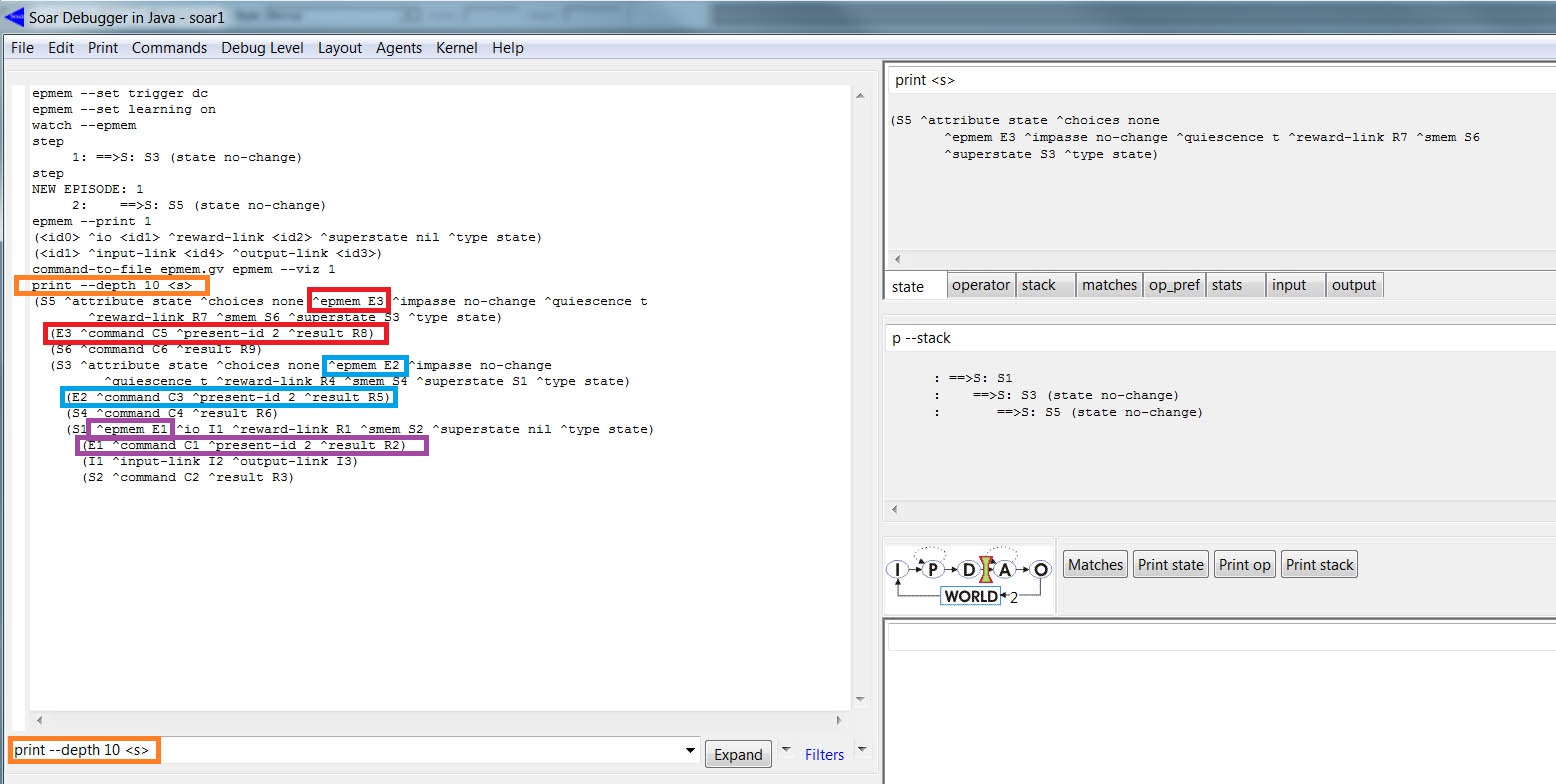
print --depth 10 <s>
Os destaques (em vermelho, azul e roxo) mostram três epmem (E3, E2 e E1 na forma: <state> ^epmem <epmem>, cada uma com três WMEs adicionais: <epmem> ^command <cmd>, <epmem> ^result <r>, e <epmem> ^present-id <episode id>. O controle (criação e manutenção) sobre os command links é feito pelas regras, porém é o Soar que cuida (cria e remove) dos result links.
Recuperação Baseada em Pista (Cue-Based Retrieval)
Uma estratégia para o agente resgatar o conhecimento episódico é a recuperação baseada em pistas (cue-based retieval): o episódio recurepado da EpMem será o mais próximo (via match, a EpMem compara a cue de todos os episódios armazenados, atribuindo um ponto (score) e devolve o episódio mais recente com a pontuação (score) maximal) de alguma especificação parcial (uma cue) de um WME mantida num buffer particular da WM. A sintaxe do comando é (<cmd> ^query <cue>), onde <cue> é a raiz da especificação parcial (cue).
Como vimos anteriormente um episódio é mantido na forma de um grafo direcionado (de fato, uma árvore), um nó folha nesse grafo contém um valor que é uma constante, identificadores (long-term e short-term sem augmentations). Dizemos que uma folha é satisfeita, em relação a um particular episódio, se existe um caminho (uma seqüência de WMEs) da raíz do grafo (do episódio) até a folha; tal que os atributos de todos os WMEs nesse caminho casam exatamente com a especificação parcial dada (referente ao particular episódio) e com os identificadores short-term. Similar ao modo como as variáveis que ocorrem nas condições das regras se ligam a identificadores específicos na WM, porém cada WME folha é considerada de forma independente (é disjuntivo, diferente do match com uma regra que é conjuntivo: vale se todas as condições são satisfeitas). O critério padrão para pontuar um episódio é o de somar os WMEs folhas que satisfazem a pista. Suponha, na figura abaixo, que N1 é o valor do query command:
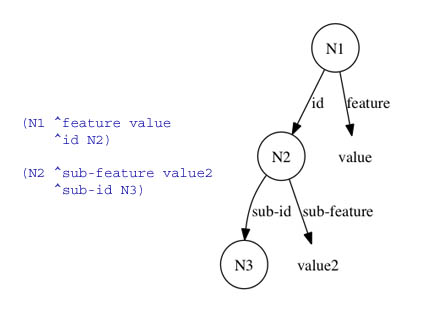
Esta especificação parcial (cue) possui três WMEs nós: (N1 ^feature value), (N2 ^sub-feature value2), and (N2 ^id N3). Agora, considere a estrutura da figura abaixo como sendo um episódio:
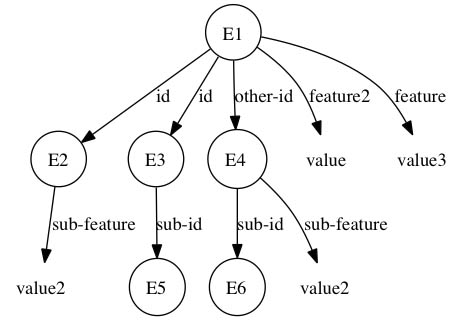
Nessas condições, vejamos quais nós são satisfeitos pelo episódio acima (lembrando que a noção de satisfação é disjuntiva). A figura abaixo mostra esquematicamente que o nó (N2 ^sub-feature value2) é satisfeito pelo episódio. De fato, basta verificar que os identificadores dos objetos correntes (N1 e N2) podem ser "trocados" (variablizing) por variáveis (E1 e E2, respectivamente). Isto é, N1 por E1: (E1 ^id E2) e N2 por E2: (E2 ^sub-feature value2).
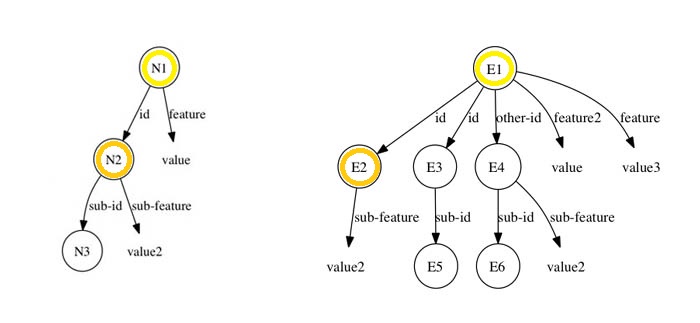
Analogamente, veja figura abaixo, N2 ^id N3 é satisfeita variablizing N1 por E1, N2 por E3 e N3 por E5: (E1 ^id E3) e (E3 ^sub-id E5).
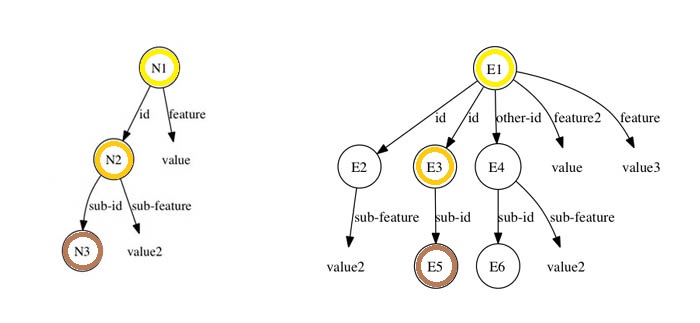
A sub-estrutura em N2 casa com E4, porém como não existe WME (E1 ^id E4) o nó não é considerado (note que E1 ^other-id E4) não satisfaz). Portanto, o episódio apresentado, em relação a especificação parcial (cue), tem pontuação (score) igual a 2.
Por fim, observamos que o nó (N1 ^feature value) não é satisfeito pelo episódio, pois não existe WME (E1 ^feature value). Note que E1 ^feature2 value (o feature é diferente) e E1 ^feature value3) (o valor é diferente) não satisfazem. De fato, não é possível unificar a pista (cue) com o episódio, obter uma pontuação máxima (todos os nós WMEs são satisfeitos). Na linguagem de grafos: obter um isomofismo da pista com um subgrafo do episódio.
Prosseguimos nosso estudo executando o código abaixo (este código é parte do arquivo epmem-tutorial.soar [ aqui ]):
# ----------------------------------------------------------------
# Recuperação do Conhecimento episódico
# Parte 1.
epmem --set trigger dc
epmem --set learning on
watch --epmem
# -------------------------------------------------------------------
sp {propose*init
(state <s> ^superstate nil
-^name)
-->
(<s> ^operator <op> + =)
(<op> ^name init)
}
# -------------------------------------------------------------------
sp {apply*init
(state <s> ^operator <op>)
(<op> ^name init)
-->
(<s> ^name epmem ^feature2 value ^feature value3 ^id <e2>
^id <e3> ^other-id <e4>)
(<e2> ^sub-feature value2)
(<e3> ^sub-id <e5>)
(<e4> ^sub-id <e6> ^sub-feature value2)
}
# -------------------------------------------------------------------
sp {epmem*propose*cbr
(state <s> ^name epmem
-^epmem.command.<cmd>)
-->
(<s> ^operator <op> + =)
(<op> ^name cbr)
}
# -------------------------------------------------------------------
sp {epmem*apply*cbr-clean
(state <s> ^operator <op> ^feature2 <f2> ^feature <f> ^id <e2>
^id <e3> ^other-id <e4>)
(<e2> ^sub-feature value2)
(<e3> ^sub-id)
(<op> ^name cbr)
-->
(<s> ^feature2 <f2> -
^feature <f> -
^id <e2> -
^id <e3> -
^other-id <e4> -)
}
# -------------------------------------------------------------------
sp {epmem*apply*cbr-query
(state <s> ^operator <op> ^epmem.command <cmd>)
(<op> ^name cbr)
-->
(<cmd> ^query <n1>)
(<n1> ^feature value ^id <n2>)
(<n2> ^sub-feature value2 ^sub-id <n3>)
}
Carregue o programa acima no SJD e execute-o com um "Step", prossiga com "Run 1 -p". Em seguida, imprima o top state da WM: print --depth 10 s1. O top state contém as estruturas do episódio acima (tal como: ^feature value) e WMEs (tal como: ^superstate nil). vide figura abaixo. Novamente, ao acionar o "Step" aparecerá uma mensagem sobre o episódio 1 e após outro "Run 1 -p" (para aplicar o operador cbr) ao imprimir o top state (print --depth 10 s1) da WM nota-se a adição da pista ao command (C1) na estrutura do epmem link.
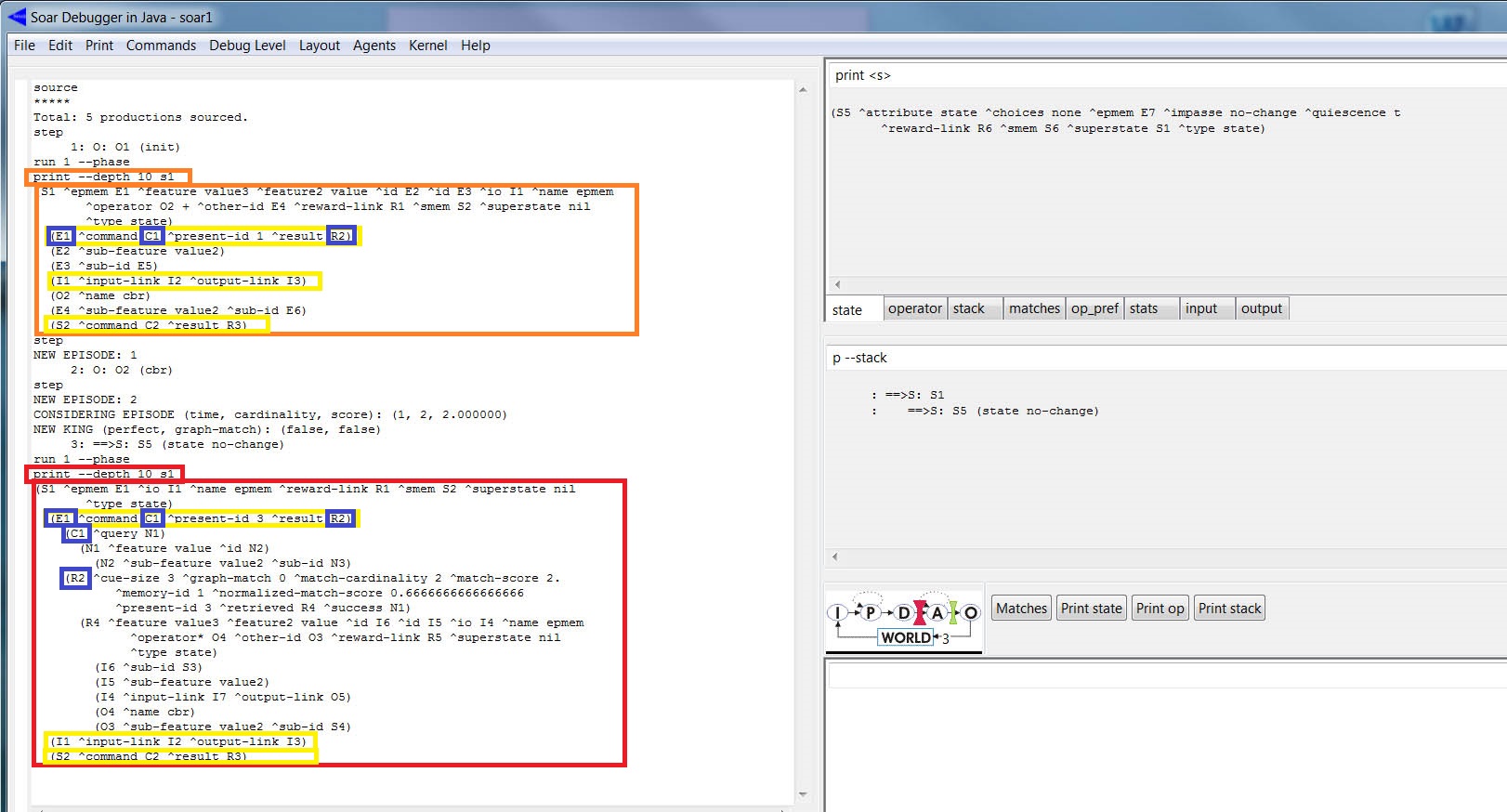
Após um terceiro "Step", vemos a mensagem sobre o armazenamento do segundo episódio e o processamento do cue-based query :
CONSIDERING EPISODE (time, cardinality, score): (1, 2, 2.000000)
NEW KING (perfect, graph-match): (false, false)
A primeira linha indica a ocorrência da compração na EpMem entre a pista e o primeiro episódio (time = 1), a cardinalidade do conjunto de nós satisfeitos (cardinality = 2), que é a pontuação alcançada (score = 2). A segunda linha indica que se trata do primeiro episódio: "King" [of the mountain]. A informação perfect = false e graph-match = false indicam que a pontuação atingiu somente 2 em 3, isto é, que não ocorreu um casamento perfeito, logo não houve um match do grafo. Em relação ao segundo episódio, não há nehuma característica em comum com a pista (a aplicação do operador cbr remove essas estruturas). A codificação abaixo mostra a impressão do conteúdo da EpMem link (print --depth 10 E1):
(E1 ^command C1 ^present-id 3 ^result R2) (C1 ^query N1) (N1 ^feature value ^id N2) (N2 ^sub-feature value2 ^sub-id N3) (R2 ^cue-size 3 ^graph-match 0 ^match-cardinality 2 ^match-score 2.^memory-id 1 ^normalized-match-score 0.666666666666666 ^present-id 3 ^retrieved R4 ^success N1) (R4 ^feature value3 ^feature2 value ^id I5 ^id I6 ^io I4 ^name epmem ^operator* O5 ^other-id O4 ^reward-link R5 ^superstate nil ^type state) (I5 ^sub-feature value2) (I6 ^sub-id S3) (I4 ^input-link I7 ^output-link O6) (O5 ^name cbr) (O4 ^sub-feature value2 ^sub-id S4)
O código acima indica o sucesso da recuperação do conhecimento episódico. O link R2 mostra os dados da recuperação baseada em pista e indica R4 como a raiz do episódio.
Acesso Temporal
Também é possível recuperar episódios que ocorram antes/depois do último episódio recuperado. Os comandos para isso tem a seguinte sintaxe: <cmd> ^previous <id> e <cmd> ^next <id>, onde <id> é qualquer identificador. O código abaixo dá um exemplo de uso do next. Novamente, o código abaixo é parte do arquivo epmem-tutorial.soar [ aqui ]:
# ------------------------------------------------------------------
# Recuperação do Conhecimento episódico
# Parte 2.
# -------------------------------------------------------------------
sp {epmem*propose*next
(state <s> ^name epmem
^epmem.command.query)
-->
(<s> ^operator <op> + =)
(<op> ^name next)
}
# -------------------------------------------------------------------
sp {epmem*apply*next
(state <s> ^operator <op>
^epmem.command <cmd>)
(<op> ^name next)
(<cmd> ^query <q>)
-->
(<cmd> ^query <q> -
^next <next>)
}
As regras da "Parte 1" tratam da recuperação do conehcimento episódico, as regras acima, "Parte 2", servem para recuperar o episódio seguinte a um episódio recuperado. Para visualizar o funcionamento faça o mesmo procedimento efetuado com a Parte 1: carregue o programa, clique em "Step", em seguida em “Run 1 -p” e imprima o EpMem link print --depth 10 E1. Novamente, ative o "Run 1 -p" e imprima o EpMem link. A codificação abaixo mostra algumas das informações impressas:
(E1 ^command C1 ^present-id 4 ^result R2)
(C1 ^next N4)
(R2 ^memory-id 2 ^present-id 4 ^retrieved R6 ^success N4)
(R6 ^io I8 ^name epmem ^operator* O7 ^reward-link R ^superstate nil
^type state)
(I8 ^input-link I9 ^output-link O8)
(O7 ^name next)
Note que a result structure (R2) mostra que o episódio 2 (^memory-id 2) foi recuperado com sucesso (vide command C1). Maiores informações sobre o EpMem estão disponíveis no Capitulo 7 do Manual do Soar.
Theme by Danetsoft and Danang Probo Sayekti inspired by Maksimer