
- Aula 01 - 01/03/2013 - WorldServer3D webstart e Programa cliente de teste
- Aula 02 - 08/03/2013 - Início dos estudos do Soar
- Aula 03 - 15/03/2013 - Agente para jogo EATERS
- Aula 04 - 22/03/2013 - TankSoar
- Aula 05 - 05/04/2013 - Missionários e Canibais (Tutorial 4 - controle de busca) e Tutorial 5 (planejamento e aprendizagem)
- Aula 06 - 12/04/2013 - Tutoriais 7, 8 e 9
- Aula 07 - 19/04/2013 - Integração WorldServer3D
- Aula 08 e aula 09 - 26/04/2013 e 03/05/2013 - Clarion
- Aula 10 e aula 11 - 10/05/2013 e 17/05/2013 - Integração Clarion e WorldServer3D
- Aula 12 - 24/05/2013 - Estudo inicial da arquitetura LIDA
- Aula 13 - 07/06/2013 - LIDA - Exemplos de implementação prática
- Aula 14 e aula 15 - 14/06/2013 e 21/06/2013 - Elaboração projeto
You are here
Tutorial 7 - Reinforcement Learning
Reinforcement Learning (RL) é uma técnica de aprendizado incremental, em oposição ao CHUNKING, onde o aprendizado é feito num único passo, dependendo do reconhecimneto de estados corretos/incorretos.
O uso do RL corresponde à atribuição de parâmetros numéricos de indiferença aos operadores; inicialmente os operadors iniciam com um mesmo valor numérico ZERO de indiferença, indicando que todos tem a MESMA probabilidade de ocorrência; a seguir estão as regras dos operadores no exemplo left-right:
##
# Soar-RL rule for moving left
##
sp {left-right*rl*left
(state <s> ^name left-right
^operator <op> +)
(<op> ^name move
^dir left)
-->
(<s> ^operator <op> = 0)
}
##
# Soar-RL rule for moving right
##
sp {left-right*rl*right
(state <s> ^name left-right
^operator <op> +)
(<op> ^name move
^dir right)
-->
(<s> ^operator <op> = 0)
}
Com a aplicação dos operadores, contudo, SOAR altera os parâmetros numéricos de indiferença a partir da premiação atribuída para cada operação executada; a definição da premiação é feita a partir de regras especificamente definidas, as quais operam sobre a extensão "^reward-link", criando a estrutura:
^reward.value <value>
Abaixo está a regra de premiação no caso do programa left-rigth; nesse caso ela referencia valores de premiação que são criados na regra de inicialização, também reproduzida a seguir:
##
# Store the available directions
# and associated reward on the state
##
sp {apply*initialize-left-right
(state <s> ^operator <op>)
(<op> ^name initialize-left-right)
-->
(<s> ^name left-right
^direction <d1> <d2>
^location start)
(<d1> ^name left ^reward -1)
(<d2> ^name right ^reward 1)
}
##
# When a direction is chosen, assert the associated reward
##
sp {elaborate*reward
(state <s> ^name left-right
^reward-link <r>
^location <d-name>
^direction <dir>)
(<dir> ^name <d-name> ^reward <d-reward>)
-->
(<r> ^reward <rr>)
(<rr> ^value <d-reward>)
}
Uma vez que o RL está habilitado no SOAR, os parâmetros numéricos de indiferença vão sendo constantemente alterados a partir as premiações, mesmo que durante ciclos diferentes de execução:
rl --set learning on
indifferent-selection --epsilon-greedy
O programa exemplo do tutorial, o agente "left-right" possui regras de premiação que visam escolher a direção RIGHT; após ciclos de execução é possível verificar que o parâmetro numérico de indiferença do movimento para direita aumenta, indicando uma maior probabilidade de escolha:
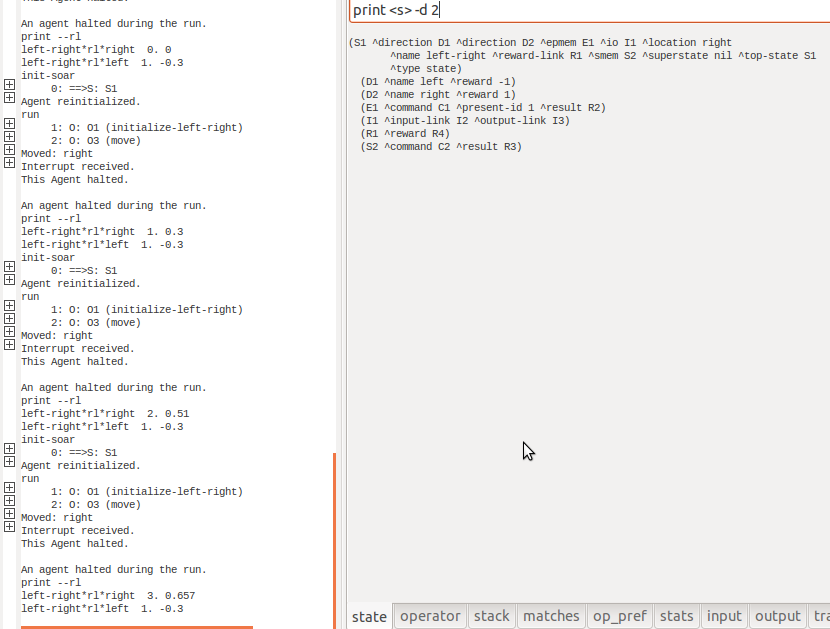
PASSOS PARA UTILIZAÇÃO DO RL
Para ilustrar os passos de utilização do RL, é proposta a alteração do programa "water-jug"; resumidamente, os passos de alteração serão:
- Alterar o código para os operadores fazerem uso de regras RL
- Criar uma ou mais regras de premiação
- Habilitar o mecanismo de RL no SOAR
O primeiro passo pode ser bastante trabalhoso, uma vez que é necessário atribuir parâmetros numéricos de indiferença para cada par possível ESTADO-AÇÃO; somente dessa forma o SOAR poderá, ao longo das execuções e de acordo com as premiações recebidas, definir qual a melhor ação em cada estado específico.
Para essa atribuição SOAR oferece o comando GP o qual produz regras de acordo com um intervalo de valores especificados:
gp {rl*water-jug*empty
(state <s> ^name water-jug
^operator <op> +
^jug <j1> <j2>)
(<op> ^name empty
^empty-jug.volume [3 5])
(<j1> ^volume 3
^contents [0 1 2 3])
(<j2> ^volume 5
^contents [0 1 2 3 4 5])
-->
(<s> ^operator <op> = 0)
}
Nesse caso acima, são geradas regras para atribuição do parâmetro numérico de indiferença para o operador EMPTY para as jarras de tamanho 3 e 5 ([3 5]), quando a jarra de tamanho 3 tiver de 0 a 3 de conteúdo ([0 1 2 3]) ou quando a jarra de tamanho 5 tiver de 0a 5 de conteúdo ([0 1 2 3 4 5]).
As regras de premiação são como qualquer outra regra do SOAR, com a diferença de modificar a extensão "^reward-link", criando a extensão "^reward.value REWARD-VALUE". Para o problema do water-jug, a única premiação será fornecida quando for atingido o objetivo:
sp {water-jug*check*goal-achieved
(state <s> ^name water-jug
^desired.jug <desired>
^jug <j>
^reward-link <rl>)
(<desired> ^volume <v>
^contents <c>)
(<j> ^volume <v>
^contents <c>)
-->
(<rl> ^reward.value 10)
(write (crlf) | The problem has been solved: | <v> | has | <c>)
(halt)
}
Um ponto que é mencionado no tutorial é o fato de que o SOAR, por si, não faz nenhum controle sobre as alterações feitas no "^reward-link": apenas o valor do "^reward.value" é considerado, a cada ciclo, para compor o parâmetro numérico de indiferença do operador executado. Caso existam valores inconsistentes no "^reward-link" será feita uma atualização também inconsistente pelo mecanismo de RL.
Com o mecanismo ligado na primeira execução SOAR leva 9 ciclos para resolver; já na segunda resolve em 5 ciclos, que compõe a melhor solução (inicialização + 4 passos):

Um ponto interessante é que, mesmo depois de ter aprendido como atingir a melhor solução, em algumas execuções SOAR não aplica a melhor solução. De acordo com o tutorial, esse comportamento é por conta da política de exploração default do mecanismo de reinforcement learning: por default é utilizada a política "epsilon-greedy" com o valor de epsilon = 0.1, o que significa que em 10% das vezes SOAR vai escolher um operador randomicamente, ao invés de escolher o de maior valor de indiferença - o que é feito nas outras 90% das vezes.
De fato se for alterado o valor de epsilon para 0 com o comando:
indifferent-selection --epsilon 0
Todas as vezes a melhor solução é retornada.
Theme by Danetsoft and Danang Probo Sayekti inspired by Maksimer