
- Relatório 1 - Introdução
- Relatório 2 - SOAR: Tutorial 1
- Relatório 3 - SOAR: Tutorial 2
- Relatório 4 - SOAR: Tutorial 3
- Relatório 5 - SOAR: Tutoriais 4 e 5
- Relatório 6 - SOAR: Tutoriais 7,8 e 9
- Relatório 7 - SOAR: Controlando o WorldServer3D
- Relatório 8 - CLARION
- Relatório 9 - CLARION: Controlando o WorldServer3D
- Relatório_10 - LIDA 1: Entendendo a Arquitetura
- Relatório_11 - LIDA 2: Exemplos de Implementação Prática
- Relatório_12 - Projeto
You are here
Relatório 6 - SOAR: Tutoriais 7,8 e 9

Sumário
Exercício 1: aprendizado por reforço
O aprendizado por reforço é um mecanismo de aprendizagem do Soar que altera o comportamento do agente ao longo do tempo por meio de estímulos de recompensa. Esses estímulos contribuem para a alteração númerica das preferências indiferentes na memória procedural. Para implementar o mecanismo de aprendizado por reforço foi criado um agente que pode se movimentar para a direita ou para a esquerda. Inicialmente a preferência para as duas direções são iguais, mas quando o agente escolhe mover-se para a direção "esquerda", a preferência para essa direção recebe "-1", caso contrário, a preferência para a direção "direita" recebe "+1". Veja na Figura 1.1 as regras que, respectivamente, propõe o agente e aplica o operador de inicialização.
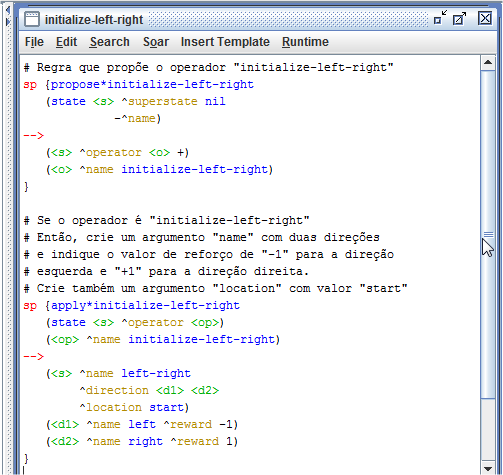
Figura 1.1: Regras de inicialição do agente.
Na Figura 1.2 são apresentados as seguintes regras: a regra que propõe o operador move, a que inicializa a preferências para a direção left com 0, a que inicializa a preferência para a direção "right" com 0 e a que aplica o operador move.
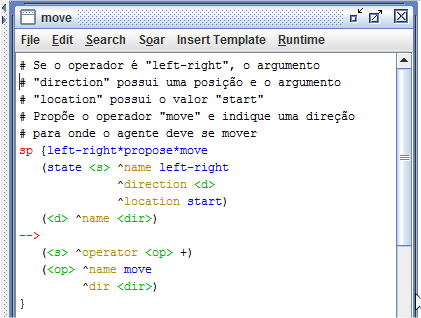


Figura 1.2: Operador move.
Depois de criar as regras que proposição e aplicação do operador move, foi criada a regras que atribui um reforço negativo para o agente quando ele escolhe a direção left e um reforço positivo quando ele escolhe a direção right. Foi criada também a regra que interrompe o agente quando ele escolhe uma direção, conforme pode ser observado na Figura 1.3.


Figura 1.3: Regra que aplica o aprendizado por reforço e regra que interrompe o agente.
Por padrão o mecanismo de aprendizado por reforço é desativado no Soar Debugger. Para ativá-lo devem ser usados os seguintes comandos:
rl --set learning on indifferent-selection --epsilon-greedy
O primeiro comando apresentado acima, ativa o aprendizado por reforço, enquanto o segundo defini a política de exploração.
Para verificar a ação do mecanismo de aprendizado por reforço, após abrir o programa que possui o agente left-right no Soar Debugger, foram executados os comandos de ativação desse mecanismo. Após isso, foi executado o comando step para inicilizar o agente. Então, o próximo passo foi a execução do comando print --rl, que mostra as preferências numéricas na memória procedural. Inicialmente, as preferências estavam 0 para as duas direções. Depois, executando o comando step mais uma vez, seguido pelo comando print --r1, foi observado que o aprendizado por reforço alterou as preferências das direções right e left, conforme pode ser observado na Figura 1.4.
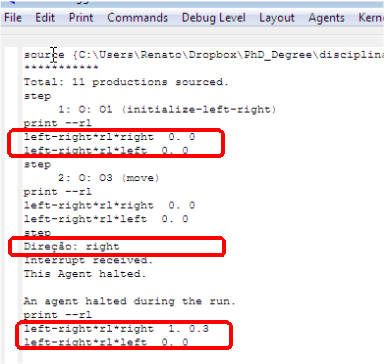
Figura 1.4: Preferências numéricas na memória procedural.
Um problema que pode ser observado é que mesmo reinicializando o agente, o Soar mantém armazenadas as preferências numéricas da rodada anteior, cujos valores são usados para atualizar as preferências numéricas usando aprendizado por reforço. Por exemplo, pode ser observado na Figura 1.4 que a preferência para a direção right foi atualizado para 0.3. Ao reinicializar o agente, conforme mostra a Figura 1.5, a preferência continua com o valor que tinha antes do agente ser inicializado.
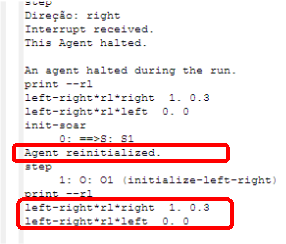
Figura 1.5: Preferências numéricas na memória procedural após reinicializar o agente.
Para facilitar o entendimento de como aplicar o aprendizado por reforço em um agente, o programa Water Jug sofreu algumas alterações. O primeiro passo para habilitar o mecanismo de aprendizado por reforço nesse programa foi modificar as suas regras removendo o sinal de "=" dos operadores nas regras empty, fill e pour, conforme é mostrado na Figura 1.6.
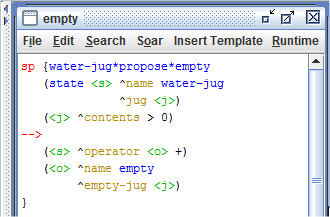
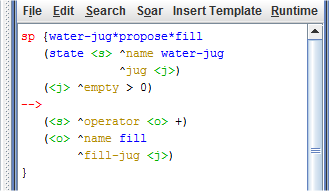

Figura 1.6: Alteração nas regras do programa Water Jug para eliminar as preferências indiferentes, transformando-as em preferências aceitáveis.
Depois as alterar as preferências indiferentes para preferências aceitáveis, foram criadas as regras que detectam as preferências indiferentes e as transformam em regras com preferências indiferentes numéricas.
Para que o mecanismo de aprendizado por reforço dê um feedback para cada ação em cada estado, é necessário que se tenha uma regra de aprendizado por reforço para cada par de estado-ação. No programa Water Jug, por exemplo, um estado pode ser representado pelo volume de água do jarro e a ação pode ser empty, fill ou pour para um dos dois jarros. Logo, para esse programa, seriam necessárias 144 regras de aprendizado por reforço, tornando inviável escrevê-las manualmente. Então, para solucionar esse problema foi usado o comando Soar gp para gerar as regras necessárias. Esse comando cria automaticamente todas as regras de combinação estado-ação necessárias para o uso do aprendizado por reforço. A Figura mostra como implementar o comando Soar gp.

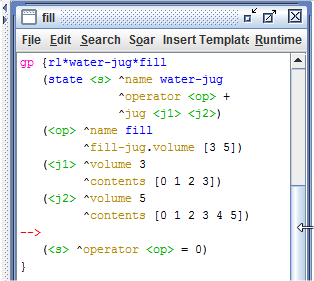

Figura 1.7: Soar gp.
O próximo passo foi a criação da regra de recompensa. No problema Water Jug, a recompensa foi implementada apenas na regra que detecta o estado desejado. Veja na Figura 1.8.
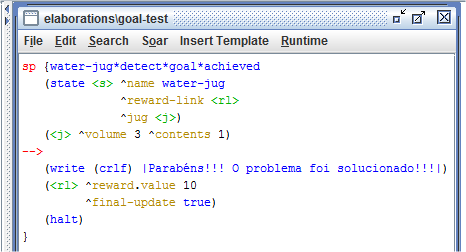
Figura 1.8: Regra de recompensa.
Depois de finalizar a implementação do mecanismo de aprendizado por reforço no programa Water Jug, ele foi executado no Soar Debugger. A Figura 1.9 mostra as preferências obtidas após o programa solucionar o problema.



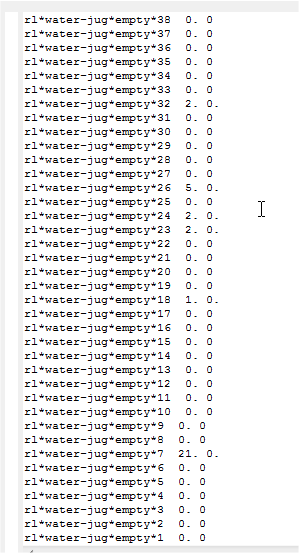
Figura 1.9: Preferências obtidas após o programa Water Jug solucionar o problema.
Outro conceito importante em relação ao tema aprendizado por reforço é a sua política de exploração. É através da política de exploração que mesmo um operador tendo maior preferência sobre outros, os outros ainda possuem chances de serem escolhidos. Por exemplo, no programa left-right o operador que movimenta o agente para a direção right ganha maior preferência com o aprendizado por reforço. Porém, se o programa for executado diversas vezes, em algumas delas, o operador que movimenta o agente para a direção left será selecionado. Existem 5 tipos de políticas de exploração no Soar: boltzmann, epsilon-greedy, softmax, first e last. Essas políticas controlam a probabilidade de seleção dos operadores. A probabilidade aumenta para alguns operadores por meio do aprendizado por reforço, mas os outros operadores ainda mantém pelo menos uma pequena probabilidade de serem selecionados.
Para verificar qual a política de exploração está sendo usada no momento, basta usar o comando indifferent-selection no Soar Debugger. Outro comando importante é o indifferent-selection --stats que mostra também os parâmentros da política de exploração atual.
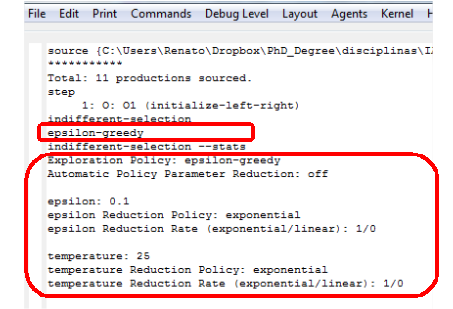
Figura 1.10: Comando das políticas de exploração.
O tutorial do Soar usa a política de exploração epsilon-greedy que pode ser sumarizada da seguinte forma:
- com probabilidade (1 - epsilon), escolha o operador com maior preferência. Com probabilidade epsilon, faça uma seleção aleatória de todos os operadores indiferentes.
Para ilustrar o funcionamento da política de exploração epsilon-greedy, a Figura 1.11 mostra o resultado obtido após alterar o valor de epsilon para 1, por meio do comando indifferent-selection --epsilon 1. Observe que esse valor de epsilon faz com que a seleção aleatória seja uniforme. Se o valor escolhido fosse mais próximo de zero, aumentaria a chance do operador com maior preferência ser selecionado. Se fosse 0, sempre o operador com maior preferência seria selecionado.
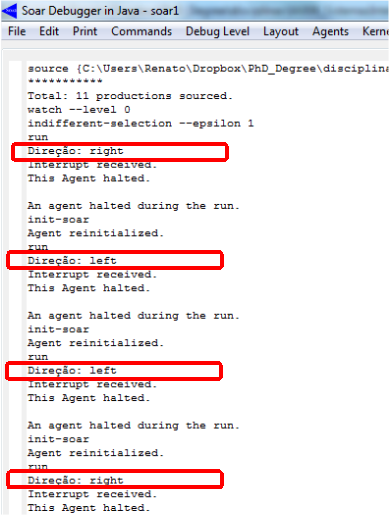
Figura 1.11: Alteração do valor de epsilon.
Exercício 2: memória semântica
A memória semântica é um mecanismo do Soar que permite que os agentes armazenem e recuperem elementos que são persistentes, complementando a memória de trabalho de curto prazo e outras memórias de longo prazo, tais como a memória procedural.
Para adicionar elementos à memória semântica pode ser usado o comando smem add, conforme mostrado a seguir:
smem --add {
(<a> ^name Renato ^friend <b>)
(<b> ^name Leandro ^friend <a>)
(<c> ^name Bruno)
}
O código mostrado acima, adicionou três elementos à memória de trabalho. Para visualizá-los basta usar o comando smem --print. Veja o resultado na Figura 2.1.
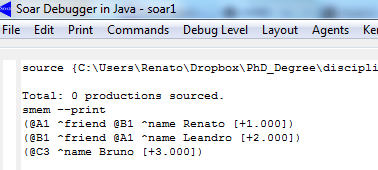
Figura 2.1: Conteúdo da memória semântica.
O conteúdo da memória semântica pode ser visualizado graficamente. Para isso pode ser usado o comando command-to-file smem.gv smem --viz . Esse comando, ao ser executado no Soar Debugger, exporta o conteúdo da memória semântica para um arquivo chamado smem.gv no mesmo diretório em que se encontra o Soar Debugger. O nome smem.gv não é obrigatório. Veja, na Figura 2.2, o arquivo que foi criado.
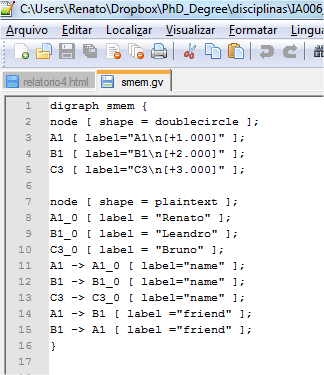
Figura 2.2: Arquivo que contém a representação gráfica do conteúdo da memória semântica.
O arquivo apresentado acima pode ser visualizado graficamente pelo programa Graphviz que pode ser encontrado no seguinte endereço web: http://graphviz.org, conforme mostra a Figura 2.3.

Figura 2.3: Representação gráfica do conteúdo da memória semântica.
Para um agente conseguir interagir com a memória semântica ele usa estruturas uma estrutura especial, a smem link. Essa estrutura é criada automaticamente pelo Soar na memória de trabalho e possui a seguinte subestrutura: ^command, que é usado para o agente iniciar as ações, e ^result, que é usado para receber um feedback da memória semântica. Para visualizar essa estrutura, pode-se usar o comando print --depth 10 <s>, conforme mostra a Figura 2.4.

Figura 2.4: Estrutura smem link.
Porém, para que a estrutura apresentada acima seja útil para que o agente consiga interagir com a memória semântica, é necessário ativar esse mecanismo, que por padrão é desativado no Soar. Para isso, deve-se usar o seguinte comando: smem --set learning on.
Para conseguir armazenar um elemento na memória semântica, o agente precisa usar o comando store, seguido pelos identificadores dos objetos que se deseja armazenar. Veja um exemplo desse comando no programa apresentado na Figura 2.5.

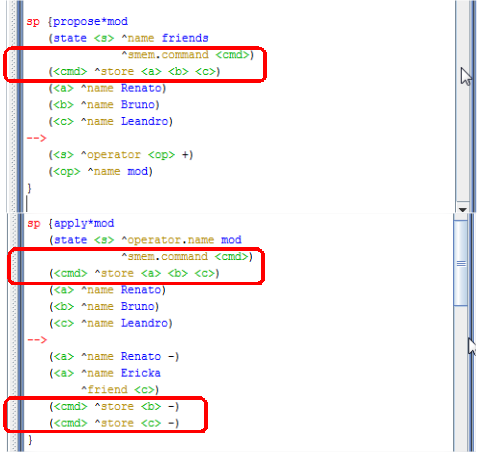
Figura 2.5: Regras que usam o mecanismo de memória semântica.
Conforme mostra a Figura 2.6, a regra apply*init é executada e adiciona 3 elementos na memória de trabalho (a, b e c), cujos atributos name tem os seguintes valores Renato, Leandro e Bruno. Depois a regra apply*mod altera o valor do elemento a e remove os elementos b e c.
Abrindo o programa apresentado na Figura 2.5 no Soar Debugger e clicando no botão Step, observa-se que o operador init é selecionado. Após isso, clicando no botão Watch 5 e depois no botão Run 1 -p, pode ser analisado como o operador é aplicado. Conforme é apresentado na Figura 2.6, quando a regra apply*init é executada, os elementos a, b e c são armazenados como elementos de curto prazo. Porém, ao final da fase de elaboração, a memória semântica processa o comando, converte os identificadores em elementos de longo prazo e adiciona um status para cada comando.
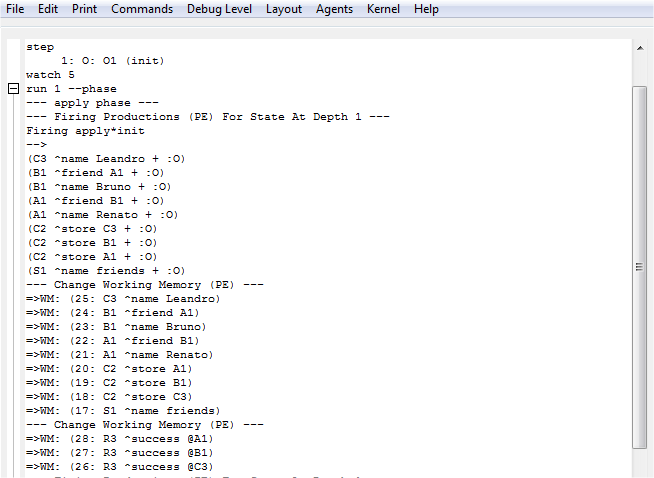
Figura 2.6: Execução do programa que usa o mecanismo de memória semântica.
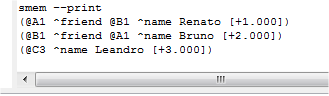
Figura 2.7: Conteúdo da memória semântica.

Figura 2.8: Execução do programa que usa o mecanismo de memória semântica - passo 2.

Figura 2.9: Conteúdo da memória semântica no passo 2.
Além de adicionar elementos para a memória semântica, o agente também pode recuperar conhecimento armazenado nessa memória. Para isso, um dos mecanismos que pode ser usado é chamado de recuperação não baseada em dica (non-cue-based retrieval), em que o agente requisita da memória semântica todos os argumentos de um identificador de longo prazo conhecido. A Figura 2.10 apresenta um exemplo de uso desse mecanismo.

Figura 2.10: Recuperação não baseada em dica.
Conforme pode ser observado na Figura 2.10, a sintaxe para recuperação não baseada em dica é <cmd> ^retrieve <lti>, lti é o identificador do elemento de longo prazo. Pode-se verificar também que as regras mostradas acima recuperam todas as informações sobre um dos dois @A1 amigos selecionados aleatoriamente e remove os argumentos do elemento friend que estão na memória de trabalho. Na Figura 2.11, mostra a seleção do operador ncb-retrievel e o conteúdo da memória semântica que foi impresso usando o comando print --depth 10 s2

Figura 2.11: Conteúdo da memória semântica após o uso de recuperação não baseada em dica.
Outra forma que o agente pode usar para recuperar conhecimento na memória semântica é através do mecanismo de recuperação baseada em dica (cue-based retrieval), em que o agente requisita da memória de trabalho todos os argumentos de um identificador de longo prazo não conhecido, que é descrito por um subconjunto de seus argumentos. A sintaxe desse mecanismo é <cmd> ^query <cue>, onde cue representa os identificadores de todos os argumentos desejados. Veja um exemplo de uso desse mecanismo na Figura 2.12.
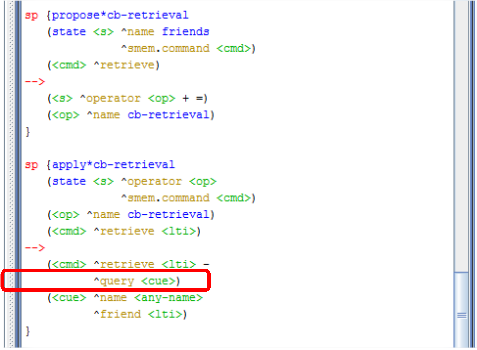
Figura 2.12: Recuperação baseada em dica.
Conforme pode ser observado na Figura 2.12, há um identificador que possui duas restrições: uma delas tem um argumento onde o atributo deve ser name e seu valor pode ser qualquer símbolo, enquanto a outra restrição tem um argumento onde o atributo deve ser friend e o valor deve ser o identificador de longo prazo recuperado pela aplicação do operador mostrada na Figura 2.5.
Ao imprimir o conteúdo da memória semântica após o uso do mecanismo de recuperação baseada em dica (Figura 2.13), observa-se que a memória semântica adiciona o identificador @A8 e todos os seus argumentos para a memória de trablho e indica que o status da operação como bem sucedida sucess.

Figura 2.13: Conteúdo da memória semântica após o uso de recuperação baseada em dica.
Exercício 3: memória episódica
A memória episódica é um mecanismo do Soar que automaticamente captura, armazena e indexa temporariamente o estado do agente e fornece uma interface de conteúdo endereçavel para a recuperação do conteúdo autobiográfico de experiências anteriores do agente.
Um exemplo de uso da memória episódica pode ser visto pelo seguinte código que pode ser executado no Soar Debugger:
epmem --set trigger dc epmem --set learning on watch --epmem
O conhecimento na memória episódica é criado automaticamente. Por padrão, ela armazena novos episódios sempre que um elemento é adicionado para a memória de trabalho e que tem um output-link como seu identificador. Porém, ela também suporta o armazenamento de episódios a cada novo ciclo de decisão, mas, para isso, é ncessário usar o comando da primeira linha do código apresentado acima.
Outro ponto importante é que a memória episódica, por padrão, é desativada. Então, para usá-la, ela deve ser ativada usando o comando da segunda linha do código apresentado acima. A terceira linha do código é usada para visualizar novos episódios armazenados na memória episódica. Então, ao executar o código acima no Soar Debugger e clicar no botão Step duas vezes, verifica-se que um novo episódio é criado contendo o índice 1, conforme é mostrado na Figura 3.1. Isso mostra que a arquitetura criou o episódio automaticamente. A Figura 3.1 também mostra conteúdo da memória episódica que foi impresso usando-se o comando epmem --print id, onde o id é o índice do episódio.
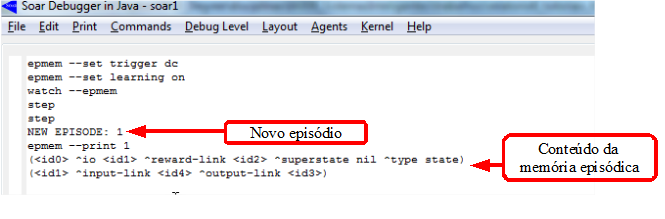
Figura 3.1: Comandos para a manipulação da memória episódica.
Assim como na memória semântica, o conteúdo da memória episódica pode ser visualizado graficamente. Para isso basta exportar seu conteúdo usando o comando command-to-file smem.gv smem --viz, onde smem é o nome do arquivo e pode ser trocado por qualquer outro nome. Depois de exportar, pode-se usar o programa Graphviz (http://graphviz.org) para visualizar o arquivo, conforme mostra a Figura 3.2.
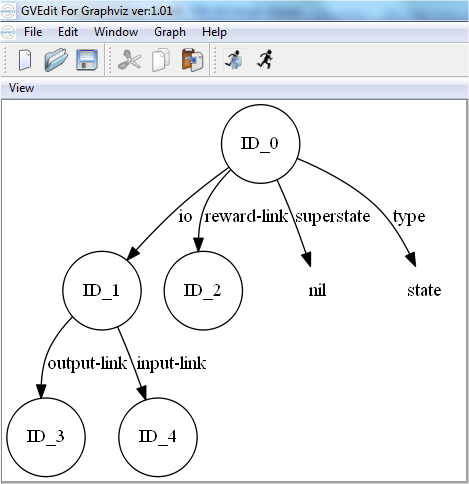
Figura 3.2: Visualização gráfica do conteúdo da memória episódica.
Para um agente conseguir interagir com a memória semântica ele usa estruturas uma estrutura especial, a epmem link. Essa estrutura é criada automaticamente pelo Soar na memória de trabalho e possui a seguinte subestrutura: ^command, que é usado para o agente iniciar as ações, e ^result, que é usado para obter um feedback da memória episódica. Para visualizar essa estrutura, pode-se usar o comando print --depth 10 <s>, conforme mostra a Figura 3.3, onde as estruturas em destaque, representam as estruturas gerais que formam a memória de trabalho e que podem ser usadas para a iteração com a memória semântica.
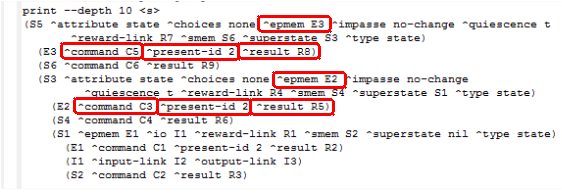
Figura 3.3: Estrutura epmem link.
Outra ação que pode ser realizada pelo agente é a recuperação do conhecimento armazenado na memória episódica. Para isso, pode ser usado o mecanismo de recuperação baseada em dica (cue-based retrieval), em que o agente requisita da memória episódica um episódio que mais se aproxima de uma dica de elementos da memória de trabalhos. A sintaxe desse mecanismo é <cmd> ^query <cue>, onde cue é o identificador da dica.
Os episódio são armazenados com base nos elementos folha da memória de trabalho na dica. Um elemento folha é satisfeito em relação ao um determinado episódio se existir uma sequência de elementos a partir da raiz até aquela folha, onde os elementos da memória de trabalho intermediários são os elementos que compôem a dica. Pzra exemplificar o uso de mecanismo de aprendizagem foram criadas as regras apresentadas na Figura 3.4.
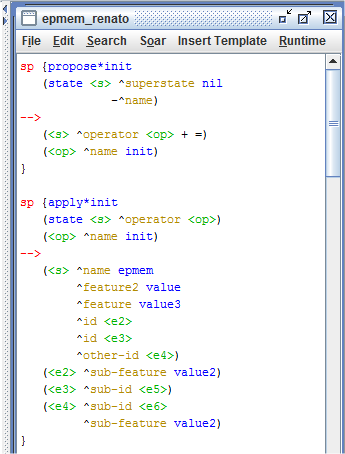
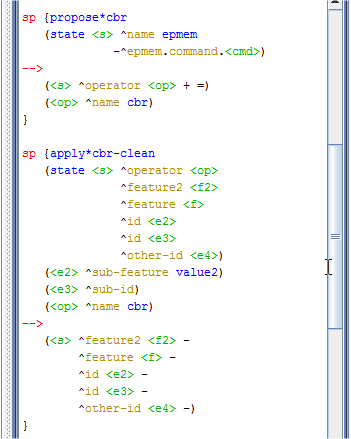

Figura 3.4: Regras que usam o mecanismo de memória episódica.
Além do código apresentado acima, no arquivo _firstload.soar do projeto criado no Visual Soar, foram inseridos os comandos mostrados no início desse exercício que são necessários para que se use o mecanismo de memória episódica. Depois de abrir, no Soar Debugger, o programa que contém as regras apresentadas na Figura 3.4, clicou-se no botão Step, seguido pelo botão Run 1 -p. Depois foi usado o comando print --depth 10 s1 para imprimir o conteúdo da memória de trabalho, conforme mostra a Figura 3.5.

Figura 3.5: Conteúdo da memória de trabalho - passo 1.
Depois de imprimir o conteúdo apresentado na Figura 3.5, clicou-se novamente no botão Step. Então, conforme mostra a Figura 3.6, o episódio 1 foi armazenado na memória apisódica. Então, clicou-se no botão Run 1 -p para que o operador cbr fosse aplicado e novamente usou-se o comando print --depth 10 s1 para verificar o conteúdo atualizado da memória de trabalho, conforme é mostrado na Figura na Figura 3.6.
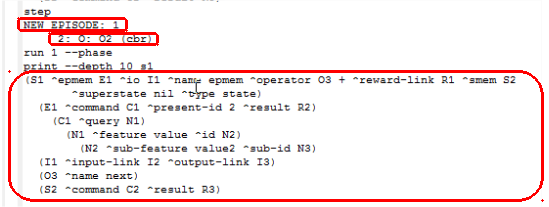
Figura 3.6: Conteúdo da memória de trabalho - passo 2.
O próximo passo foi clicar no botão Run 1 -p novamente, o que fez com que o episódio 2 fosse armazenado na memória episódica e a recuperação baseada em dica fosse processada, conforme mostra a Figura 3.7.

Figura 3.7: Conteúdo da memória de trabalho - passo 3.
A primeira linha do texto destacado na Figura 3.7 indica que a cardinalidade do conjunto de elementos folhas satisfeitos foi 2 e portanto o episódio tem pontuação 2. Porém, como a pontuação não foi a maior, pois poderia ter atingido três, ou seja, todas as folhas poderiam ter sido satisfeitas, então os atributos perfect e graph-match ficaram com valor false. Não apareceu nem um texto relacionado ao episódio 2 porque ele foi desconsiderado, uma vez que nenhum elemento folha foi satisfeito.
Outra forma que pode ser usada pelo agente para acessar os apisódios da memória episódica é através do episódio que veio antes ou depois do último episódio. A sintaxe desse mecanismo é <cmd> ^previous <id> e <cmd> ^next <id>, onde id é o identificador. Veja um exemplo de uso desse mecanismo na Figura 3.8.

Figura 3.8: Nova maneira de acessar os episódios.
Depois de adicionar as regras apresentadas acima ao programa apresentado na Figura 3.4, e abri-lo novamente no Soar Debugger, clicou-se no botão Step até aplicar o operador next. Após isso, imprimiu-se o conteúdo da memória episódica usando o comando print --depth 10 e1. Veja na Figura 3.9.
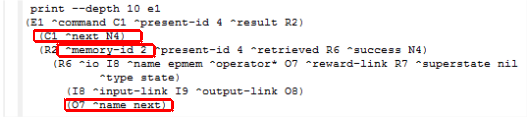
Figura 3.9: Conteúdo da memória de trabalho - passo 4.
Diante do que é apresentado na Figura 3.9, verifica-se que o comando query foi substituído pelo comando next e que o episódio 2 foi recuperado com sucesso. .
Theme by Danetsoft and Danang Probo Sayekti inspired by Maksimer